



, konkrétně s daty pocházejícími z novin Wall Street Journal. Chtěli jsme si to udělat po svém (závislostně) a chtěli jsme to paralelně (angličtina i čeština).")


Obsah
Typy uzlů
V následujícím textu popisujeme hlavní principy tektogramatické reprezentace platné pro angličtinu, užíváme anglické příklady. Rysy, které nejsou jazykově specifické pro angličtinu, však platí i pro českou tektogramatickou reprezentaci.
Na tektogramatické rovině rozlišujeme osm typů uzlů. Jednotlivé typy uzlů se liší především svou funkcí a v důsledku toho též svou vnitřní strukturou (hodnotami atributů). Typ uzlu je jedním z atributů uzlu (nodetype). Rozlišujeme tyto typy uzlů:
Obrázek 1
- komplexní uzly
- atomické uzly
- kvazikomplexní uzly
- kořeny souřadných struktur
- uzly pro frazeologické výrazy
- uzly pro cizojazyčné výrazy
- kořeny seznamových struktur
- technický kořen stromu
Komplexní uzly
Komplexní uzly reprezentují především autosémantická slova s jejich četnými gramatickými kategoriemi. Tyto kategorie (např. „číslo“, „čas“ nebo „slovní druh“) jsou reprezentovány tzv. gramatémy. Uzly jiných typů gramatémy nemají. Komplexní uzly označujeme jako „komplexní“, protože mají nejkomplexnější vnitřní strukturu. Komplexní uzly mají v atributu nodetype hodnotu complex.
Obrázek 2
Atomické uzly
Atomické uzly reprezentují negační částice (t-lemma #Neg), dále výrazy jako probably, fortunately a however, což jsou slova, která Quirk et al. nazývá „disjunkty“ a (v některých případech) „konjunkty“. Atomickým uzlům náleží typicky funktory ATT, CM, MOD, PREC, PARTL nebo RHEM a v atributu nodetype mají hodnotu atom.
Kvazikomplexní uzly
Kvazikomplexní uzly jsou uzly, které reprezentují interpunkci, pokud je reprezentována samostatným t-uzlem, ale nepředstavuje kořen souřadné struktury, a přidané uzly (is_generated="1") se zástupným t-lemmatem (např. #Cor). I každé interpunkční znaménko je reprezentováno specifickým zástupným t-lemmatem (např. #Bracket, #Comma). Tudíž platí, že kvazikomplexní uzly (nodetype=qcomplex) mají vždy zástupné t-lemma. Na druhou stranu, jak uvidíme dále, ne každý uzel, který má zástupné t-lemma, je kvazikomplexní uzel.
Obrázek 3
Kořeny souřadných struktur
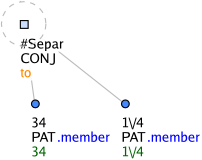
Kořeny souřadných struktur mají v atributu nodetype hodnotu coap. Jsou to uzly, které reprezentují souřadicí spojky a též interpunkční znaménka (např. čárka v apozici Martin, my best friend). Kořeny souřadných struktur reprezentují vždy nějaký výraz, který se vyskytuje v textu, jedinou výjimkou je přidaný uzel se zástupným t-lemmatem #Separ. Tento uzel se doplňuje v případě, že struktura je chápána jako souřadná, ale v textu není žádný výraz pro kořen této souřadné struktury. Tyto případy jsou však řídké. Typicky doplňujeme #Separ v případě složených číslovek (Obrázek 1).
Uzly pro frazeologické výrazy
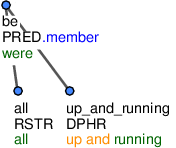
Frazémy jsou obvykle tvořeny více než jedním výrazem. Jednotlivé (další) části frazému nejsou strukturně analyzovány, ale jsou spojeny do jednoho uzlu, kterému je přidělen funktor DPHR (Obrázek 2). Všechny uzly s tímto funktorem mají nodetype=dphr.
Uzly pro cizojazyčné výrazy
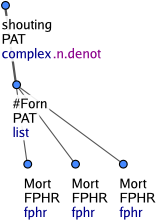
Cizojazyčné úseky textu nejsou strukturně analyzovány. Uzly reprezentující jednotlivé cizojazyčné výrazy mají funktor FPHR a v atributu nodetype mají hodnotu fphr. Viz Obrázek 3.
Obrázek 4
Kořeny seznamových struktur
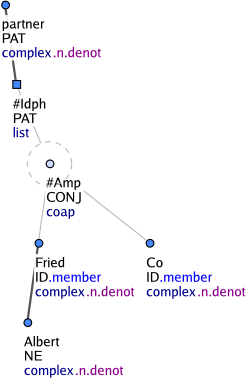
Obrázek 5
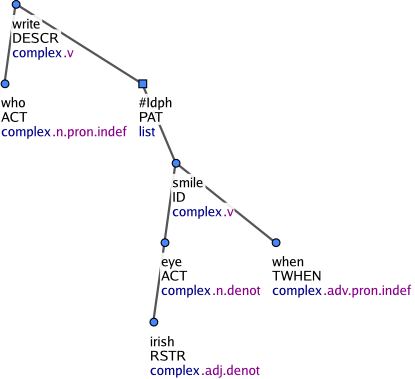
Na rozdíl od frazémů se cizojazyčné úseky textu, které se skládají z více výrazů, nespojují do jednoho uzlu. Struktura se však ani zde neanotuje. Každý výraz cizojazyčného textu je zachycen samostatným t-uzlem a tyto uzly jsou ve stromě uspořádány jako sesterské. Jejich společným řídícím uzlem je přidaný uzel se zástupným t-lemmatem #Forn. Tento uzel má v atributu nodetype hodnotu list. Uzly tohoto typu představují kořeny seznamových struktur. Mají buď zástupné t-lemma #Forn nebo #Idph. Na Obrázek 3 je víceslovný cizojazyčný výraz. Uzel se zástupným t-lemmatem #Forn je kořenem seznamové struktury zachycující cizojazyčný úsek textu. Uzel se zástupným t-lemmatem #Idph je kořenem seznamové struktury („identifikační struktury“) zachycující vlastní jméno nebo název, ale jen v případě, že toto vlastní jméno nebo název není uvozeno obecným rodovým jménem (např. novel, song) a je tvořeno souřadnou strukturou, předložkovou frází, adjektivem, adverbiem nebo slovesnou klauzí (Obrázek 4 a Obrázek 5). Efektivní potomek kořene identifikační struktury (tj. uzly typu coap jsou ignorovány) má funktor ID. Rozvití cizojazyčných a identifikačních výrazů závisí vždy na kořeni dané seznamové struktury, tedy na uzlu se zástupným t-lemmatem #Forn nebo #Idph (Obrázek 6).
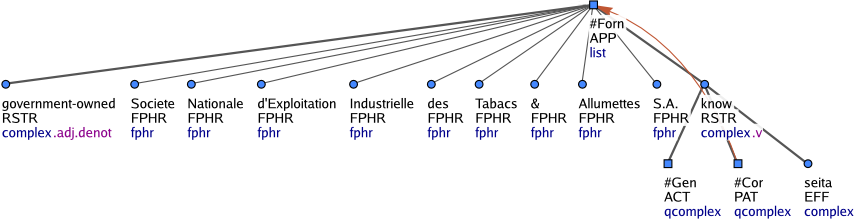
Obrázek 6
Technický kořen
Každý strom má jeden technický kořen, který má v atributu nodetype hodnotu root. U technického kořene je uložen jedinečný identifikátor daného stromu. Podobně jako na analytické rovině je v identifikátoru stromu zakódován název jazyka, název korpusu, název roviny a pořadové číslo věty. Obsahuje také atribut ord („pořadí“), jehož hodnota je vždy 0.