



, konkrétně s daty pocházejícími z novin Wall Street Journal. Chtěli jsme si to udělat po svém (závislostně) a chtěli jsme to paralelně (angličtina i čeština).")


Úvod
Texty
Pražský česko-anglický závislostní korpus 2.0 (PCEDT 2.0) nahrazuje starší verzi Pražského závislostního korpusu 1.0 (LDC2004T25). Je to manuálně parsovaný česko-anglický paralelní korpus o velikosti přes 1,2 miliónu tokenů v téměř padesáti tisících vět v každé jazykové paralele.
Data
Anglická paralela obsahuje celý Penn Treebank, sekci s texty z Wall Street Journalu (LDC99T42). Česká paralela sestává z českých překladů všech textů z Penn Treebanku, WSJ sekce. Korpus je zarovnán na věty. V tomto vydání je zahrnuto i automatické zarovnání na úrovni uzlů jednotlivých rovin. Zachovali jsme uspořádání souborů stejné jako v původním Penn Treebanku (25 sekcí, z nichž každá obsahuje až sto souborů). V korpusu se nacházejí pouze dokumenty, které mají původní penntreebankovou anotaci morfologických značek a strukturální syntaktickou anotaci (závorkování). Těchto dokumentů je 2312.
Každá z paralel je opatřena detailní ruční lingvistickou anotací ve stylu PDT 2.0 (LDC2006T01, Prague Dependency Treebank 2.0). Toto jsou hlavní znaky anotačního schématu PDT 2.0:
- závislostní struktura autosémantických slov a souřadných struktur (synsémantická slova jsou s autosémantickými asociována jako hodnoty atributů)
- sémantický popis autosémantických slov a typů souřadných struktur
- valence, včetně valenčního lexikonu pro každý jazyk
- rekonstrukce elips a znázornění anaforických vztahů napříč textem.
Tento styl anotace se nazývá tektogramatická anotace a v korpusu tvoří tektogramatickou rovinu. Podrobnosti viz níže a dokumentace.
Anotace české paralely
Věty českého překladu byly automaticky opatřeny morfologickými značkami a zparsovány do povrchově syntaktických závislostních stromů ve stylu PDT 2.0. Toto anotační schéma se někdy nazývá analytická anotace; v korpusu tvoří tzv. analytickou rovinu. Nad touto automatickou anotací byla vybudována samostatná manuálně anotovaná tektogramatická rovina (rovina hloubkové syntaxe). Na analytické rovině byl manuálně anotován vzorek dvou tisíc vět.
Anotace anglické paralely
Výsledná manuální tektogramatická anotace byla vybudována nad původní složkovou anotací Penn Treebanku automaticky transformovanou do povrchově syntaktických závislostních (analytických) stromů za použití dodatečné lingvistické informace z dalších zdrojů:
- PropBank (LDC2004T14)
- VerbNet
- NomBank (LDC2008T23)
- flat noun phrase structures (převzato z volně přístupných webů - D. Vadas a J.R. Curran)
U každé věty jsou v tomto korpusu zachovány původní složkové stromy, ke kterým vedou odkazy z analytické a tektogramatické anotace.
Roviny anotace
Anotace ve stylu PDT 2.0 sestává z několika rovin:
- w-rovina
- m-rovina
- a-rovina
- t-rovina
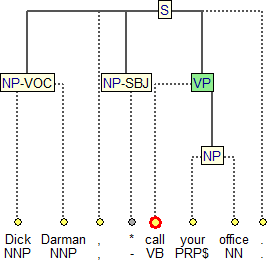
Obrázek 1
Anglická paralela obsahuje původní anotaci Penn Treebanku, kterou nazýváme p-rovina (složková rovina). Obrázek 1 ukazuje vizualizaci složkového stromu v programu TrEd, editoru a browseru PCEDT 2.0.
w-rovina
Spodní rovina ("slovní" rovina) je tokenizovaný prostý text, v němž každý token dostal svou jedinečnou identifikaci (id). Tato rovina je plně integrována do bezprostředně sousedící vyšší roviny, m-roviny.
m-rovina
m-rovina je morfologická rovina. Tokeny a jejich id jsou zde automaticky morfologicky označkovány a lemmatizovány. Od této chvíle můžeme tokeny považovat za lineárně uspořádané uzly, které mají každý své jedinečné id, morfologický tag a lemma. V korpusu není m-rovina zobrazena samostatně, ale jako součást analytické roviny, jež přináší reprezentaci syntaktických závislostí a jejich klasifikaci.
a-rovina
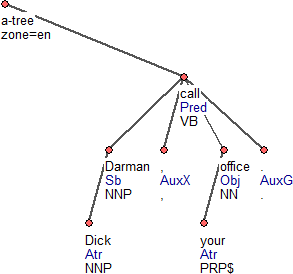
Obrázek 2
A-rovina (analytická rovina) reprezentuje povrchově syntaktickou analýzu věty (parse). Syntaktické závislosti jsou označeny nálepkami, které nesou obvyklou syntaktickou informaci, například "subjekt", "přívlastek", "jmenný predikát". Více detailů viz podrobná specifikace české manuální analytické anotace a stručná specifikace anglické automatické analytické anotace. Obrázek 2 ilustruje analytickou reprezentaci věty v TrEdu.
t-rovina
Nejvyšší - tektogramatická - rovina je lingvistickou reprezentací, která kombinuje syntax a, do jisté míry, sémantiku, ve formě sémantického popisu (nálepek), interpretace anafory a valenčního popisu vycházejícího z valenčního slovníku. Tato reprezentace se opírá o teorii Funkčního Generativního Popisu (Sgall, Hajičová, Panevová, 1986). Původní tektogramatická reprezentace jazyka v teoretických pracích šedesátých let dvacátého století byla vyvíjena zejména s ohledem na pravidlové generování textu. Náš anotovaný korpus naplňuje základní myšlenky tohoto formálního popisu jazyka, ale zároveň je postaven tak, aby sloužil jako trénovací data pro statistické strojové učení, a hodí se jak pro generování, tak pro analýzu textu. Tektogramatická anotace v PCEDT 2.0 je ve srovnání s PDT 2.0 poněkud zjednodušená. Například ještě neobsahuje informace o aktuálním větném členění ani pro jeden jazyk.
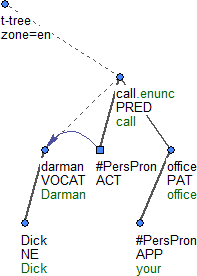
Obrázek 3
Více detailů viz podrobná specifikace české tektogramatické anotace a stručná specifikace anglické tektogramatické anotace. Obrázek 3 ukazuje tektogramatickou reprezentaci věty vizualizovanou v programu TrEd.
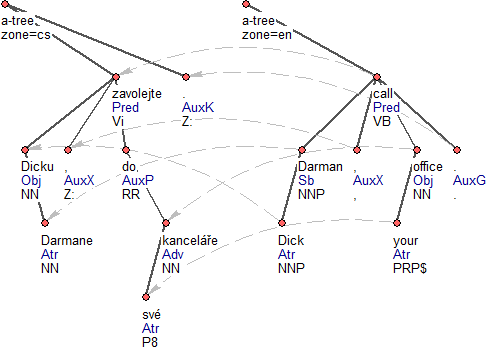
Obrázek 4
Zarovnání
PCEDT 2.0 je paralelní korpus automaticky zarovnaný na slova. Zarovnání vede ve formě odkazů z anglické paralely do české, pro každou rovinu zvlášť. Roviny anglické anotace obsahují informaci o zarovnání ve formě odkazů z anglických uzlů k jejich odpovídajícím českým uzlům.
Obrázek 4 a Obrázek 5 prezentují zarovnání na jednotlivých rovinách anotace.
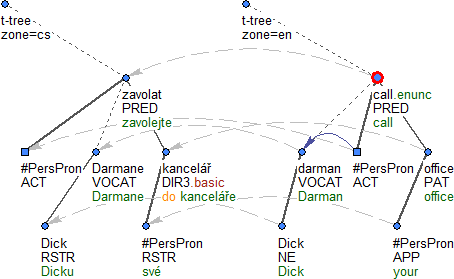
Obrázek 5