Institute of Formal and Applied Linguistics
Charles University, Czech Republic
Faculty of Mathematics and Physics
ForFun 1.0
Online: https://ufal.mff.cuni.cz/~bejcek/ForFun-1.0
Download: http://hdl.handle.net/11234/1-2542
Prague Database of Forms and Functions
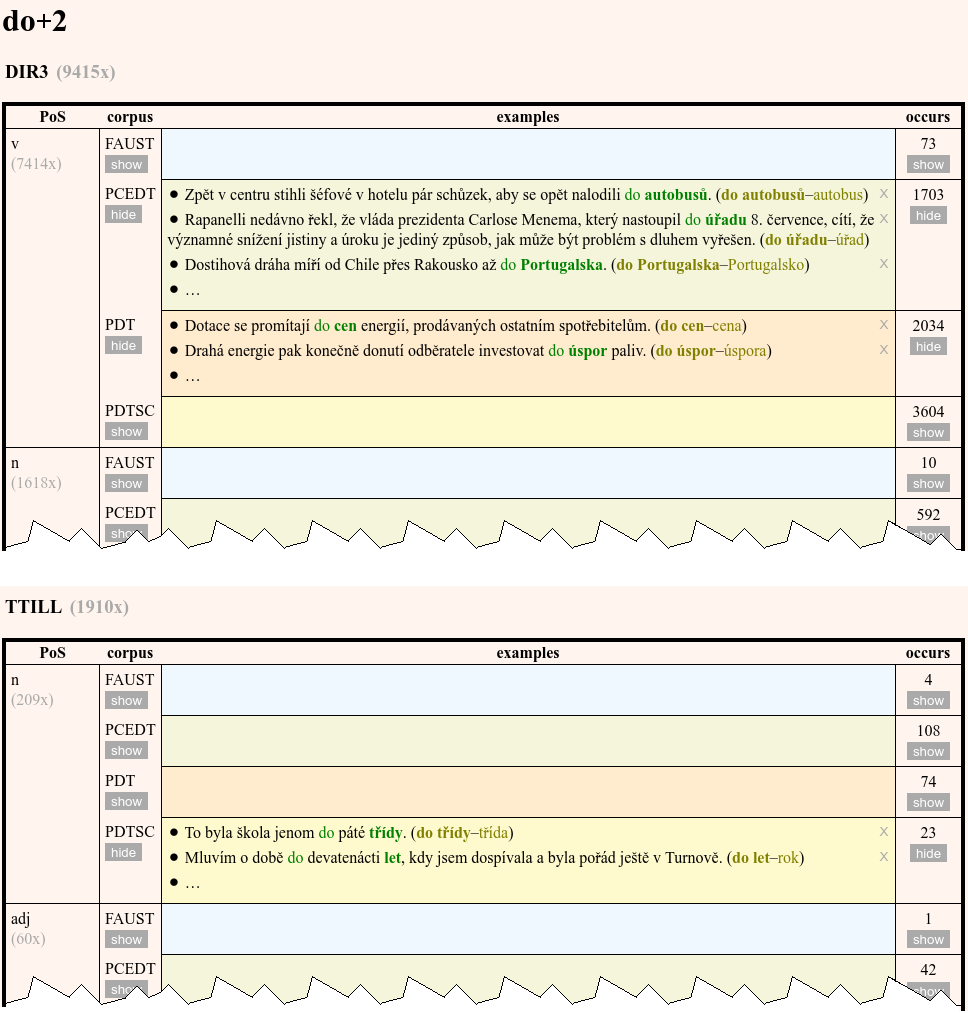
ForFun is an interface for various linguistic research, particularly in describing syntactic functions and their formal realizations in Czech sentences. ForFun draws on the complex linguistic annotation of Prague Dependency Treebanks (PDTs) and arranges morphological and syntactical annotation into new tool which gives a possibility to search quickly and in a user-friendly way all forms (almost 1,500 items) used in PDTs for particular function and vice versa to look up all functions (66 items) expressed by the particular forms.
1. “From function to form” and “from form to function”
The ForFun database is split into two interconnected but reversed sets. The “from function to form” set contains a list of all syntactic functions (see below 3).
When choosing one function type, the user can search for examples of all forms that may represent that function according to various criteria. These criteria consist of
- the word-class of a parent node,
- the particular forms of the function, and
- the source of text data (written, spoken, translated texts and texts from internet users).
The number of examples available in the database is always shown for each specified 4‑combination (given form, functor, word class and source). Either first ten of them or all examples are displayed on demand.
The “from form to function” set contains a long list (almost 1,500 items) of all formal realizations of particular sentence units that occur in PDTs (see below 3). For any form, there are again plenty of examples sorted by function, word-class of the parent node, and the source of text data, always with the frequency of the 4‑combination in the data.
In both sets, examples can be also first filtered by their source, which allows the user to hide e.g. all forms used only in spoken language.
2. Functions
Since the database is extracted from the PDTs, it takes over the list of syntactic functions as well as the terminology. They are called functors. Functors (66 items) represent the semantic values of syntactic dependency relations; they express the functions of individual modifications in the sentence.
For more details, see full list of all dependency functions and their descriptions and labels.
3. Forms
The forms (almost 1,500 items) that occur in PDTs are of the following types (with the following notations):
-
noun or nominal group in a morphological case is indicated by #-mark and a number:
#1 Nominative #2 Genitive #3 Dative #4 Accusative #5 Vocative #6 Locative #7 Instrumental -
other phrases:
#adv adverb #vfin finite verb #vinf infinitive verb #X unspecified part of speech #0 ellipsis (added node in the PDTs-representation) -
combination with a function word (i.e. preposition, conjunction) is indicated in the form: [function word]#1/2/3/4/5/6/7/X/0/vfin/vinf/adv
If the function word have more than one part (word/token), these parts are connected by _ underscore character, e.g. bez_ohledu_na.
4. Governing nodes
We note the following types of the governing nodes:
| v | verb |
| a | adjective |
| n | noun |
| adv | adverb |
| --- | no parent node |
| 0 | parent node has no word class assigned |
5. Sources
The ForFun database is constituted on the four PDTs corpora:
- PDT — Prague Dependency Treebank 3.0
- PCEDT — Prague Czech-English Dependency Treebank 2.0
- PDTSC — Prague Dependency Treebank of Spoken Czech 2.0
- FAUST — FAUST PDT-treebank
6. How to cite:
Mikulová Marie, Bejček Eduard: ForFun 1.0: Prague Database of Syntactic Forms and Functions — An Invaluable Resource for Linguistic Research. In: Proceedings of the 11th International Conference on Language Resources and Evaluation (LREC 2018), Copyright © European Language Resources Association, Miyazaki, Japan, France, 2018.
Mikulová Marie, Bejček Eduard: ForFun 1.0. Data/software, http://hdl.handle.net/11234/1-2542. Charles University, Prague, Czech Republic, Dec 2017.
7. References
You can read more in these papers:
- Slovko 2017: Mikulová Marie, Bejček Eduard, Kolářová Veronika, Panevová Jarmila: Subcategorization of Adverbial Meanings Based On Corpus Data. In: Jazykovedný časopis / Journal of Linguistics, Vol. 68, No. 2, Copyright © SAP – Slovak Academic Press, ISSN 0021-5597, pp. 268-277, 2017.
- TLT 2018: Bejček Eduard, Hajičová Eva, Mikulová Marie, Panevová Jarmila: The Relation of Form and Function in Linguistic Theory and in a Multi-layer Treebank. In: Proceedings of the 16th International Workshop on Treebanks and Linguistic Theories, Copyright © Univerzita Karlova, Praha, Czechia, 2018. (in press)
- CRH 2018: Mikulová Marie, Bejček Eduard, Panevová Jarmila: What Can We Find Out about Time and Space in the ForFun Database? In: Proceedings of the 2nd Workshop on Corpus-based Research in the Humanities (CRH) with a special focus on space and time annotations, Vienna, Austria, 2018. (in press)
- LREC 2018: Mikulová Marie, Bejček Eduard: ForFun 1.0: Prague Database of Syntactic Forms and Functions — An Invaluable Resource for Linguistic Research. In: Proceedings of the 11th International Conference on Language Resources and Evaluation (LREC 2018), Copyright © European Language Resources Association, Miyazaki, Japan, 2018.