PDTSC 2.0
Prague Dependency Treebank of Spoken Czech 2.0
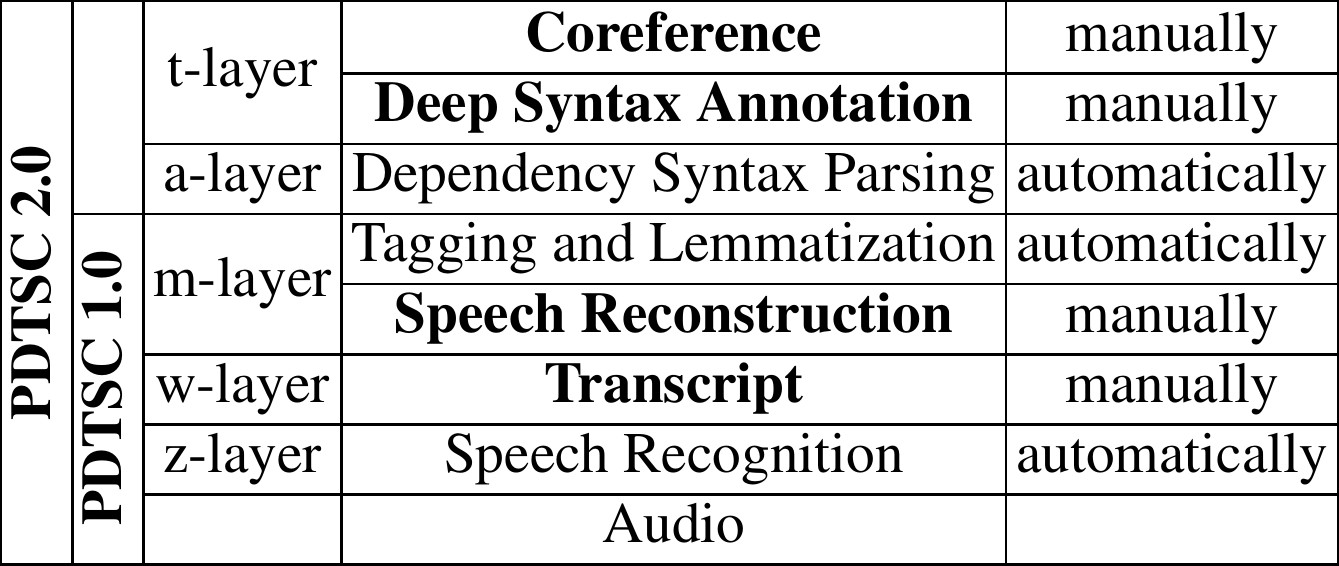
The Prague Dependency Treebank of Spoken Czech 2.0 is a corpus of spoken language, consisting of 742,316 tokens and 73,835 sentences, representing 7,324 minutes (over 120 hours) of spontaneous dialogs. The dialogs have been recorded, transcribed and edited in several interlinked layers: audio recordings, automatic (z-layer) and manual transcripts (w-layer) and manually reconstructed text (m-layer). These layers were part of the first version of the corpus (PDTSC 1.0). Version 2.0 is extended by an automatic dependency parser at the analytical (a-layer) and by the manual annotation of “deep” syntax at the tectogrammatical layer (t-layer), which contains semantic roles and relations as well as annotation of coreference. Table 1 shows the inclusion and status of layers of annotation in both versions of the corpus.
Data
The corpus consists of two types of dialogs. First we used the Czech portion of the Malach project corpus. The Malach corpus consists of lightly moderated dialogs (testimonies) with Holocaust survivors, originally recorded for the Shoa memory project by the Shoa Visual History Foundation. The dialogs usually start with shorter turns but continue as longer monologues by the survivors, often showing emotion, disfluencies caused by recollecting interviewee’s distant memories, etc.
The second portion of the corpus consists of dialogs that were recorded within the Companions project. The domain is reminiscing about personal photograph collections. The goal of this project was to create virtual companions that would be able to have a natural conversation with humans. The corpus was completely recorded in the Wizard-of-Oz setup; the interviewing speaker is an avatar on the computer screen, which is controlled by a human in a different room. The interviewee is a user of a system that is designed to discuss his photographs with him. The user does not know that the avatar is controlled by a human and believes it is real artificial intelligence he interacts with.
Layers of annotation
PDTSC 2.0 is a treebank from the family of PDT-style corpora developed in Prague. PDTSC differs from other PDT-style corpora mainly in the “spoken” part of the corpus. The layers stack starting at the external base layer with audio files (in the Vorbis format). The bottom layer of the corpus (z-layer) contains automatic speech recognition output synchronized to audio. The next layer, w-layer, contains manual transcript of the audio, i.e. everything the speaker has said including all slips of the tongue as well as non-speech events like coughing, laugh, etc. W-layer is synchronized to the automatic transcript and through it thus to the original audio. The subsequent m-layer contains a manually “reconstructed”, i.e. edited, grammatically corrected version of the transcript, including punctuation and assumed sentence boundaries. The reconstructed tokens are automatically morphologically tagged and lemmatized. From this point on, annotation on the upper layers is the same as in the other PDT-style corpora. The dependency syntax layer (a-layer) is parsed automatically, while the “deep” syntax layer (t-layer) is annotated manually. There is a one-to-one correspondence between the tokens at the m-layer and the nodes at the a-layer. The syntactic dependencies are provided with dependency relations (e.g., subject or adverbial). The t-layer, which is also a tree-shaped graph (with content words only), is the highest and most complex linguistic representation that combines syntax and semantics in the form of semantic labeling, coreference annotation and argument structure description based on a valency lexicon.
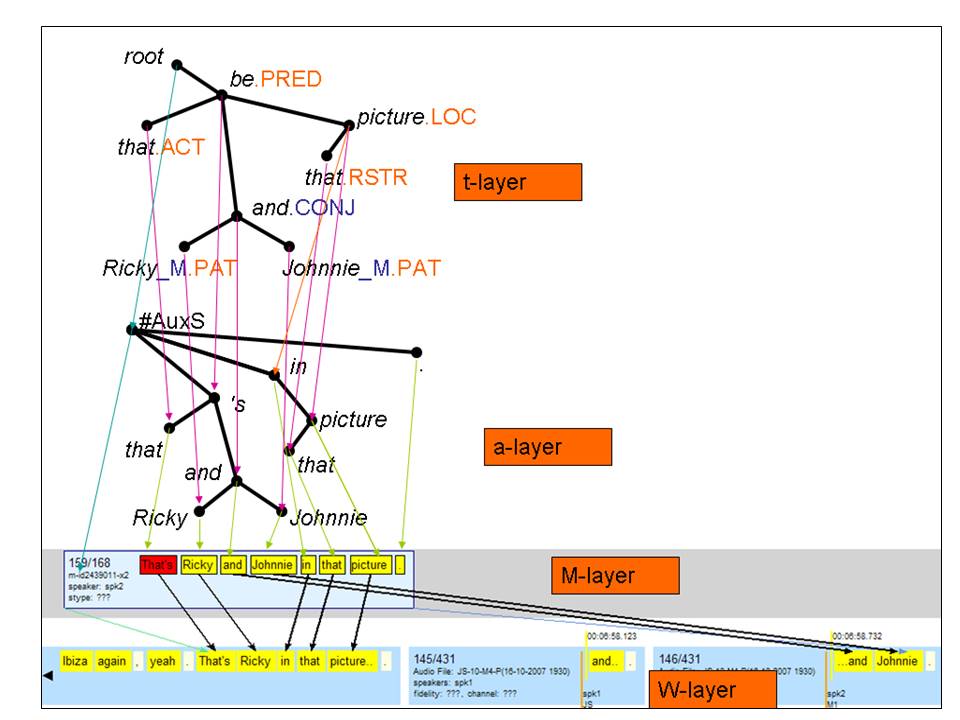
In order not to lose any piece of the original information, tokens (nodes) on a lower layer are explicitly referenced from the corresponding closest (immediately higher) layer. This allows the morphological, syntactic and semantic annotation to be deterministically and fully mapped back to the transcript and audio. It brings new possibilities for modeling morphology, syntax and semantics in spoken language – either at the original transcript with mapped annotation, or at the new layer after (automatic) editing.
Publications
Hajič Jan, Cinková Silvie, Mikulová Marie, Pajas Petr, Ptáček Jan, Toman Josef, Urešová Zdeňka: PDTSL: An Annotated Resource For Speech Reconstruction. In: Proceedings of the 2008 IEEE Workshop on Spoken Language Technology, IEEE, Goa, India, ISBN 978-1-4244-3472-5, 2008. (pdf)
Mikulová Marie: Speech reconstruction guidelines for Czech data. Translation of manual in Czech: Marie Mikulová: Rekonstrukce standardizovaného textu z mluvené řeči. Manuál pro anotátory. Institute of Formal and Applied Linguistics, Charles University, Prague, Czechia, 2008. (pdf)
Mikulová Marie: Rekonstrukce standardizovaného textu z mluvené řeči v Pražském závislostním korpusu mluvené češtiny. Manuál pro anotátory. Tech. report no. TR-2008-38, Institute of Formal and Applied Linguistics, Charles University, Prague, Czechia, ISSN 1214-5521, 2008. (pdf)
Mikulová Marie, Mírovský Jiří, Nedoluzhko Anna, Pajas Petr, Štěpánek Jan, Hajič Jan: PDTSC 2.0 - Spoken Corpus with Rich Multi-layer Structural Annotation. In: Lecture Notes in Computer Science, 20th International Conference, TSD 2017 Prague, Czech Republic, No. 10415, Springer International Publishing, Cham / Heidelberg / New York / Dordrecht / London, ISBN 978-3-319-64205-5, ISSN 0302-9743, pp. 129-137, 2017. (pdf)
Mikulová Marie, Hoffmannová Jana: Korpusy mluvené češtiny a možnosti jejich využití pro poznání rozdílných "světů" mluvenosti a psanosti. In: Korpusová lingvistika Praha 2011. 2 Výzkum a výstavba korpusu, Lidové noviny, Prague, Czechia, ISBN 978-80-7422-115-6, pp. 78-92, 2011.