Institute of Formal and Applied Linguistics
Charles University, Czech Republic
Faculty of Mathematics and Physics
NPFL123 – Dialogue Systems
About
This course is a detailed introduction into the architecture of spoken dialogue systems, voice assistants and conversational systems (chatbots). We will introduce the main components of dialogue systems (speech recognition, language understanding, dialogue management, language generation and speech synthesis) and show alternative approaches to their implementation.
The lab sessions will be dedicated to implementing a simple dialogue system and selected components (via weekly homework assignments). We will use Python and a version of our Dialmonkey framework for this.
Logistics (spring 2026)
News
- HW10 code didn't work with the latest version of Transformers. You can update your repo from the upstream and the deadline is extended till June 4.
Language
The course will be taught in English, but we're happy to explain in Czech, too.
Time & Place
In-person lectures and labs take place in the Malá Strana building.
- Lectures: Mon 10:40, room S9 (1st floor)
- Labs: Mon 12:20, room S9
In addition, we plan to stream both lectures and lab instruction over Zoom and make the recordings available on Youtube (under a private link, on request, sent out to enrolled students at the start of the semester). We'll do our best to provide a useful experience.
- Zoom meeting ID: 981 1966 7454
- Password is the SIS code of this course (capitalized)
There's also a Discord you can use to discuss assignments and get news about the course. Invite links will be sent out to all enrolled students by the start of the semester. Please contact us by email if you want to join and haven't got an invite yet.
Passing the course
To pass this course, you will need to take an exam and do lab homeworks. There's a 60% points minimum for the exam and 50% for the homeworks to pass the course. See more details here.
Topics covered
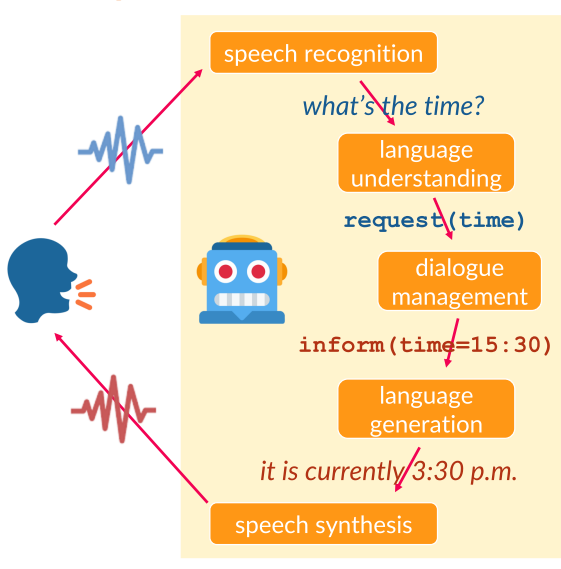
- Dialogue system types & formats (open/closed domain, task/chat-oriented)
- Data for dialogue systems
- Dialogue systems evaluation
- What happens in a dialogue (linguistic background)
- Dialogue system components
- speech recognition
- language understanding, dialogue state tracking
- dialogue management
- language generation
- speech synthesis
- Voice assistants & question answering
- Dialogue authoring tools (IBM Watson Assistant/Google Assistant/Amazon Alexa, RAG & LLM)
- Open-domain dialogue (chitchat chatbots, LLMs)
Lectures
PDFs with lecture slides will appear here shortly before each lecture (more details on each lecture are on a separate tab). You can also check out last year's lecture slides.
1. Introduction Slides Domain selection Questions
2. Data & Evaluation Slides Dataset exploration Questions
3. What happens in a dialogue? Slides Rule-based Natural Language Understanding Questions
4. Natural Language Understanding Slides Questions Statistical Natural Language Understanding
5. Neural NLU + State Tracking Slides Questions Belief State Tracking
6. Dialogue Policy (non-neural) Slides Dialogue Policy Questions
7. Neural policies & Natural Language Generation Slides API/Backend Calls Questions
8. Voice Assistants & Question Answering Slides Template NLG Questions
9. Dialogue Tooling Slides Service Integration Questions
10. Speech Recognition Slides Digits ASR Questions
11. Speech Synthesis Slides Grapheme-to-phoneme conversion Questions
12. Open-domain Chat Slides Retrieval chatbot Questions
Literature
A list of recommended literature is on a separate tab.
Lectures
1. Introduction
16 February Slides Domain selection Questions
- What are dialogue systems
- Common usage areas
- Task-oriented vs. non-task oriented systems
- Closed domain, multi-domain, open domain
- System vs. user initiative in dialogue
- Standard dialogue systems components
2. Data & Evaluation
23 Feburary Slides Dataset exploration Questions
- How to get data for building dialogue systems
- Available corpora/datasets
- Annotation
- Data splits
- Evaluation metrics -- subjective & objective, intrinsic & extrinsic
- Significance checks
3. What happens in a dialogue?
2 March Slides Rule-based Natural Language Understanding Questions
- Dialogue turns
- Utterances as acts, pragmatics
- Grounding, grounding signals
- Deixis
- Conversational maxims
- Prediction and adaptation
4. Natural Language Understanding
13 March Slides Questions Statistical Natural Language Understanding
- What needs to be handled to understand the user
- How to represent meaning: grammars, frames, graphs, dialogue acts (“shallow parsing”)
- Rule-based NLU
- Basics of machine learning, discriminative & generative classifiers
- Classification-based NLU (features, logistic regression, SVM)
- Sequence tagging (HMM, MEMM, CRF)
5. Neural NLU + State Tracking
16 March Slides Questions Belief State Tracking
- Some basics about neural networks
- How to use neural networks for NLU: neural classifiers and sequence taggers
- Handling speech recognition noise in NLU
- What is dialogue state, what is belief state, and what they're good for
- Dialogue as a Markov decision process (MDP)
- Dialogue trackers: generative and discriminative
- Static and dynamic trackers
- Neural trackers, integrated NLU+tracker
6. Dialogue Policy (non-neural)
23 March Slides Dialogue Policy Questions
- What's a dialogue policy -- how to choose the next action
- Finite-state, frame-based, and rule-based policies
- Reinforcement learning basics
- Value and policy optimization (SARSA, Q-learning, REINFORCE)
- Mapping to POMPDs (partially observable MDPs)
- Summary space (making it tractable)
- User simulation
7. Neural policies & Natural Language Generation
3 April Slides API/Backend Calls Questions
- Deep reinforcement learning
- Deep Q-Networks, Policy Networks
- Natural language generation
- Sentence planning & Surface realization
- Templates
- Rule-based approaches
- Neural: seq2seq, RNNs, Transformers
8. Voice Assistants & Question Answering
13 April Slides Template NLG Questions
- What are voice assistants
- Where, how and how much are they used
- What are their features and limitations
- What is question answering
- Basic question answering techniques
- Knowledge graphs
9. Dialogue Tooling
20 April Slides Service Integration Questions
- What are the standard tools for building dialogue systems on various platforms
- IBM Watson, Google Dialogflow, Alexa Skills Kit
- How to define intents, slots, and values
- How to build your own basic dialogues
10. Speech Recognition
27 April Slides Digits ASR Questions
- Basics of how speech recognition works
- Main pipeline: speech activity detection, preprocessing, acoustic model, decoder
- Features -- MFCCs
- Acoustic model with neural nets
- Decoding -- language model
- End-to-end speech recognition
11. Speech Synthesis
4 May Slides Grapheme-to-phoneme conversion Questions
- Human articulation
- Phones, phonemes, consonants, vowels
- Spectrum, F0, formants
- Stress and prosody
- Standard TTS pipeline
- Segmentation
- Grapheme-to-phoneme conversion
- Formant-based, concatenative, HMM parametric synthesis
- Neural synthesis
12. Open-domain Chat
22 May Slides Retrieval chatbot Questions
- Non-task-oriented/open-domain systems and their specifics
- rule-based, retrieval, generative, hybrid approaches
- Turing test, Alexa Prize
- LLMs for open-domain dialogue
Homework Assignments
There will be 12 homework assignments, each for a maximum of 10 points. Please see details on grading and deadlines on a separate tab. Note that there's a 50% minimum requirement to pass the course.
Assignments should be submitted via Git – see instructions on a separate tab. Please take special care about naming your Git branches and files the way they're given in the assignments. If our automatic checks don't find your files, you'll lose points!
You should run automatic checks before submitting -- have a look at TESTS.md. Code that crashes during the automatic checks will not get any points. You may fail the checks and still get full points, or ace the checks and get no points (especially if your code games the checks). Note that you should update your checkout since the code for the assignments might be changed during the semester.
All deadlines are 23:59:59 CET/CEST.
Index
3. Rule-based Natural Language Understanding
4. Statistical Natural Language Understanding
11. Grapheme-to-phoneme conversion
1. Domain selection
Presented: 16 February, Deadline: 5 March
You will be building a task-oriented dialogue system in (some of) the homeworks for this course. Your first task is to choose a domain and imagine how your system will look like and work like. Since you might later find that you don't like the domain, you are now required to pick two, so you have more/better ideas later and can choose only one of them for building the system.
Requirements
The required steps for this homework are:
-
Pick two domains of your liking that are suitable for building a task-oriented dialogue system. Think of a reasonable backend (see below).
-
Write 5 example system-user dialogues for both domains, which are at least 5+5 turns long (5 sentences for both user and system). This will make sure that your domain is interesting enough. You do not necessarily have to use English here (but it's easier if we understand the language you're using -- ask us if unsure, Czech & Slovak are perfectly fine).
-
Create a flowchart for your two domains, with labels such as “ask about phone number”, “reply with phone number”, “something else” etc. It should cover all of your example dialogues. You can use e.g. Mermaid to do this, but the format is not important. Feel free to draw this by hand and take a photo, as long as it's legible.
- It's OK (even better) if your example dialogues don't go all in a straight line (e.g. some of them might loop or go back to the start).
Files to commit
Please stick to the file naming conventions -- you will lose points if you don't!
-
hw1/README.mdwith short commentary on both domains (ca. 10-15 sentences) -- what they are, what features you'd like to include, what will be the backend (see examples below). -
hw1/examples-<domain1>.txt,hw1/examples-<domain2>.txt-- 5 example dialogues for each of the domains (as described above). Use a short domain name, best with just letters and underscores.- Separate different dialogues by empty lines
- Distinguish user and system somehow
- Please use UTF-8 encoding for these files.
-
hw1/flowchart-<domain1>.{pdf,jpg,png},hw1/flowchart-<domain2>.{pdf,jpg,png}-- the flowcharts for each of the domains, as described above.
See the instructions on submission via Git -- create a branch and a merge request with your changes. Make sure to name your branch hw1 so we can find it easily.
Inspiration
You may choose any domain you like, be it tourist information, information about culture events/traffic, news, scheduling/agenda, task completion etc. You can take inspiration from stuff presented in the first lecture, or you may choose your own topic.
Since your domain will likely need to be connected to some backend database, you might want to make use of some external public APIs -- feel free to choose under one of these links:
You can of course choose anything else you like as your backend, e.g. portions of Wikidata/DBPedia or other world knowledge DBs, or even a handwritten “toy” database of a meaningful size, which you'll need to write to be able to test your system.
2. Dataset exploration
Presented: 23 February, Deadline: 12 March
The task in this lab is to explore dialogue datasets and find out more about them. Your job will thus be to write a script that computes some basic statistics about datasets, and then try to interpret the script's results.
Requirements
-
Take a look at the Dialog bAbI Tasks Data 1-6 dataset. Read the description of the data format in the readme.txt file. You'll be working with Tasks 5 and 6 (containing full generated dialogues and DSTC2 data). Use the training sets for Task 5 and Task 6.
-
Write a script that will read all turns in the data and separate the user and system utterances in the training set.
- Make the script ignore any search results lines in the data (they don't contain a tab character).
- If the script finds a turn where the user is silent (the user turn contains only
<SILENCE>), it should concatenate the system response from this turn to the previous turn. Note that this may happen on multiple consecutive turns, and the script should join all of these together into one system response.- If
<SILENCE>is the first word in the dialogue, just delete it.
- If
- For tokenization, you should use the
word_tokenizefunction from the nltk package.
-
Implement a routine that will compute the following statistics for both bAbI tasks for system and user turns (separately, i.e., 4 sets of statistics altogether):
- data length (total number of dialogues, turns, words)
- mean and standard deviations for individual dialogue lengths (number of turns in a dialogue, number of words in a turn)
- vocabulary size
- Shannon entropy and bigram conditional entropy, i.e. entropy conditioned on 1 preceding word (see lecture 2 slides)
Commit this file as
hw2/stats.py. -
Along with your script, submit also a dump of the results. The results should be formatted as JSON file with the following structure:
{
"task5_user":
{
"dialogues_total": XXX,
"turns_total": XXX,
"words_total": XXX,
"mean_dialogue_turns": XXX,
"stddev_dialogue_turns": XXX,
"mean_dialogue_words_per_turn": XXX,
"stddev_dialogue_words_per_turn": XXX,
"vocab_size": XXX,
"entropy": XXX
"cond_entropy": XXX
},
"task5_system": ...
"task6_user": ...
"task6_system": ...
}
(Create a dict and use json.dump for this.)
Commit the json file as hw2/results.json.
-
Add your own comments, comparing the results between the two bAbI Tasks. 3-5 sentences is enough, but try to explain why you think the vocabulary and entropy numbers are different.
Put your comments in Markdown as
hw2/stats.md.
Files to commit
There are empty files ready for you in the repo the right places, you just need to fill them with information.
Just to sum up, the files are:
hw2/stats.py-- your data analysis scripthw2/results.json-- JSON results of the analysishw2/stats.md-- your comments
Create a branch and a merge request containing (changes to) all requested files. Please keep the filenames and directory structure.
Notes
-
Don't worry too much about the exact numbers you get, slight variations in implementation may cause them to change. We won't penalize it if you don't get the exact same numbers as us, the main point is that your implementation should be reasonable (and you shouldn't be off by orders of magnitude).
-
Don't worry about system
api_calls, just treat them as a normal system turn.
3. Rule-based Natural Language Understanding
Presented: 2 March, Deadline: 19 March
In this assignment, you will design a dialogue system component for Natural Language Understanding in a specific domain. For completing it, you will use our prepared Dialmonkey dialogue framework (which is the base of your Gitlab repository), so you can test the outcome directly.
Language understanding means converting user utterances (such as “I'm looking for a Chinese restaurant in the city center”) into some formal representation used by the dialogue manager.
We'll use dialogue acts as our representation – so the example sentence would convert to something like inform(food=Chinese,area=centre) or find_restaurant(food=Chinese,area="city center"),
depending on how you define the intents, slots and values within the dialogue acts for your own domain.
Note: We're not thinking about how to reply just yet! The only thing we're concerned with is representing user inputs in our domain with reasonable intents, slots, and values.
Requirements
-
Make yourself familiar with the Dialmonkey-npfl123 repository you cloned for the homeworks. Read the README and look around a bit to get familiar with the code. Have a look at the 101 Jupyter notebook to see some examples.
-
Recall the domains you picked in the first homework assignment and choose one of them. If you've changed your mind in the meantime, you can even pick a different domain.
-
Think of the set of dialogue acts suitable to describe this domain, i.e., list all intents, slots and values that will be needed (some slots may have open sets of values, e.g. “restaurant name”, “artist name”, “address” etc.). List them, give a description and examples in Markdown under
hw3/README.md. -
Create a component in the dialogue system (as Python code) that:
- inherits from
dialmonkey.component.Component - is placed under
dialmonkey.nlu.rule_<your-domain> - implements a rule-based NLU for your domain -- i.e., given user utterance, finds its intent, slots and values
- yields Dialogue Act items you designed in step 3 (as
DAobjects).
Please only use the core Python libraries and those listed in
requirements.txt. If you have a good reason to use a different library from PyPi, let us know and we can discuss adding it into the requirements (but this will be global for everyone).You can have a look at a simple NLU for the restaurant domain for inspiration and guidance on how to produce the Dialmonkey components (please update from upstream if you don't see the file in your repo).
- inherits from
-
Create a YAML config file for your domain in the
confdirectory. You can use thesample_conf.yamlfile ornlu_test.yamlas a starting point. These files are almost identical, just have a look at the I/O setup if you're interested. Note that instead of a policy and NLG components, a system with this config will simply reply with the NLU result. -
Write at least 15 distinct utterances that demonstrate the functionality of your class (a tab-separated file with input + corresponding NLU result, one-per-line). Make sure your NLU gives you the same results. The test utterances can (but don't have to) be taken over from the example dialogues you wrote earlier for your domain. Save them as
hw3/examples.tsv.
Files to include in your merge request
There will be empty files ready for you in the right place, just rename them according to your domain (e.g. change <your_domain> to restaurant, bus etc.) and fill them with the required content.
- Lists of intents, slots and values in
hw3/README.md - Your NLU component in
dialmonkey/nlu/rule_<your_domain>.py - Your configuration file in
conf/nlu_<your_domain>.yaml - Example test utterances & outputs in
hw3/examples.tsv
Create a branch and a merge request containing (changes to) all requested files. Please keep the filenames and directory structure.
Hints
Use regular expressions or keyword matching to find the intents and slot values (based on the value, you'll know which slot it belongs to).
If you haven't ever used regular expressions, have a look some tutorials:
Note that you might later need to improve your NLU to handle contextual requests, but you don't need to worry about this now. For instance, the system may ask What time do you want to leave? and the user replies just 7pm. From just 7pm (without the preceding question), you don't know if that's a departure or arrival time. Once you have your dialogue policy ready and know how the system questions look like (which will be the 6th homework), you'll be able to look at the last system question and disambiguate. For now, you can keep these queries ambiguous (e.g. just mark the slot as “time”).
4. Statistical Natural Language Understanding
Presented: 9 March, Deadline: 26 March
In this assignment, you will build and evaluate a statistical Natural Language Understanding component on the DSTC2 restaurant information data. For completing it, you will use the Dialmonkey framework in your code checkout so you can test the outcome directly.
Requirements
-
Locate the data in your Dialmonkey-NPFL123 repository in
data/hw4/. This is what we'll work with for this assignment. -
Implement a script that trains statistical models to predict DAs. We'll use classifiers here. By default, your approach shouldn't be to predict the whole DA as a single classifier, rather you should classify the correct value for each intent-slot pair where applicable (e.g. inform(food) has multiple possible values) and classify a binary 0-1 for each intent-slot pair that can't have different values (e.g. request(price) or bye() ).
Don't forget that for the multi-value slots (including 2-valued slots with Y/N), you'll need a “null” value too. Have a look at examples here to get a better idea.
You can use any kind of statistical classifier you like (e.g. logistic regression, SVM, neural network, including pretrained models or LLMs), with any library of your choice (e.g. Scikit-Learn, Tensorflow, Pytorch ).
Using binary classifiers for everything may be an option too (especially if you use neural networks with shared layers), but the number of outputs will be rather high, hence the recommendation for multi-class classifiers. Note that we can't do slot tagging here, as the individual words in the texts aren't tagged with slot values.
In case you want to use an LLM, we prefer using a (small!) model locally to prompting ChatGPT or the like. In this case, you don't have to stick to individual classifications and may want to have the model predict everything -- just make sure the output gets the whole DA from the inputs you have available.
-
Train this model on the training set. You can use the development set for parameter tuning. Using
dialmonkey.DA.parse_cambridge_da()should help you get the desired DA values out of the textual representation. Do not look at the test set at this point!In case you're using LLMs, this would mean prompt tuning -- try out at least 3 different variations of the prompt.
-
Evaluate your model on the test set and report the overall precision, recall and F1 over dialogue act items (triples of intent-slot-value).
Use the script provided in
dialmonkey.evaluation.eval_nlu. You can run it directly from the console like this:./dialmonkey/evaluation/eval_nlu.py -r data/hw4/dstc2-nlu-test.json -p hw4/predicted.txtThe script expects reference JSON in the same format as your data here, and a system output with one DA per line. You can have a look at
conf/nlu_test.yamlto see how to get one-per-line DA output.For the purpose of our evaluation script F1 computation, non-null values count as positives, null values count as negatives. Whether they're true or false depends on whether they're correctly predicted.
-
Implement a module in Dialmonkey that will load your NLU model and work with inputs in the restaurant domain. Create a copy of the nlu_test.yaml config file to work with your new NLU.
Files to include in your merge request
- Your statistical NLU module as
dialmonkey/nlu/stat_dstc.pyand your trained model. The filename for the model will depend on your implementation, it just needs to be loaded automatically for your model to work. Preferrably store in the same directory, but it could be anywhere else if needed. If the file is too big for Git (>10MB), share it using a cloud service (e.g. CESNET OwnCloud) and make your NLU module download it automatically in__init__(). - Your YAML config file under
conf/nlu_dstc.yaml. - Your training script as
hw4/train_nlu.py. - Your predicted output as
hw4/predicted.txtand a short evaluation report underhw4/README.md(including your F1 scores).
Important implementation notes
Note 1: There are templates for you to get you started quickly with the training script and the prediction Dialmonkey module. Feel free to change them in any way you like or need, they're not binding (just make sure your code does what's expected). If you can't see the templates in your repo, please update from upstream.
Note 2: Please do not use any Python libraries other than the ones in requirements.txt,
plus the following ones: torch (Pytorch), tensorflow, pytorch-lightning, torchtext, transformers (Huggingface). Note that scikit-learn is included already. If you need any others, please let us know beforehand.
Note 3: Please make sure that your code doesn't take more than a minute to load + classify the first 20 entries in the test data. For the sake of model storage, it's better to choose a smaller one, especially if you choose to play with pretrained language models.
Note 4: And this one is for all further assignments -- Do not use absolute file paths in your solution! You may want to try out os.path.dirname(__file__), which gets you the directory of the current source file. If you need to use slashes in a (relative!) path, use either os.path.join instead, or use forward slashes and a pathlib.Path object (simply create it using filename = Path(filename)). This will handle the slashes properly both on Windows and Linux. Note that we're mainly checking on Linux, so any backslashes in file paths will break our workflow and we may deduce points.
Hints
-
Start playing with the classifier separately, only integrate it into Dialmonkey after you've trained a model and can load it.
-
If you have never used a machine learning tool, have a look at the Scikit-Learn tutorial. It contains most of what you'll need to finish this exercise.
-
You'll need to convert your texts into something your classifier understands (i.e., some input numerical features). You can probably do very well with just “bag-of-words” as input features to the classifier -- that means that you'll have a binary indicator for each word from the training data (e.g. word “restaurant”). The feature for the word “restaurant” will be 1 if the word “restaurant” appears in the sentence, 0 if it doesn't. You can also try using the same type of features for bigrams. Have a look at the DictVectorizer class in Scikit-Learn. You may also want to consider CountVectorizer, which could speed up things even more.
-
For Scikit-Learn, you can use pickle to store your trained models. If you want to pickle classes, use the dill library instead (since pickle can't do that).
-
To easily load JSON files, you can use the SimpleJSONInput class.
-
You better don't use the naive Bayes classifier, it doesn't work well on this data – basically anything else works better (you won't lose any points if you use naive Bayes, just don't expect good performance).
5. Belief State Tracking
Presented: 16 March, Deadline: 2 April
This week, you will build a simple probabilistic dialogue/belief state tracker to work with NLU for both your own domain of choice (3rd assignment) and DSTC2 (4th assignment).
Requirements
-
Implement a dialogue state tracker that works with the
dial.statestructure (it's adict) and fills it with a probability distribution of values over each slot (assume slots are independent), updated during the dialogue after each turn. Don't forgetNone(ornull, as described in HW4) is a valid value, meaning “we don't know/user didn't say anything about this”.At the beginning of the dialogue, each slot should be initialized with the distribution
{None: 1.0}.The update rule for a slot, say
food, should go like this:- Take all mentions of
foodin the current NLU, with their probabilities. Say you gotChinesewith a probability of 0.7 andItalianwith a probability of 0.2. This meansNone(ornullas shown in HW4 examples) has a probability of 0.1. - Use the probability of
Noneto multiply current values with it (e.g. if the distribution was{'Chinese': 0.2, None: 0.8}, it should be changed to{'Chinese': 0.02, None: 0.08}. - Now add the non-null values with their respective probabilities from the NLU. This should result in
{'Chinese': 0.72, 'Italian': 0.2, None: 0.08}.
To make sure your tracker works with either NLU system, simply use whatever is in
dial.nluas the input. Make sure both your NLU systems fill in thedial.nlustructure -- feel free to edit your NLU systems' code.Note that you should be using probability estimates in your statistical NLU from the 4th assignment now (for your rule-based NLU on own domain from the 3rd assignment, just assume a probability of 1 if your patterns match).
Set a threshold for low-probability NLU outputs that you'll ignore in the tracker (good choice is 0.01-0.05), so that the outputs are not too messy.
- Take all mentions of
-
Create new configuration files both for your own rule-based domain and for DSTC2, which include NLU and the tracker. In addition, use
dialmonkey.policy.dummy.ReplyWithStateas the output (so the system's response is now the current dialogue state).You can use
conf/dst_test.yamlas a starting point (just put in your NLU and tracker). -
Run your NLU + tracker over your NLU examples from 3rd assignment and the first 20 lines from the DSTC2 development data (file
data/hw4/dstc2-nlu-dev.json) from the 4th assignment data and save the outputs to a text file for both. You can use Dialmonkey's file input settings for this.Treat the examples as a single dialogue, even though such a “dialogue” doesn't make any logical sense. Your tracker should be able to handle it.
Hints
-
You can have a look at an example dialogue with commentary for the update rule in a separate file (it's basically the same stuff as above, just more detailed).
-
Remember that all this is just about slots, not intents – do not consider intents as part of the state. You generally don't need to track past intents, just the current intent from NLU is enough to guide the system.
-
If your statistical NLU is built as classifiers for intent-slot pairs (as foreseen by default in HW4), you can just use the probabilities coming from the
informintent for the given slot. The best way would be to add up "positive" intents such asinformorconfirmand discount negative ones, such asdeny, but we don't require you to do this as part of the assignment.
Files to include in your merge request
- Your tracker code under
dialmonkey/dst/rule.py. - Your updated configuration files for both domains under
conf/dst_<my-domain>.yamlandconf/dst_dstc.yaml. - Your text files with the outputs into
hw5/outputs_<my-domain>.txtandhw5/outputs_dstc.txt.
6. Dialogue Policy
Presented: 23 March, Deadline: 16 April (with HW7!)
This week, you will build a rule-based policy for your domain.
Requirements
-
Implement a rule-based policy that uses the current NLU intent (or intents, coming from your NLU) and the dialogue state (coming from your tracker) to produce system action dialogue acts. You can use just the most probable value for each slot, assuming its probability is higher than a given threshold (e.g. 0.7). Since your NLU is rule-based, the actual value of the threshold doesn't matter much (should be >0): you'll likely have zero or one value with a probability of 1, the rest with a probability zero.
The policy should:
- Check the current intent(s) and split the action according to that
- Given the intent, check that the state contains all necessary slots to respond:
- if it does, fill in a response system DA into the
dial.actionfield. - if it doesn't, fill in a system DA requesting more information into the
dial.actionfield.
- if it does, fill in a response system DA into the
You can use the flowcharts you built in HW1 to guide the policy's decisions (but it's fine if you don't stick to them).
You can skip any API queries and hardcode the responses at first (you will build the actual backend in HW7), or you can build the two assignments together.
-
Save the policy under
dialmonkey.policy.rule_<your_domain>and create a configuration file for your own domain that will include it. -
In your new configuration file, include
dialmonkey.policy.dummy.ReplyWithSystemActionas the last step -- this replacesdialmonkey.policy.dummy.ReplyWithStateyou used previously (don't worry that you have two things from the policy package in your pipeline). -
Check that your policy returns reasonable system actions for each of your NLU test utterances from HW3, if you treat each utterance as a start of a separate new dialogue (it's OK if it's not exactly what is meant, the utterances will be taken out of context).
Run your policy over your NLU test utterances, each taken as a start of a separate dialogue, and save the outputs to a text file. You can either do this by hand, or you may consider creating a script that creates an instance of
ConversationHandlerand useshandler.run_dialogue()-- see the 101 Jupyter notebook. Outputs can be saved to a file usingdialmonkey.output.text.FileOutput.
Files to include in your repository
- Your policy (
dialmonkey/policy/rule_<your_domain>.py) and your updated configuration file (conf/act_<your_domain>.yaml). - The outputs of your policy on your NLU test utterances as
hw6/outputs.txt(one per line).
Note: If you're submitting together with HW7, make just a single merge request,
with a branch labelled hw7, but include all the files required for both assignments.
Note 2: To make testing smooth, please merge your HW3 merge request into master & merge that into your submission MR for HW6/HW7. This will make your NLU examples file available for us, so we see not just the output but also the corresponding inputs in the repository.
Hints
-
Note that we're not creating natural language responses just yet, just the system action DAs.
-
Your policy will most probably be a long bunch of
if-then-elsestatements. Don't worry about it. You may want to structure the file a bit so it's not a huge long function though -- e.g., add the handling of different request types into separate functions, if it's not just 1 line. -
You may want to complete this homework together with the next one, which will be about backend integration. That's why the deadline is two weeks after HW5.
7. API/Backend Calls
Presented: 30 March, Deadline: 16 April (with HW6)
This week is basically a continuation of the last one -- filling in the blank API call placeholders you created last time. If you want to, you can complete the 6th and 7th homework at the same time -- the deadline is the same.
Requirements
-
Implement all API/backend queries you need for the policy you implemented in HW6. The implementation can be directly inside
dialmonkey.policy.rule_<your_domain>, or you can create a sub-package (a subdirectory, where you put the main policy inside__init__.pyand any auxiliary stuff into other files in the same directory).It depends on your domain if the implementation will be external API queries (preferrable) or some kind of internal database (e.g. a CSV table). In case you implement a local database, please add at least 10 different entries. Let us know if you think this doesn't make sense for your domain.
-
Test your policy with outputs on at least 3 of the test dialogues you created in HW1. You can of course make alterations if your policy doesn't behave exactly as you imagined the first time. If you changed your domain since HW1 and your examples do not apply, you can draft 3 dialogues of 5+ turns.
Also, don't worry that the output is just dialogue acts at the moment.
Files to include in your repository
- Commit your policy (
dialmonkey/policy/rule_<your_domain>.py), updated with API calls. - Put logs of your test dialogues as
hw7/outputs.txt(with user inputs and system output acts).
Note: if you're submitting together with HW6, make just a single merge request,
with a branch labelled hw7, but include all the files required for both assignments.
Implementation notes
For hw7/outputs.txt, please make the format like this:
U: Hello, how are you?
S: hello()&request(area)
[...]
U: Thank you, goodbye!
S: bye()
U: Hello, I need a cheap restaurant
S: hello()&confirm(price=cheap)&request(area)
[...]
Make all lines start with U: and S: marking the user and system turns, with system turns consisting of dialogue acts (in Cambridge or Dialmonkey format). Put an empty line between different dialogues.
There's a class called DialogueLogOutput,
which will deal with the format for you. Just use it as your output stream (see the README
on how to do that).
Hints
- If you want to access an external API using Python, check out the requests library. It makes it easy to call external APIs using JSON. You can get the result with just a few lines of code.
8. Template NLG
Presented: 13 April, Deadline: 30 April
In this homework assignment, you will complete the text-based dialogue system for your domain by creating a template-based NLG component.
Requirements
-
Implement a template-based NLG with the following features:
-
The NLG system is (mostly) generic and can load templates for your domain from a JSON or YAML file (only one of these formats is fine!), showing a DA -> template mapping.
-
The NLG system is able to prioritize a mapping for a specific value -- e.g.
inform(price=cheap)-> “You'll save money here.” should get priority overinform(price={price})-> “This place is {price}.” -
The NLG system is able to put together partial templates (by concatenating), so you can get a result for e.g.
inform(price=cheap,rating=3)even if you only have templates defined forinform(price={price})andinform(rating={rating}), not the specific slot combination. So if you have templatesinform(price={price})-> “The place is {price}.” andinform(rating={rating})-> “The place is rated {rating} stars.”, your output forinform(price=cheap,rating=3)should be “The place is cheap. The place is rated 3 stars.”This doesn't need to search for best coverage, just take anything that fits, such as templates for single slots if you don't find the correct combination.
-
The system is able to produce multiple variations for certain outputs, e.g.
bye()-> Goodbye. or Thanks, bye!
-
-
Create templates that cover your domain well.
-
Save your NLG system under
dialmonkey.nlg.templates_<your-domain>and add it into yourconf/text_<your-domain>.yamlconfiguration file. -
Test your NLG system with the test dialogues you used in the previous assignment.
Implementation instructions
Make sure your template NLG is really domain-general. We're going to test it on a different domain from yours! You can have specific additions for your domain in there, just make sure it'll work reasonably well with any slot names.
Access to template file: In your NLG class, include a constructor method with this signature: def __init__(self, config). Call super().__init__(config) as the first thing inside this
constructor method. Include a def load_templates(self, filename) function which loads your templates and call it in the constructor (note this method will be called in our tests!).
You can pass the filename to the constructor (inside config) via the YAML config file, e.g. you add:
components:
[...]
- dialmonkey.nlg.templates_<your-domain>:
templates_file: dialmonkey/nlg/templates_<your-domain>.<yaml|json>
And you can use config['templates_file'] in the constructor to get the file path. To make life easier, this is actually included in the default template for the NLG component that you can start from.
Paths warning (repeat): If you need slashes in the path, use forward slashes and a pathlib.Path object (simply create it using filename = Path(filename)), it will handle the slashes properly both on Windows and Linux.
Do not use absolute paths! You may want to try out os.path.dirname(__file__), which gets you the directory of the current source file.
Templates format: Use a dict where keys are DAs (either in native triple style, or Cambridge style) and values are lists of templates (variants), with slot placeholders marked using curly braces. Example YAML:
"inform(price=cheap)":
- This place is cheap.
"inform(price={price})":
- This place is {price}.
"bye()":
- Goodbye.
- Thanks, bye!
Example JSON:
{
"inform(price=cheap)": [
"This place is cheap."
],
"inform(price={price})": [
"This place is {price}."
],
"bye()": [
"Goodbye.",
"Thanks, bye!"
]
}
Setting the reply: Call dial.set_system_response(text) where text is your NLG output, so the system actually uses your NLG to respond.
Remove ReplyWithSystemAction (used in HW6 & HW7) from your config file, it's no longer needed :-).
Files to include in your merge request
- Your NLG implementation in
dialmonkey/nlg/templates_<your-domain>.py - Your templates file in
dialmonkey/nlg/templates_<your-domain>.<yaml|json> - A full configuration file for your domain, which includes the NLG system, under
conf/text_<your-domain>.yaml - Logs of the test dialogues from HW7, now with NLG output, in
hw8/outputs.txt
9. Service Integration
Presented: 20 April, Deadline: 7 May
In this homework, you will integrate the chatbot for your domain into an online assistant of your choice (Google/Alexa/Facebook/Telegram). Telegram is the “default” (this is in no way an endorsement of the network!), but you can choose whichever you like.
Requirements
- Choose a service that you want to use for this homework. We prepared some instructions for Google Dialogflow, Alexa Skills, Facebook Messenger, and Telegram.
Note that Dialogflow and Alexa are unfortunately not available for Czech.
-
Implement the frontend on your selected platform. You can either carry over intents, slots & values from your NLU directly into Dialogflow/Alexa/Watson, or you can work with free text and run the NLU in the backend. For Messenger and Telegram, that's the only option (but their frontend basically comes for free).
-
Implement a backend that will connect to your frontend – handle its calls and route them to your dialogue system in Dialmonkey (either with NLU already processed, or with free text as input). You can use the
get_responsemethod indialmonkey.conversation_handler.ConversationHandlerto control the system outside of the console. Don't forget to save context in between requests. However, you can assume for simplicity that the bot will always have just one dialogue, i.e. you do not have to care about parallel conversations. -
Link your frontend to your backend (see Hints below).
Detailed instructions
Amazon Alexa
-
Alexa allows you to run NLU directly in your backend but it's a bit tricky -- the only way to get free text is to use the SearchQuery built-in slot. You can set up an intent where the only part of the utterance is this slot.
-
For implementing backend, you can use the Flask-Ask package as a base. You can have a look at an Alexa Skill Ondrej made for inspiration (not many docs, though, sorry).
-
Set your backend address under “Endpoint” (left menu).
Google Dialogflow
- To make use of you NLU, you can make use of the Default fallback intent which gets triggered whenever no other intent is recognized.
- For backend implementation, you can use Flask-Assistant.
- Set your backend address under “Webhooks” for the individual intents (under the “Fulfillment” menu of each intent). If you want to get free text of the requests, have a look at this snippet.
Facebook Messenger
For Messenger, you need to perform several steps, however, it allows you to work with textual inputs directly. In general, you can follow the tutorial. Here are the important steps you need to complete:
- Implement a webserver using Flask. It might be a good idea to start from the example implementation (feel free to reuse it).
See the tutorial here for other options. - You need to implement GET method handler for verification and POST method handler to receive message and send the reply. You can also use pymessenger, though the code isn't maintained.
- Set up your webserver on a public URL.
- Create a facebook page which will represent your bot. This is where you'll be able to chat with it.
- The verification step requires two tokens -- a verification token (an arbitrary string that you choose) and an access token (which you'll get from Facebook).
- Visit the dev page and create an account.
- Create a new app. Under use cases, pick "Business messaging" / "Engage with customers on Messenger". Pick "I don't want to connect to a business portfolio yet".
- In the App dashboard:
- Go to "Facebook Login for Business" and create a configuration, stick to defaults and pick "pages_messaging" as the permission.
- Go to "Use cases" and "Customize" under "Engage with customers...". Pick "Messenger API settings". Now you can add the URL pointing to your webserver and the verification token you chose.
- Then you can link the page to your app -- you get the access token to save & use in your webserver.
- This should be enough for testing, you don't need a review.
Telegram
Telegram also allows direct text input. There's also a handy Python-Telegram-Bot library that has a webserver built in.
- You need to get a telegram bot API token from the BotFather -- it's pretty straightforward, you
talk to this “one bot to rule them all”, ask it for
/newbotand it'll guide you through the process. You can find more info on their documentation page. - With the use of your API token, you need to create the telegram bot using Python-Telegram-Bot. These examples should be a good way of starting it. There's even a tutorial. In general, you'll need to implement a command handler that'll pass on the message from Telegram to your system. No web server is necessary, Python-Telegram-Bot has one built in.
- Start up your bot and you can talk to it on Telegram.
Files to include in your merge request
- Commit your frontend export into
hw9/:- In Alexa, go to “JSON Editor” in the left menu and copy out the contents into a file
intent_schema.json. - In Dialogflow, go to your agent settings (cogged wheel next your agent/skill/app name on the top left), then select the “Export & Import” tab and choose “Export as ZIP”. Please commit the resulting subdirectory structure, not the ZIP file.
- Nothing is required for Messenger and Telegram at this point.
- In Alexa, go to “JSON Editor” in the left menu and copy out the contents into a file
- Commit your bot server code into
hw9/server.py. This code will probably import a lot from Dialmonkey and require it to be installed -- that's expected.- Make sure that
python hw9/server.pywill run the bot with the default settings. Useif __name__ == '__main__'for that, so we can import your code for tests. - Include a function called
reply_<google|alexa|facebook|telegram>that replies to a message (depending on the service) or calls a function that does that (passing on whatever parameters are needed on the given platform). This corresponds to:- Google: A Flask-Assistant function with the decorator
@assist.action('Default fallback intent') - Alexa: A Flask-Ask function with the decorator
@ask.intent('YourDefaultIntent') - Facebook: The
webhookfunction with the Flask decorator@app.route('/', methods=['POST']) - Telegram: A function set as Python-Telegram-Bot
MessageHandlerfor default text messages (this is the function calledechoin the tutorial)
- Google: A Flask-Assistant function with the decorator
- In case you reimplement your intents for Google/Alexa, you may skip implementing this function (since it would decompose into many different functions). We'll check manually 🙂.
- Make sure that
- Add a short
READMEtelling us how to run your bot. You don't need to commit any API tokens (we can get our own for testing), but let us know in the readme where to add the token.
Hints
- To test out your backend, you can run your server on your own machine and use ngrok for testing purposes. Ngrok will tunnel a port on your machine and expose it publicly over HTTPS.
- Alternatively, you could think about deploying your server on a PaaS site. Here's a list of a few that feature a free tier. (This is entirely optional and untested by us. We tested Heroku but that's no longer free.)
- To
import dialmonkey.*in your solution so that you can easily use your own modules, there are essentially two ways:- You can make an editable install of your Dialmonkey-npfl123 checkout directory -- within your virtualenv/conda environment, simply go to your checkout directory and run:
pip install -e .
That way, you can make imports from all the Dialmonkey packages from anywhere.
- Alternatively, you can add the
..directory intohw9/server.py'ssys.path. This is essentially what we're doing with the automatic tests. Use relative paths for the import, like this:
import os, sys
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
10. Digits ASR
Presented: 27 April, Deadline: 4 June (extended)
This time, your task will be to train and evaluate an ASR system on a small dataset. We will be using pretrained Wav2vec 2.0 model from Huggingface and finetuning it further. This is an end-to-end ASR model, so we won't have to fiddle with language models or pronunciation dictionary -- it goes straight from audio to characters.
This assignment is relatively compute-heavy. You can use Google Colab for the task, or any machine with a GPU. It can run on a CPU, but it takes a few hours. If you don't want to work with Google Colab or a GPU, you can try out the 2021 assignment with Kaldi -- that's not an end-to-end, with separate acoustic and language models, and trains fine on a CPU, but it's really fiddly to set it up!
Requirements
Basically, what we want you to do is take the pretrained Wav2Vec2 model, measure WER on Ondrej's fork of the Free Spoken Digits Dataset, then finetune it for a random data split and a per-speaker split, and compare and analyze the results.
You have two options -- you can either use the supplied Python code (best for working on a cluster), or you can use the IPython notebook (best for Google Colab).
Detailed Instructions
-
Check and examine the given code (either Python or IPython notebok) + library of functions + Wav2vec2 online description, so you know how to complete the code.
-
Set up Wav2vec2 required libraries (see requirements.txt) -- note that they'll take up a few gigs of space. Also download Ondrej's fork of the Free Spoken Digits Dataset. This is included in the IPython notebook as well.
- Note that the data has two train-test splits: random and per speaker
- Technical note: the audio has 8kHz sampling rate, but Wav2Vec2 uses 16kHz internally. There's a loading function in the library that deals with this.
-
Implement:
- a function for running the predictions (see the Wav2Vec2 online description for this)
- a function for loading the data from a given directory (use the library function and assign transcripts, note that the target transcriptions need to be uppercased!)
- a function for computing WER (see the Wav2Vec2 online description for this)
-
Load the non-finetuned model (see Wav2Vec2 description), input processor, and data collator.
-
Load the data for random split and compute WER with the non-finetuned model.
-
Using a function from the library (which includes all needed settings), finetune the model on the random data split. Measure WER again.
-
Reload the non-finetuned model from scratch (don't forget this, it's important!).
-
Load the data for the per-speaker split. Compute non-finetuned model WER on this data.
-
Finetune the model on this split.
-
Measure WER + find most frequently misheard digits (print outputs vs. labels and compare manually).
Files to include in your merge request
- Your completed code for the finetuning, prediction and WER measurement in either
hw10/hw10.pyorhw10/hw10.ipynb-- only one of these is needed, not both :-). - A Markdown file
hw10/README.md, which should contain:- Your WER for four settings:
- Random split, non-finetuned model
- Random split, finetuned model
- Per-speaker split, non-finetuned model
- Per-speaker split, finetuned model
- A short report -- please try to explain:
- why the WER results ended up the way they did,
- which digits are most difficult to recognize for the per-speaker finetuned model and why.
- Your WER for four settings:
Notes
-
Make sure to use the version of Wav2vec2 that's also been pretrained on labeled audio (Wav2vec2-base-960h), not the unsupervised pretrained only version (Wav2vec2-base).
-
There's a known issue with one of the required libraries, Librosa, on Windows. You should not install the library system wide (and use a Virtualenv instead), or you should run your code with admin rights to avoid the issue.
11. Grapheme-to-phoneme conversion
Presented: 4 May, Deadline: 21 May
This time, your task will be to create a grapheme-to-phoneme conversion that works with the MBROLA concatenative speech synthesis system. By default, we'll assume you'll use Czech or English with this homework (only one of them, your choice :-)). If you want to try it out for a different language instead, we're open to that, but please talk to us first and check if MBROLA supports it.
Requirements
-
Install MBROLA. On Debian-based Linuxes, this should be as simple as
sudo apt install mbrola. Building for any other Linux shouldn't be too hard either. On Windows, you can use WSL, or you can get native Windows binaries here. If you have a Mac, you'll most probably need to use the MS computer lab where MBROLA is installed (but you'll need to download the voices yourself). -
Install a MBROLA voice for your language. On Debian-derivatives (incl. WSL), you can go with
sudo apt install mbrola-<voice>and your voices will into/usr/share/mbrola, otherwise you just need to download the voice somewhere.-
For Czech, cz2 is a good voice, cz1 is lacking some rather common diphone combinations.
-
For English, you can go with en1.
You can try out that it's working by running MBROLA through one of the test files included with the voice. There's always a “test” subdirectory with some “.pho” files.
mbrola -e /path/to/cz2 path/to/test/some_file.pho output.wav -
-
Implement a simple normalization script. It should be able to expand numbers (just single digits) and abbreviations from a list.
- Ignore the fact that you sometimes need context for the abbreviations.
- Add the following abbreviations to your list to test it: Dr, Prof, kg, km, etc/atd.
-
Add a grapheme-to-phoneme conversion to your script that produces a phoneme sequence like this:
Czech:
a 100 h\ 50 o 70 j 50 _ 200English:
h 50 @ 70 l 50 @U 200 _ 200It's basically a two-column tab/space-separated file. The first column is a phoneme, the 2nd column denotes the duration in milliseconds.
The available phonemes for each language are defined in the voices' README files (cs, en). MBROLA uses the SAMPA phonetic notation. The
_denotes a pause in any language.Use the following simple rules for phoneme duration:
- Consonant – 50 ms
- Short vowel (any vowel without “:” in Czech SAMPA, any 1-character vowel in English SAMPA): stressed – 100 ms, unstressed – 70 ms
- Long vowel (vowels with “:” in Czech SAMPA, 2-character vowels in English SAMPA): stressed – 200 ms, unstressed – 150 ms
If you inspect the MBROLA test files or the description here, you'll see that there's an optional third column for voice melody, saying which way F0 should develop during each phoneme. For our exercise, we'll ignore it. It'll give you a rather robotic, but understandable voice. What you should do, though is:
- Add a 200 ms pause after each comma or dash.
- Add a 500 ms pause after sentence-final punctuation (full stop, exclamation or question mark).
- Do not add any pauses between words, since you also don't make them when speaking :-).
Finally, the actual grapheme-to-phoneme rules are very different for both languages.
-
For Czech, you can do almost everything by starting from ortography and applying some relatively simple rules.
- You should also add a dictionary for exceptions – include these 7 foreign words with their correct SAMPA pronunciations, to test that it works correctly: business, diesel, design, interview, Newton, pizza, revue
-
For English, you can't do without a dictionary. Use the CMU Pronouncing Dictionary, which you can find in
data/hw11/cmudict.dictin your repo if you update from upstream.- Since the dictionary uses Arpabet and you want SAMPA for MBROLA, you'll need to create an Arpabet-to-SAMPA mapping to use it.
- The dictionary has stress marks (“1”, “2”, “3” etc. after vowels, so you can treat vowels with “1” or “2” as stressed, the rest as unstressed).
- Let the system spell out any word that it doesn't find in the dictionary (get the pronunciation of each letter).
-
Take a random Wikipedia article (say, “article of the day”) in your target language, produce the g2p conversion for the first paragraph, then run MBROLA on it and save a WAV file.
Implementation notes
To make our tests easier, please include a function called g2p_czech(text) or g2p_english(text) depending on your target language,
which takes plain text on the input and outputs a list of tuples (sound, duration). For instance, for Speech., we get:
[('s', 50), ('p', 50), ('i:', 200), ('tS', 50), ('_', 500)].
Note that you can easily convert this to the target text format: '\n'.join([sound + '\t' + str(duration) for sound, duration in output]).
What to include in your merge request
Create a directory hw11/ and put into it:
hw11/tts_g2p.py-- Your normalization and grapheme-to-phoneme Python script that will take plain text input and outputs a MBROLA instructions file.- Make it read standard input and write to standard output. Use
if __name__ == '__main__'so we can import the file for testing yourg2p_<czech|english>function.
- Make it read standard input and write to standard output. Use
hw11/test.txt-- The text of the paragraph on which you tried your conversion system.hw11/test.pho-- Your script's output on the paragraph (the “.pho” file for MBROLA).hw11/test.wav-- Your resulting MBROLA-produced WAV file.
12. Retrieval chatbot
Presented: 11 May, Deadline: 28 May
This time, you will implement a basic information-retrieval-based chatbot. We'll just use TF-IDF for retrieval, with no smart reranking.
Requirements
-
We'll use the DailyDialog dataset (original web now defunct, data here, original paper here ). This is a dataset of basic day-to-day dialogues, so it's great for chatbots. It's already inclued in your repository, under
data/hw12. Have a look at the data format, it's not very hard to parse. -
Implement an IR chatbot module (recommended approach, alternatives and extensions welcome):
-
Load the DailyDialog data into memory so that you know which turn follows which. Use
data/hw12/dialogues_train.txtfor this. Note that you shouldn't load the file at every turn -- load it once in the constructor. Please use relative paths (see HW8 notes). -
From your data, create a Keys dataset, containing all turns in all dialogues except the last one. Then create a Values dataset, which always contain the immediately next turn for each dialogue.
- Say there's just 1 dialogue with 5 turns (represented just by numbers here). Keys should contain
[0, 1, 2, 3]and the corresponding Values are[1, 2, 3, 4].
- Say there's just 1 dialogue with 5 turns (represented just by numbers here). Keys should contain
-
Use TfidfVectorizer from Scikit-Learn as the main “engine”.
- Create a vectorizer object and call
fit_transformon the Keys set to train your matching TF-IDF matrix (store this matrix for later). Feel free to play around with this method's parameters, especially with thengram_range-- setting it slightly higher than the default(1,1)might give you better results.
- Create a vectorizer object and call
-
For any input sentence, what your chatbot should do is:
-
Call
transformon your vectorizer object to obtain TF-IDF scores. -
Get the cosine similarity of the sentence's TF-IDF to all the items in the Keys dataset.
-
Find the top 10 Keys' indexes using
numpy.argpartition(see the example here). Now get the corresponding top 10 Values (at the same indexes). Choose one of them at random and use it as output.- Instead of choosing at random, you could do some smart reranking, but we'll skip that in this exercise.
-
-
-
Integrate your chatbot into DialMonkey. Create a module inside
dialmonkey.policyand add a corresponding YAML config file. You can call itir_chatbot.- Note that you can create a config file where this module will be the only thing, essentially standing in for NLU, policy and NLG at the same
time. You just access the
dial.userinput and directly calldial.set_system_response().
- Note that you can create a config file where this module will be the only thing, essentially standing in for NLU, policy and NLG at the same
time. You just access the
-
Take the 1st sentence of the first 10 DailyDialog validation dialogues (
data/hw12/dialogues_validation.txt) and see what your chatbot tells you.
Files to include in your merge request
- Your chatbot module under
dialmonkey/policy/ir_chatbot.pyand your configuration file underconf/ir_chatbot.yaml. - The first 10 DailyDialog validation opening lines along with your chatbot's responses under
hw12/samples.txt.
Further reading
More low-level stuff on TF-IDF:
Homework Submission Instructions
All homework assignments will be submitted using a Git repository on MFF GitLab.
We provide an easy recipe to set up your repository below:
Creating the repository
- Log into your MFF gitlab account. Your username and password should be the same as in the CAS, see this.
- You'll have a project repository created for you under the teaching/NPFL123/2026 group. The project name will be the same as your CAS username. If you don't see any repository, it might be the first time you've ever logged on to Gitlab. In that case, Ondřej first needs to run a script that creates the repository for you (please let him know on Slack). In any case, you can explore everything in the base repository. Your own repo will be derived from this one.
- Clone your repository.
- Change into the cloned directory and run
git remote show origin
You should see these two lines:
* remote origin
Fetch URL: git@gitlab.mff.cuni.cz:teaching/NPFL123/2026/your_username.git
Push URL: git@gitlab.mff.cuni.cz:teaching/NPFL123/2026/your_username.git
- Add the base repository (with our code, for everyone) as your
upstream:
git remote add upstream https://gitlab.mff.cuni.cz/teaching/NPFL123/base.git
- You're all set!
Submitting the homework assignment
- Make sure you're on your master branch
git checkout master
- Checkout a new branch -- make sure to name it hwX (e.g. “hw4” or “hw11”) so our automatic checks can find it later!
git checkout -b hwX
-
Solve the assignment :)
-
Run the automatic tests. Your code doesn't have to pass all the tests, but it shouldn't crash them. If it crashes the tests, you won't get any points or feedback. If you think the problem is the tests and not your code, let us know.
python run_tests.py hwX
- Add new files and commit your changes -- make sure to name your files as required, or you won't pass our automatic checks!
git add hwX/solution.py
git commit -am "commit message"
- Push to your origin remote repository:
git push origin hwX
-
Create a Merge request in the web interface. Make sure you create the merge request into the master branch in your own forked repository (not into the upstream).
Merge requests -> New merge request

-
Wait a bit till we check your solution, then enjoy your points :)! Please do not delete your
hwXbranch at this point so we can find it. You can merge thehwXbranch into your master branch if you need the code for the following assignments, but please do not delete it completely. -
Once you get your points, you can safely merge your changes into your master branch, if you haven't done it before, and delete the
hwXbranch.
Updating from the base repository
You might need to update from the upstream base repository every once in a while (most probably before you start implementing each assignment). We'll let you know when we make changes to the base repo.
To upgrade from upstream, do the following:
- Make sure you're on your master branch
git checkout master
- Fetch the changes
git fetch upstream master
- Apply the diff
git merge upstream/master master
Exam Question Pool
The exam will have 10 questions, mostly from this pool. Each counts for 10 points. We reserve the right to make slight alterations or use variants of the same questions. Note that all of them are covered by the lectures, and they cover most of the lecture content. In general, none of them requires you to memorize formulas, but you should know the main ideas and principles. See the Grading tab for details on grading.
Introduction
- What's the difference between task-oriented and non-task-oriented systems?
- Describe the difference between closed-domain, multi-domain, and open-doman systems.
- Describe the difference between user-initiative, mixed-initiative, and system-initiative systems.
Linguistics of Dialogue
- What are turn taking cues/hints in a dialogue? Name a few examples.
- Explain the main idea of the speech acts theory.
- What is grounding in dialogue?
- Give some examples of grounding signals in dialogue.
- What is deixis? Give some examples of deictic expressions.
- What is coreference and how is it used in dialogue?
- What does Shannon entropy and conditional entropy measure? No need to give the formula, just the principle.
- What is entrainment/adaptation/alignment in dialogue?
Data & Evaluation
- What are the typical options for collecting dialogue data?
- How does Wizard-of-Oz data collection work?
- What is corpus annotation, what is inter-annotator agreement?
- What is the difference between intrinsic and extrinsic evaluation?
- What is the difference between subjective and objective evaluation?
- What are the main extrinsic evaluation techniques for task-oriented dialogue systems?
- What are some evaluation metrics for non-task-oriented systems (chatbots)?
- What's the main metric for evaluating ASR systems?
- What's the main metric for NLU (both slots and intents)?
- Explain an NLG evaluation metric of your choice.
- Why do you need to check for statistical significance (when evaluating an NLP experiment and comparing systems)?
- Why do you need to evaluate on a separate test set?
Natural Language Understanding
- What are some alternative semantic representations of utterances, in addition to dialogue acts?
- Describe language understanding as classification and language understanding as sequence tagging.
- How do you deal with conflicting slots or intents in classification-based NLU?
- What is delexicalization and why is it helpful in NLU?
- Describe one of the approaches to slot tagging as sequence tagging.
- What is the IOB/BIO format for slot tagging?
- What is the label bias problem?
- How can an NLU system deal with noisy ASR output? Propose an example solution.
Neural NLU & Dialogue State Tracking
- Describe an example of a neural architecture for NLU.
- How can you use pretrained language models in NLU?
- What is the dialogue state and what does it contain?
- What is an ontology in task-oriented dialogue systems?
- Describe the task of a dialogue state tracker.
- What's a partially observable Markov decision process?
- Describe a viable architecture for a belief state tracker.
- What is the difference between dialogue state and belief state?
- What's the difference between a static and a dynamiic state tracker?
- How can you use pretrained language models or large language models for state tracking?
Dialogue Policies
- What are the non-statistical approaches to dialogue management/action selection?
- Why is reinforcement learning preferred over supervised learning for training dialogue managers?
- Describe the main idea of reinforcement learning (agent, environment, states, rewards).
- What are deterministic and stochastic policies in dialogue management?
- What's a value function in a reinforcement learning scenario?
- What's the difference between actor and critic methods in reinforcement learning?
- What's the difference between model-based and model-free approaches in RL?
- What are the main optimization approaches in reinforcement learning (what measures can you optimize and how)?
- Why do you typically need a user simulator to train a reinforcement learning dialogue policy?
Neural Policies & Natural Language Generation
- How do you involve neural networks in reinforcement learning (describe a Q network or a policy network)?
- What are the main steps of a traditional NLG pipeline – describe at least 2.
- Describe one approach to NLG of your choice.
- Describe how template-based NLG works.
- What are some problems you need to deal with in template-based NLG?
- Describe a possible neural networks based NLG architecture.
- How can you use pretrained language models or large language models in NLG?
Voice assistants & Question Answering
- What is a smart speaker made of and how does it work?
- Briefly describe a viable approach to question answering.
- What is document retrieval and how is it used in question answering?
- What is dense retrieval (in the context of question answering)?
- How can you use neural models in answer extraction (for question answering)?
- How can you use retrieval-augmented generation in question answering?
- What is a knowledge graph?
Dialogue Tooling
- What is a dialogue flow/tree?
- What are intents and entities/slots?
- How can you improve a chatbot in production?
- What is the containment rate (in the context of using dialogue systems in call centers)?
- What is retrieval-augmented generation?
Automatic Speech Recognition
- What is a speech activity detector?
- Describe the main components of an ASR pipeline system.
- How do input features for an ASR model look like?
- What is the function of the acoustic model in a pipeline ASR system?
- What's the function of a decoder/language model in a pipeline ASR system?
- Describe an (example) architecture of an end-to-end neural ASR system.
Text-to-speech Synthesis
- How do humans produce sounds of speech?
- What's the difference between a vowel and a consonant?
- What is F0 and what are formants?
- What is a spectrogram?
- What are main distinguishing characteristics of consonants?
- What is a phoneme?
- What are the main distinguishing characteristics of different vowel phonemes (both how they're produced and perceived)?
- What are the main approaches to grapheme-to-phoneme conversion in TTS?
- Describe the main idea of concatenative speech synthesis.
- Describe the main ideas of statistical parametric speech synthesis.
- How can you use neural networks in speech synthesis?
Chatbots
- What are the three main approaches to building chitchat/non-task-oriented open-domain chatbots?
- How does the Turing test work? Does it have any weaknesses?
- What are some techniques rule-based chitchat chatbots use to convince their users that they're human-like?
- Describe how a retrieval-based chitchat chatbot works.
- How can you use neural networks for chatbots (non-task-oriented, open-domain systems)? Does that have any problems?
- Describe a possible architecture of an ensemble non-task-oriented chatbot.
- What do you need to train a large language model?
- What are some issues you may encounter when chatting to LLMs?
Course Grading
To pass this course, you will need to:
- Take an exam (a written test covering important lecture content).
- Do lab homeworks (various dialogue system implementation tasks).
Exam test
- There will be a written exam test at the end of the semester.
- There will be 10 questions, we expect 2-3 sentences as an answer, with a maximum of 10 points per question.
- To pass the course, you need to get at least 50% of the total points from the test.
- We plan to publish a list of possible questions beforehand.
In case the pandemic does not get better by the exam period, there will be a remote alternative for the exam (an essay with a discussion).
Homework assignments
- There will be 12 homework assignments, introduced every week, starting on the 2nd week of the semester.
- You will submit the homework assignments into a private Gitlab repository (where we will be given access).
- For each assignment, you will get a maximum of 10 points.
- All assignments will have a fixed deadline.
- If you submit the assignment after the deadline, you will get:
- up to 50% of the maximum points if it is less than 2 weeks after the deadline;
- 0 points if it is more than 2 weeks after the deadline.
- Once we check the submitted assignments, you will see the points you got and the comments from us as comments on your merge requests on Gitlab.
- You need to get at least 50% of the total assignments points to pass the course.
- You can take the exam even if you don't have 50% yet (esp. due to potential delays in grading), but you'll need to get the required points eventually.
Grading
The final grade for the course will be a combination of your exam score and your homework assignment score, weighted 3:1 (i.e. the exam accounts for 75% of the grade, the assignments for 25%).
Grading:
- Grade 1: >=87% of the weighted combination
- Grade 2: >=74% of the weighted combination
- Grade 3: >=60% of the weighted combination
- An overall score of less than 60% means you did not pass.
In any case, you need >50% of points from the test and >50% of points from the homeworks to pass. If you get less than 50% from either, even if you get more than 60% overall, you will not pass.
No cheating
- Cheating is strictly prohibited and any student found cheating will be punished. The punishment can involve failing the whole course, or, in grave cases, being expelled from the faculty.
- Discussing homework assignments with your classmates is OK. Sharing code is not OK (unless explicitly allowed); by default, you must complete the assignments yourself.
- All students involved in cheating will be punished. E.g. if you share your assignment with a friend, both you and your friend will be punished.
Recommended Reading
You should pass the course just by following the lectures, but here are some hints on further reading. There's nothing ideal on the topic as this is a very active research area, but some of these should give you a broader overview.
Basic (good and up-to-date, but very brief, available online):
- Jurafsky & Martin: Speech & Language processing. 3rd ed. draft (chapters 14-16 in Jan 2025 version; chaps. 11, 14-16, 25, app. K in the current version).
More detailed (very good but slightly outdated, available as e-book from our library):
- McTear: Conversational AI: Dialogue Systems, Conversational Agents, and Chatbots. Morgan & Claypool 2021.
Further reading (mostly outdated but still informative):
- Yi et al.: A Survey of Recent Advances in LLM-Based Multi-turn Dialogue Systems. ACM Computing Surveys 2025.
- up-to-date but focuses only on latest models, pretty advanced
- Janarthanam: Hands-On Chatbots and Conversational UI Development. Packt 2017.
- practical guide on developing dialogue systems for voice bot platforms, virtually no theory
- Gao et al.: Neural Approaches to Conversational AI. arXiv:1809.08267
- an advanced, good overview of basic neural approaches in dialogue systems
- McTear et al.: The Conversational Interface: Talking to Smart Devices. Springer 2016.
- practical, more advanced and more theory than Janarthanam
- Jokinen & McTear: Spoken dialogue systems. Morgan & Claypool 2010.
- good but outdated, some systems very specific to particular research projects
- Rieser & Lemon: Reinforcement learning for adaptive dialogue systems. Springer 2011.
- advanced, outdated, project-specific
- Lemon & Pietquin: Data-Driven Methods for Adaptive Spoken Dialogue Systems. Springer 2012.
- ditto
- Skantze: Error Handling in Spoken Dialogue Systems. PhD Thesis 2007, Chap. 2.
- good introduction into dialogue systems in general, albeit dated
- McTear: Spoken Dialogue Technology. Springer 2004.
- good but dated
- Psutka et al.: Mluvíme s počítačem česky. Academia 2006.
- virtually the only book in Czech, good for ASR but dated, not a lot about other parts of dialogue systems
