



, konkrétně s daty pocházejícími z novin Wall Street Journal. Chtěli jsme si to udělat po svém (závislostně) a chtěli jsme to paralelně (angličtina i čeština).")


Obsah
Valence
V následujícím textu popisujeme hlavní principy tektogramatické reprezentace platné pro angličtinu, užíváme anglické příklady. Rysy, které nejsou jazykově specifické pro angličtinu, však platí i pro českou tektogramatickou reprezentaci.
Valence (argumentová struktura) v PCEDT 2.0 je založena na valenční teorii Funkčního generativního popisu (FGP). Teorie se zaměřuje hlavně na slovesa. Hlavní část této sekce se proto bude věnovat slovesné valenci, většinu závěrů lze ale aplikovat i na další slovní druhy. Specifické rysy valence substantiv a adjektiv budou popsány zvlášť.
Obligatorní vs. neobligatorní doplnění
Rozlišujeme čtyři typy doplnění: obligatorní aktant, fakultativní aktant, obligatorní volné doplnění a volné doplnění. Hranice mezi aktanty (též participanty, argumenty) a volnými doplněními (též adjunkty) není identická s hranicí obligatornosti. Obligatornost je určována na základě tzv. dialogového testu. Dialogový test nám tedy pomáhá rozlišit, které doplnění je obligatorní a které nikoliv. Dialogový test je založen na rozdílu mezi otázkami po něčem, co má být mluvčímu známo, protože to vyplývá z významu užitého slovesa, a mezi otázkami po doplňující informaci, která ve významu užitého slovesa nutně obsažena není. Na otázku po sémanticky obligatorním doplnění konkrétního slovesa nemůže mluvčí, který toto sloveso užil, odpovědět: Nevím. Srovnej následující dialogy:
- A: Když to viděl, koupil to.
- B: Kdo?
- A: *Nevím.
Nákupčí musí být mluvčímu známý, jinak by dialog nebyl smysluplný. Podobné je to s otázkou po předmětu koupě:
- A: Když to viděl, koupil to.
- B: Co?
- A: *Nevím.
Naproti tomu otázky Komu? a Od koho? jsou otázky, na které mluvčí nemusí znát odpověď:
- A: Když to viděl, koupil to.
- B: Komu/od koho?
- A: Nevím.
Obligatorní doplnění jsou doplnění, která musí být mluvčímu známá, jinak by dialog nebyl smysluplný.
Aktant vs. volné doplnění
Pro rozdělení slovesných doplnění na aktanty a volná doplnění bylo využito především těchto měřítek:
- Může daný typ doplnění rozvíjet jedno sloveso (výskyt) více než jednou, nebo nejvýše jednou?
- Může daný typ doplnění rozvíjet jakékoli sloveso, nebo jeho řídící slovesa tvoří omezenou skupinu a mohou být vyjmenována?
Pokud se doplnění jako rozvití nějakého konkrétního slovesa vyskytuje nejvýše jednou (vyjma případů souřadnosti) a rozvíjí pouze určitou omezenou skupinu sloves, která může být vyjmenována, jedná se o aktant.
Pokud doplnění může rozvíjet jakékoli sloveso a jedno konkrétní sloveso může rozvíjet i více než jednou, jedná se o volné doplnění. Například prostorová a časová určení jsou typická volná doplnění, neboť prakticky všechny děje mohou být popsány jako realizované v nějakém čase a prostoru.
Druhy aktantů: ACT, PAT, ADDR, ORIG a EFF
Všechny aktanty a relevantní volná doplnění jsou pro daný význam slovesa obsažena ve valenčním rámci ve valenčním slovníku. Valenční rámce v českém valenčním slovníku, v PDT-Vallexu, obsahují pouze aktanty (obligatorní a fakultativní) a obligatorní volná doplnění. Anglický valenční slovník (Engvallex) zachycuje i typická volná doplnění. První verze Engvallexu byla totiž získána poloautomatickým převodem z jedné dřívější verze slovníku PropBank, a ačkoliv některá doplnění obsažená v PropBanku nelze podle teorie FGP hodnotit jako aktanty ani jako obligatorní volná doplnění, ponechali jsme tato doplnění ve valenčních rámcích, abychom informaci získanou z PropBanku neztratili. Všechna nepovinná doplnění jsou ve valenčním rámci označena symbolem otazníku.
Rozlišujeme pět slovesných aktantů. Jsou zachyceny pomocí funktorů ACT (Aktor), PAT (Patient), ADDR (Adresát), ORIG (Původ) a EFF (Efekt). Při určování aktantů užíváme kritéria primárně syntaktická (pokud jde o určení aktoru (ACT) a patientu (PAT)) a kritéria sémantická (pokud má sloveso více než dva aktanty). Pokud sloveso otevírá pouze jednu valenční pozici pro aktant, je tímto aktantem vždy ACT bez ohledu na sémantiku. Například v kauzativní alternaci slovesa boil má způsobitel děje funktor ACT a substance, která se vaří, má funktor PAT. V inchoativní alternaci, substance, která se vaří, má funktor ACT, navzdory tomu, že sémanticky se nejedná o agenta. Na rozdíl od PropBanku ve valenčních slovnících PDT nejsou nijak propojeny odpovídající si aktanty se stejnými tematickými rolemi v různých slovesných alternacích (což většinou znamená v různých valenčních rámcích). Pokud sloveso otevírá dvě valenční pozice pro aktant, logický subjekt predikátu má funktor ACT a druhý aktant je vždy PAT. PAT je typicky přímý objekt aktivního slovesa, ale (systematicky) také doplnění sponového slovesa. Například ve větě Peter is my friend, Peter (jakožto jedinec, který je klasifikován) má funktor ACT a friend (jakožto kategorie, do které Peter náleží) je PAT.
Pokud sloveso otevírá tři a více valenčních pozic, funktory daleko více reflektují sémantické role aktantů. Dva aktanty jsou vždy ACT a PAT. Třetí (čtvrtý, pátý) aktant je označen jedním z funktorů ORIG, ADDR a EFF. Například sloveso sell má v jednom ze svých významů obligatorní ACT (prodejce), PAT (prodávaná věc) a fakultativní aktant ADDR (nákupčí) a EFF (cena, za kterou se prodává). Sekundární predikace u sloves se třemi aktanty (They elected him president) mají vždy funktor EFF. Přiřazení těchto velmi hrubě sémanticky odlišených funktorů je ve většině základních významů sloves velice intuitivní, zejména pokud je určitá valenční pozice typicky obsazována „lidmi“ a další pozice pak „neživými entitami“. Srov.:
- They.ACT gave him.ADDR a book.PAT
- They.ACT are bundling their services.PAT into packages.EFF and target them to small segments of the population.
Najdou se ovšem i slovesa, slovesné významy, u kterých se zdá, že žádný ze sémantických funktorů není optimální. V takovém případě je rozhodnutí o funktoru arbitrární a je ponecháno na lexikografovi. Bylo přijato pouze několik obecných konvencí, například, že reciproční slovesa se třemi valenčními pozicemi (someone blends something with something) mají obvykle následující aktanty: ACT, PAT, ADDR. Pokud přiřazení funktorů není přímočaré, jednotlivá individuální rozhodnutí se mohou lišit, přestože dvě slovesa v určitém významu by měla být popsána stejnou sadou funktorů. Rozdíly se typicky vyskytují tam, kde se lexikograf rozhoduje, zda vytvořit valenční rámec ACT, PAT, ADDR nebo ACT, PAT, EFF. Pořadí slov je pro vytvoření valenčního rámce irelevantní. Srov. následující věty (které jsou jako příklady uvedené v Engvallexu):
- They.ACT encase the concrete columns.PAT with steel.EFF
- John.ACT surrounded the castle.ADDR with his toy soldiers.PAT.
Valence substantiv a adjektiv
Pro doplnění substantiv byly zavedeny tři specifické funktory: APP, MAT a AUTH. Funktor APP ("přináležitost") lze chápat jako vztah "vlastnictví" v tom nejširším slova smyslu: John's pen, my mother, New York's trendiest club, America's mountains atp. Pokud však má substantivum dějový význam, jeho posesivní rozvití nesou funktory odpovídající slovesnému rámci. Například: my.ACT meeting with the other team.PAT.
Funktor MAT se přiřazuje substantivům, která rozvíjejí substantivum s významem kontejneru, například: a sack of potatoes.MAT, millions of people.MAT. Autor artefaktů má funktor AUTH.
Doplnění substantiva, které nelze popsat funktory APP, MAT nebo jiným sémanticky vyhraněným funktorem (jako například a letter from China.DIR1, a letter from my brother.ORIG, yesterday's.TWHEN meeting, annual.THO event), má obvykle funktor PAT: the portrait of the president.PAT. Adjektivní rozvití nejsou nikdy hodnocena jako aktanty a typicky nesou funktor RSTR (restriktivní přívlastek) nebo DESCR (deskriptivní přívlastek). Aktanty substantiv nejsou nikdy považovány za obligatorní.
Anotátoři se vždy snažili interpretovat složité jmenné fráze v co největší míře pomocí sémanticky vyhraněných funktorů. Taková anotace je však pochopitelně velmi nekonzistentní. Neexistuje žádný slovník substantiv (nějaký protějšek NomBanku) pro anglickou část PCEDT 2.0. Anglická substantiva a jejich valence není doposud zachycena ve valenčním slovníku.
Infinitiv, který rozvíjí řadu adjektiv (např. eager to please), má funktor PAT.
Valenční slovníky
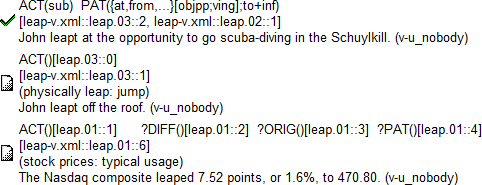
Obrázek 1: Engvallex valency frame
Český valenční slovník PDT-Vallex je podrobně popsaný v české dokumentaci. Anglický valenční slovník Engvallex má velmi podobnou strukturu, ale navíc obsahuje mapování na současnou verzi PropBanku (vydání na OntoNotes 4.0). Slovesné heslo leap v Engvallexu na Obrázek 1 obsahuje tři valenční rámce. Řádek pod každým rámcem představuje mapování rámce v Engvallexu (frame) na příslušný rámec v PropBanku (frameset). Původně bylo mapování udržováno manuálně. Toto mapování se však rozpadlo po poslední revizi PropBanku, která zásadně změnila definici framesetu. Obnovené mapování jsme zpětně získali z anotovaných dat. Poslední verze PropBanku sloučila všechny realizace syntakticko-sémantických alternací (diatezí) do společného framesetu. Naproti tomu Engvallex tyto diateze žádným způsobem nezohledňuje a každé realizaci diateze přiděluje vlastní rámec. V aktuálních verzích obou slovníků tedy nejtypičtěji nastává případ, že se několik rámců Engvallexu mapuje na jeden společný frameset. V tomto případě řádek zobrazující mapování obsahuje ID daného framesetu v PropBanku. U některých rámců v Engvallexu tento řádek chybí. To nastává, když byl daný rámec použit ve větách, které dosud nebyly anotovány v korpusu PropBank. (Engvallex pokrývá všechny věty v PTB-WSJ, zatímco PropBank jen asi ze dvou třetin. Zato ale PropBank obsahuje anotaci i jiných korpusů než PTB-WSJ.) K mapování jednoho valenčního rámce Engvallexu na několik framesetů v PropBanku ovšem nastává také. Pokud věty PTB-WSJ anotované jedním engvallexovým rámcem mají v PropBanku anotaci různými framesety, mapovací řádek je zobrazuje v sestupném pořadí podle frekvence a u každého udává počet vět, které daným framesetem byly anotovány.
Mapování Engvallexu na PropBank
Před radikální revizí PropBanku ve vydání OntoNotes 4.0 byly jednotlivé členy valenčního rámce v Engvallexu namapovány na odpovídající členy odpovídajícího framesetu v PropBanku. Nicméně po poslední revizi PropBanku většina propojení přestala platit. Aktuální mapování jsme se rozhodli získat z anotovaných dat PropBanku a PEDT 2.0. Nebylo překvapivé, že mapování mezi rámci a framesety, a obzvlášť mapování jednotlivých členů rámců nebylo vždy 1:1. Informaci o vzájemném mapování obou lexikálních zdrojů uchováváme ve třech souborech (viz section Documentation). Soubor eng_pb_links.txt obsahuje pouze nejfrekventovanější mapování. Soubor eng_pb_links_for_all_rolesets.txt obsahuje veškeré mapování, ale neobsahuje pointery do dat. Soubor eng_pb_links_with_ids.txt obsahuje kompletní informaci o mapování včetně pointerů na pozice v korpusu, kde se mapování vyskytlo (odkaz na ID příslušného p-uzlu).
Méně podrobný (tudíž přehlednější) soubor s informací o mapování jsme integrovali do Engvallexu, abychom usnadnili jeho prohlížení. Soubor s podrobnou informací (mapování na všechny framesety a jejich frekvence) je natolik obsáhlý, že by podstatně znepřehlednil navigaci ve slovníku.

Obrázek 2: Engvallex to PropBank mapping in the Engvallex editor
Mapování jednotlivých slovesných doplnění je naznačeno, pouze když se mapuje engvallexový participant nebo obligatorní volné doplnění na doplnění, které PropBank klasifikuje jako argument (značka začínající ARG-) vyjmenované v definici framesetu. Na Obrázek 2 je sloveso swim rozděleno do tří rámců. Dva z nich jsou namapovány na framesety v PropBanku. Chybějící mapování v nejfrekventovaněji mapovaném framesetu má dva možné důvody: buď tento engvallexový rámec nebyl přiřazen žádné větě v celém korpusu, nebo věta, které byl tento rámec v PCEDT 2.0 přiřazen, ještě nebyla anotována v PropBanku (na rozdíl od PCEDT 2.0 anotace PropBanku nepokrývá celý Penn Treebank). Když je informace o mapování přítomná, je uložena na samostatném řádku pod seznamem valenčních doplnění, která definují příslušný rámec, například [swim-v.xml::swim.01::1]. Tento popis znamená, že tento rámec se mapuje na frameset swim.01 a že se tak stalo jedenkrát v celém korpusu. Třetí engvallexový rámec se mapuje na frameset swim.01 v celém korpusu třikrát. Třetí engvallexový rámec se mapuje na frameset swim.01 dvakrát. Když se na sebe mapují engvallexový participant/povinné volné doplnění a propbankový argument, mapování je uvedeno v hranaté závorce za názvem doplnění. Poslední číslice opět znamená frekvenci mapování mezi těmito dvěma členy. Z uvedeného příkladu je vidět, že Actor slovesa swim ve druhém rámci se mapuje na člen označený ve framesetu swim.01 jako Arg0 pouze jednou.
Informace vizualizovaná v engvallexovém editoru a obsažená v souboru eng_pb_links.txt není kompletní. Vždy obsahuje jen nejfrekventovanější mapování rámce na frameset. Pokud jsou dvě různá mapování stejně frekventovaná, je zobrazeno pouze jedno. Soubor neposkytuje žádnou informaci o tom, kolika výskytům slovesa byl daný rámec přiřazen, takže není vidět, zda uvedené mapování pokrývá většinu případů, anebo zda se určitý rámec mapuje na mnoho různých framesetů a s jakou distribucí. Úplná informace o mapování se nachází v souboru eng_pb_links_for_all_rolesets.txt.
Soubor eng_pb_links_for_all_rolesets.txt vyjmenovává všechna mapování, která se vyskytla v korpusu pro daný engvallexový rámec. Například rámec ev-w3310f22 slovesa take (viz níže), který sestává z doplnění ACT, CPHR a PAT (analytický predikát), se mapuje na tyto propbankové framesety: take.01 (82 případů), take.02 (2 případy) and take.12 (1 případ). Když se mapuje na take.01, ACT se mapuje na ARG-0 v take.01 56krát a na ARG-1 dvakrát. PAT se mapuje na ARG-2 52krát a na ARG-1 21krát. Navíc máme informaci o mapování na anotovaná doplnění v PropBanku (korpusu), která nepatří do rolesetu, tj. seznamu argumentů definujících daný frameset. Tato mapování jsou uvedena ve složených závorkách. Člen PAT, který se mapuje na různé elementy ve framesetu take.01, se mapuje třikrát na ARG-M-LOC, dvakrát na ARG-M-DIR, jednou na ARG-M-ADV a jednou na ARG-M-MNR.
Engvallex frame ev-w3310f22 (take) ev-w3310f22 ACT CPHR PAT [propbank/e-v.xml::take.01::82] ACT [take.01::0::::56, take.01::1::::2]{} CPHR [take.01::1::::79, take.01::2::::2]{} PAT [take.01::2::::52, take.01::1::::21]{take.01::m::LOC::3, take.01::m::DIR::2, take.01::m::ADV::1, take.01::m::MNR::1} [propbank/e-v.xml::take.02::2] ACT [take.02::0::::1, take.02::1::::1]{} CPHR [take.02::1::::2]{} PAT [take.02::0::::1]{take.02::m::MNR::2} [propbank/e-v.xml::take.12::1] ACT [take.12::0::::1]{} CPHR [take.12::1::::1]{} PAT [take.12::1::::1]{}
V souboru eng_pb_links_with_ids.txt jsme přidali identifikátory uzlů u každého mapování. Engvallexový rámec ev-w3310f22 (take) vypadá takto:
ev-w3310f22 take.01 - ACT:ARG0 ACT:ARG0 CPHR PAT PAT (EnglishP-wsj_0109-s17-t18) take.01 - ACT:ARG0 ACT:ARG0 CPHR:ARG1 PAT:ARG1 (EnglishP-wsj_1928-s1-t13) take.01 - ACT:ARG0 ACT:ARG0 CPHR:ARG1 PAT:ARG2 (EnglishP-wsj_0184-s9-t20, EnglishP-wsj_1012-s7-t14, EnglishP-wsj_1797-s20-t13) take.01 - ACT:ARG0 CPHR:ARG1 (EnglishP-wsj_2418-s33-t7) take.01 - ACT:ARG0 CPHR:ARG1 PAT (EnglishP-wsj_0174-s22-t16) take.01 - ACT:ARG0 CPHR:ARG1 PAT:ARG1 (EnglishP-wsj_0207-s2-t6, EnglishP-wsj_0304-s10-t7, EnglishP-wsj_0452-s3-t26, EnglishP-wsj_0559-s13-t15, EnglishP-wsj_0666-s35-t2, EnglishP-wsj_0790-s2-t14, EnglishP-wsj_1205-s3-t4, EnglishP-wsj_1424-s39-t4, EnglishP-wsj_2040-s42-t5, EnglishP-wsj_2167-s12-t34, EnglishP-wsj_2212-s1-t9, EnglishP-wsj_2300-s83-t4, EnglishP-wsj_2443-s13-t7) take.01 - ACT:ARG0 CPHR:ARG1 PAT:ARG2 (EnglishP-wsj_0077-s1-t2, EnglishP-wsj_0090-s1-t11, EnglishP-wsj_0093-s4-t7, EnglishP-wsj_0121-s38-t15, EnglishP-wsj_0121-s46-t3, EnglishP-wsj_0590-s18-t11, EnglishP-wsj_0664-s32-t7, EnglishP-wsj_0764-s40-t2, EnglishP-wsj_1146-s91-t6, EnglishP-wsj_1250-s33-t6, EnglishP-wsj_1253-s18-t4, EnglishP-wsj_1270-s15-t13, EnglishP-wsj_1320-s64-t19, EnglishP-wsj_1419-s14-t14, EnglishP-wsj_1529-s16-t12, EnglishP-wsj_1569-s45-t2, EnglishP-wsj_1619-s21-t5, EnglishP-wsj_1831-s26-t6, EnglishP-wsj_2109-s27-t14, EnglishP-wsj_2151-s36-t25, EnglishP-wsj_2156-s25-t19, EnglishP-wsj_2387-s40-t4, EnglishP-wsj_2397-s61-t10, EnglishP-wsj_2404-s4-t16, EnglishP-wsj_2444-s4-t18) take.01 - ACT:ARG0 CPHR:ARG1 PAT:ARG2 PAT:ARG2 (EnglishP-wsj_0118-s125-t7, EnglishP-wsj_1411-s16-t22) take.01 - ACT:ARG0 CPHR:ARG1 PAT:ARGM-ADV (EnglishP-wsj_1569-s58-t4) take.01 - ACT:ARG0 CPHR:ARG1 PAT:ARGM-DIR PAT:ARGM-DIR (EnglishP-wsj_1504-s36-t11) take.01 - ACT:ARG0 CPHR:ARG1 PAT:ARGM-LOC (EnglishP-wsj_1792-s13-t16) take.01 - ACT:ARG0 CPHR:ARG1 PAT:ARGM-MNR (EnglishP-wsj_0293-s39-t3) take.01 - ACT:ARG1 CPHR:ARG2 PAT:ARGM-LOC (EnglishP-wsj_0931-s11-t33, EnglishP-wsj_1368-s6-t13) take.01 - CPHR:ARG1 (EnglishP-wsj_0295-s50-t7, EnglishP-wsj_1010-s32-t28, EnglishP-wsj_1916-s27-t14) take.01 - CPHR:ARG1 PAT (EnglishP-wsj_1569-s16-t8, EnglishP-wsj_2367-s21-t8) take.01 - CPHR:ARG1 PAT:ARG1 (EnglishP-wsj_1034-s5-t13, EnglishP-wsj_1294-s24-t11, EnglishP-wsj_1525-s42-t12, EnglishP-wsj_1766-s25-t21, EnglishP-wsj_2231-s10-t10, EnglishP-wsj_2384-s31-t30, EnglishP-wsj_2412-s78-t22) take.01 - CPHR:ARG1 PAT:ARG2 (EnglishP-wsj_0118-s47-t12, EnglishP-wsj_0286-s86-t16, EnglishP-wsj_0560-s18-t35, EnglishP-wsj_0604-s24-t19, EnglishP-wsj_1162-s50-t10, EnglishP-wsj_1213-s54-t11, EnglishP-wsj_1566-s37-t30, EnglishP-wsj_1600-s31-t34, EnglishP-wsj_1705-s6-t28, EnglishP-wsj_1766-s21-t24, EnglishP-wsj_1935-s13-t9, EnglishP-wsj_2128-s6-t21, EnglishP-wsj_2265-s76-t18, EnglishP-wsj_2386-s15-t6, EnglishP-wsj_2415-s30-t6) take.01 - CPHR:ARG1 PAT:ARG2 PAT:ARG2 (EnglishP-wsj_1022-s45-t3) take.01 - CPHR:ARG1 PAT:ARG2 PAT:ARG2 PAT:ARG2 (EnglishP-wsj_1984-s23-t36) take.02 - ACT:ARG0 CPHR:ARG1 PAT:ARGM-MNR PAT:ARGM-MNR (EnglishP-wsj_0153-s17-t4) take.02 - ACT:ARG1 CPHR:ARG1 PAT:ARG0 (EnglishP-wsj_0327-s28-t5) take.12 - ACT:ARG0 CPHR:ARG1 PAT:ARG1 (EnglishP-wsj_1291-s14-t9)