


Český akademický korpus verze 1.0 je morfologicky ručně anotovaným korpusem češtiny o objemu cca 600 tisíc slov.
Český akademický korpus (ČAK) je projekt, který se svým průběhem a trváním zcela vymyká klasické představě o projektu. Hlavním předmětem projektu je morfologicky a syntakticky ručně anotovaný korpus čestiny, který vznikl před více než dvaceti lety v letech 1971-1985 jako podklad pro sestavení frekvenčního slovníku češtiny té doby – původně nesl zcela „věcný“ název Korpus věcného stylu. Nezávisle na korpusu ČAK byla v roce 1996 zahájena anotace Pražského závislostního korpusu (PZK). Při práci na jeho již druhé verzi [11] [1] se objevila myšlenka převést vnitřní formát a anotační schémata korpusu ČAK tak, aby byl zcela kompatibilní s PZK, tedy aby se dal přímo do PZK začlenit. Představovaná první verze korpusu ČAK je výsledkem převodu vnitřního formátu a morfologických anotací.
ČAK 1.0 nabízí
jazykovědcům-teoretikům datový materiál, který reflektuje reálné použití jazyka,
počítačovým lingvistům další data nezanedbatelného objemu, která by měla přispět ke zlepšení výsledků aplikací přirozeného jazyka, které se bez morfologického zpracování textů neobejdou,
pedagogům, jejich žákům a studentům zajímavou pomůcku do těch hodin češtiny, při kterých se procvičuje české tvarosloví.
Projekt ČAK pokračuje konverzemi syntaktických anotací do koncepce zvolené v PZK, které by měly vyústit vydáním druhé verze korpusu ČAK. Zároveň je plánováno přímé začlenění korpusu ČAK do PZK, čímž by se PZK obohatil nejen kvantitativně, ale i kvalitativně z pohledu začlenění typů textů, které v něm dosud nejsou obsaženy, konkrétně textů administrativního stylu a textů mluvených (přepisy mluvených projevů).
Dokumenty v ČAK jsou nezkrácené články z širokého spektra novin a časopisů a nezkrácené přepisy mluvené řeči z řady rozhlasových a televizních pořadů, a to z oblasti novinářské, vědecké a administrativní. Texty pocházejí ze 70. a 80. let 20. století. Výběr textů byl přirozeně ovlivněn dobou; první publicistický text příznačně pocházel z Rudého práva. Dobový pohled ovlivnil i výběr některých naučných textů (např. Ke kritice buržoasních teorií společnosti, Vědeckotechnická revoluce a socialismus). Naštěstí se dostalo i na tituly a obory dobou neovlivněné (např. Jak rozumíme chemickým vzorcům a rovnicím, Hvězdářská ročenka). Úplný výčet použitých zdrojů je uveden v příloze A.
O anotovaném korpusu se nedá hovořit, aniž by se specifikovalo, čeho se anotace týkají. Jinými slovy, z pohledu jazykovědné teorie, musí se specifikovat tzv. rovina anotace. Původní anotace ČAK pokrývají dvě roviny – morfologickou a povrchově syntaktickou. Vzhledem k tomu, že ČAK 1.0 je výsledkem konverze původního vnitřního formátu a původních morfologických anotací, hovoříme v jeho případě pouze o jedné rovině anotací, a to o rovině morfologické. Abychom byli úplně korektní vzhledem k vnitřnímu formátu ČAK 1.0 (viz kapitola 3, oddíl 3.2.1), musíme doplnit, že operujeme ještě s jednou rovinou, a to s rovinou slovní. Slovní rovina je ve skutečnosti rovinou neanotační (pro pohodlí o ní budeme nadále hovořit jako o rovině anotační), obsahuje pouze původní text rozdělený na slovní jednotky (slova, čísla zapsaná ciframi, interpunkce), popř. dokumenty a odstavce. Slovním jednotkám jsou přiřazeny jednoznačné identifikátory. Věty nebyly zmíněny zcela záměrně, protože slovní rovina neobsahuje segmentaci textu na věty; ta je až na morfologické rovině. Nadále budeme slovní rovinu zkráceně označovat jako w-rovinu (z anglického word) a morfologickou rovinu jako m-rovinu.
Anotace na m-rovině znamená, že slovním jednotkám textu jsou přiřazovány údaje (anotace), které charakterizují jejich morfologické vlastnosti, tedy lemma (základní tvar slova), slovní druh a morfologické kategorie (pád, číslo, čas, osoba, ...). Formálně jsou slovní druhy společně s morfologickými kategoriemi reprezentovány jako znakové řetězce, tzv. morfologické značky nebo také tagy. V ČAK 1.0 jsou použity značky navržené v PZK jako řetězce pevné délky, a to délky 15 znaků, kde každá pozice jednoznačně odpovídá právě jedné kategorii – hovoříme o tzv. pozičních značkách; jejich popis je vložen do průvodce ve formě zataveného listu.
Příklad: Slovní forma Prahu se analyzuje jako afirmativní (11. pozice) substantivum (1. a 2. pozice) ženského rodu (3. pozice) ve tvaru akuzativu (5. pozice) singuláru (4. pozice). Na všech ostatních pozicích je správně symbol „-“, který signalizuje nerelevantnost příslušné morfologické kategorie danému slovnímu druhu. Například u substantiv se neurčuje osoba (8. pozice).
Tabulka 2.1. Příklady lemmat a značek
| slovní jednotka | lemma | značka | popis |
|---|---|---|---|
| Prahu | Praha | NNFS4-----A---- |
substantivum, femininum, singulár, akuzativ, afirmativum |
| 123 | 123 | C=------------- |
číslovka zapsaná číslicemi |
| ) | ) | Z:------------- |
interpunkční znaménko (pravá kulatá závorka) |
Koncepce vnitřního formátu ČAK 1.0 zachází s anotacemi na rovinách odděleně, tj. každé rovině anotace dokumentu odpovídá jeden soubor. Vztaženo na ČAK 1.0 to znamená, že pro každý dokument existují dva soubory, jeden pro w-rovinu a druhý pro m-rovinu. Nicméně zmíněná oddělenost neznamená, že soubory pro jednotlivé roviny anotace nejsou propojené. Jak vzápětí ukážeme, je tomu právě naopak.
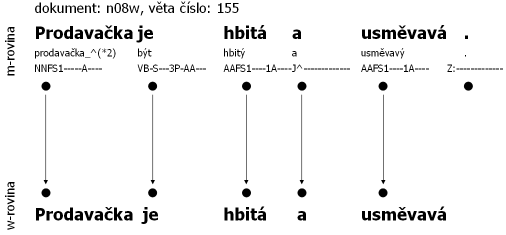
Jak už bylo naznačeno výše, text je segmentován do vět až na m-rovině. To znamená, že m-rovina obsahuje navíc oproti w-rovině koncovou (větnou) interpunkci. Kromě toho se může lišit i počet slovních jednotek na obou rovinách, což může znamenat spojení nesprávně rozdělených slova do jednoho nebo naopak rozdělení omylem spojených slov do více jednotek. Na m-rovině už by měl být správně napsaný text.
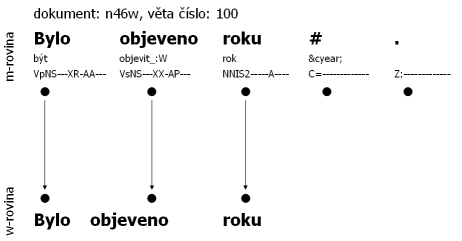
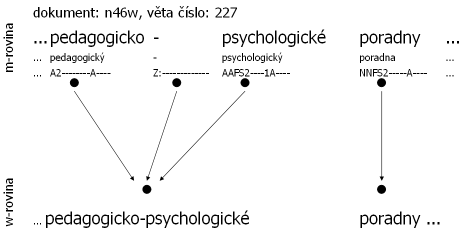
Příklad: Následující tři obrázky dokládají propojenost rovin, tedy i souborů, ve smyslu počtu slovních jednotek (propojenost naznačují šipky). Všechny tři příklady jsou úmyslně vybrány z ČAK 1.0, aby mohl uživatel přímo nahlédnout do souborů (pro každou větu je uveden název dokumentu a číslo věty). Obrázek 2.1 ilustruje poměr 1:1 – až na koncovou interpunkci se roviny neliší. Obrázek 2.2 ilustruje situaci, kdy byla do textu vložena slovní jednotka – zde evidentně v textu chybělo určení roku. Pro korektora bylo téměř nemožné doplnit konkrétní rok, proto je uveden symbol „#“, který nemá svůj „protipól“ na w-rovině. Naopak obrázek 2.3 ilustruje situaci, kdy více jednotek m-roviny má stejný „protipól“ na w-rovině – slovní jednotka pedagogicko-psychologické je rozdělena na tři samostatné jednotky.
Myšlenka Českého akademického korpusu byla realizována v letech 1971-1985 v oddělení matematické lingvistiky v Ústavu pro jazyk český ČSAV pod vedením Marie Těšitelové. Myšlenku soustředit nový textový materiál, který již nebude tříděn ručně, ale pomocí techniky, přinesla její práce na rozsáhlém díle Frekvence slov, slovních druhů a tvarů v českém jazyce (Jelínek, Bečka, Těšitelová, 1961). Technikou v té době byly myšleny samočinné počítače s děrnými štítky (jmenovitě sálové počítače IBM 370 a Tesla 200). V diskusi o pojetí akademické mluvnice češtiny padla volba na tradiční, systematicky dobře propracované pojetí morfologie a závislostní syntaxe (Šmilauer, 1972).
Rukopisné zdroje textů zůstaly po nějaký čas v archivu, ale vzhledem k opadání zájmu o ně byly nakonec zlikvidovány (naneštěstí, jak se později ukázalo). Naštěstí elektronická podoba ČAK dokázala úspěšně držet krok s rychlým technickým pokrokem, se změnami formátu záznamu a archivačních nosičů. Proto mohl být ČAK v roce 1994 použit pro první experimenty morfologického značkování českých textů s využitím označkovaného korpusu (Hladká, 1994). Experimenty byly provedeny v Ústavu formální a aplikované lingvistiky Matematicko-fyzikální fakulty Univerzity Karlovy a ukázaly se jako zásadní z pohledu dalšího vývoje české komputační lingvistiky.
Rekapitulaci dění v letech, kdy se do korpusu ČAK nesměly zahrnout texty o délce dva tisíce slov, kdy se ČAK anotoval modře a červeně na papíře a kdy se „přehazoval“ z děrných štítků na magnetické pásky, je věnována část souhrnného příspěvku (Hladká, Králík, 2006).
Pokračování projektu Českého akademického korpusu bylo zásadně ovlivněno Pražským závislostním korpusem (PZK), jehož anotace pokrývají tři roviny – morfologickou, analytickou (povrchově-syntaktickou) a tektogramatickou (rovinu větného významu). Náročnost anotování na jednotlivých rovinách se odráží v objemu dat, která byla na těchto rovinách anotována. Největší objem dat, 2 mil. slov, je anotován pouze morfologicky. 1,5 mil. slov je anotován navíc i povrchově-syntakticky a z nich je 800 tis. slov anotováno tektogramaticky. Zkušenost získaná při anotování tak velkého objemu dat v tak komplexním pohledu je natolik ojedinělá a poučná, že měla důvod stát se jedním z hlavních motivů pro pokračování projektu ČAK.
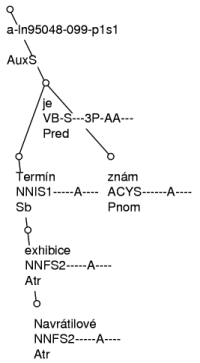
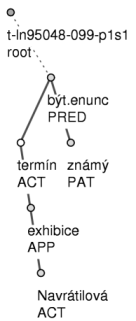
Příklad: Z PZK verze 2.0 jsme vybrali větu Tímto je termín exhibice Navrátilové znám. Obrázky 2.4 a 2.5 ukazují anotace této věty na všech třech rovinách. Na obrázku 2.4 je syntaktická anotace (větný rozbor, kterému odpovídá stromová struktura ohodnocená analytickými funkcemi) spolu s anotací morfologickou. Obrázek 2.5 ukazuje anotaci tektogramatickou, jedná se o stromovou strukturu ohodnocenou funktory. Pokud čtenáře stromečky zaujaly, doporučujeme nahlédnout do pokynů, kterými se řídilo anotování PZK 2.0 (Hana, Zeman, 2005, Hajič a kol., 2004, Mikulová a kol., 2006).
Pokračování projektu ČAK bylo rozplánováno do tří etap v celkové délce pěti let. Vzhledem k již zmíněným zkušenostem bylo možné sestavit poměrně podrobný plán a odhadnout časovou náročnost dílčích kroků spolu s potřebnou pracovní kapacitou. V okamžiku vydávání CD-ROM ČAK 1.0, dva roky od zahájení, jsou cíle prvních dvou etap (konverze vnitřního formátu a morfologických anotací) dosaženy. Výčtem shrneme ony dílčí kroky, podrobnosti jsou k nalezení v (Hladká, Králík, 2006).
Konverze vnitřního formátu: Převedení původního jednoduchého textového formátu typu CVS (comma-separated values) do formátu csts [9] založeného na světovém standardu SGML [16].
Automatická konverze morfologických anotací: Převedení původního anotačního morfologického schématu do pozičních morfologických značek. Mapování i všechny následné kontroly a zpracování jejich výsledků bylo realizováno v souladu s pokyny formulovanými pro morfologickou anotaci PZK (Hana, Zeman, 2005).
Ruční doplnění chybějících anotací: Pokud se stalo, že morfologická analýza určitou slovní jednotku nedokázala analyzovat, doplnily se anotace k dané slovní jednotce ručně.
-
Korektury textů: Čísla zapsaná číslicemi a interpunkce byly z ČAK hned na samém počátku anotace vypuštěny (z textu byla vypuštěna slova, která „se čtou jinak, než se píšou“ (25 vs. dvacetpět), nebo se vůbec „nečtou“ (interpunkce)). Z pohledu aplikací přirozeného jazyka se jedná o natolik zásadní nedostatek, že bylo nutné ho vhodným způsobem řešit. Vzhledem k absenci rukopisných zdrojů textů (jak již bylo vzpomenuto výše) se nabízelo řešení formou korektur, což znamenalo přečíst všechny dokumenty ČAK a vyznačit místa, kam dle korektora patří interpunkční znaménko nebo číslo. U čísel se navíc rozlišovalo, zda se jedná o specifikaci množství, o rok, datum či výčet. Pokud ani jedna z nabízených možností neodpovídala kontextu, měl korektor možnost volby nespecifikované kategorie. Nastala-li situace, že přicházelo v úvahu více možností, korektor vybral všechny relevantní. Zároveň měli korektoři označit ta místa ve větách, která jim z nějakého důvodu připadala nesrozumitelná (např. podivný pořádek slov ve větě, chybějící slovo).
Abychom uživatele upozornili na jevy, které do textu vložili korektoři, uvádíme je v následujícím výčtu jmenovitě. Dále předkládáme několik vět, ve kterých zmíněné jevy ilustrujeme. Nabádáme uživatele, aby sami zkusili nahradit otazníky něčím smysluplnějším. U každé věty je specifikováno, v jakém dokumentu se vyskytuje. Při nahlédnutí přímo do dokumentu může být nahrazování snadnější.
Příklad:Vložená čísla psaná číslicemi:
slovo=#,lemma=&camount;(množství),lemma=&clabel;(výčet),lemma=&cyear;(rok),lemma=&cdate;(datum),lemma=&cother;(jiné),značka=C=-------------Nesrozumitelné situace:
slovo=?,lemma=?,značka=Xx-------------.
(n31w, <s id="n31w.m-s100">) Akce # jarních ? bude zahájena # března .
(a02w, <s id="a02w.m-s5">) Správa domu je povinna zajistit uživateli bytu plný a nerušený výkon jeho práv spojených s ? bytu .
(a06w, <s id="a06w.m-s64">) Na ? bude pokračováno v roce # , zimním poloprovozem má býti odzkoušena účinnost na instalovaném poloprovozním zařízení při nízkých teplotách .
(a06w, <s id="a06w.m-s192">) V souvislosti ? projednáváním plánu na rok # probíhá na závodech zároveň příprava nových kolektivních smluv na rok # , o které se již hovořilo na celopodnikové konferenci ROH # září .
(a06w, <s id="a06w.m-s131">) V dalším programu ? Suchomel přednesl hlavní obsah referátu ? Muchy o energetické situaci , která i pro ? je značně napnuta .
(a12w, <s id="a12w.m-s107">) Pokud má topidlo ustavovací nožičky a nebude teplota větší jak # ? , nemusí býti pod ním asbestová deska .
Ruční revize korektur: Zpracování nesrovnalostí mezi korektory.
Konverze vnitřního formátu: Převedení vnitřního formátu csts do PML [10].
Závěrečná revize morfologických anotací: I přes snahu napsat převody z původního formátu dat a původního anotačního schématu co nejlépe a přes veškeré úsilí ručních anotátorů a korektorů zůstaly v datech nevyhnutelně nějaké chyby. Pro jejich odhalování byly použity částečně automatické kontrolní skripty. Pomocí nástrojů Netgraph [20] a TrEd/btred/ntred [22] byla v datech vyhledávána místa, kde mohlo dojít k porušení nějakého pravidla anotace nebo pravidla gramatiky. Podezřelá místa pak byla ručně kontrolována a podle povahy chyb ručně nebo automaticky opravována. Konkrétní vyhledávané jevy (potenciální chyby) byly zčásti převzaty z obdobných kontrol prováděných na PZK 2.0, zčásti vymyšleny během práce na datech ČAK 1.0.
Navzdory několikanásobným kontrolám anotací jsme si vědomi, že se v anotacích i nadále vyskytují chyby (laskavě žádáme uživatele o shovívavost). Jejich kvantitu nedovedeme dost dobře odhadnout, většinou se jedná o chyby, které v rámci kontrol na jedné rovině (tak, jak jsme je prováděli my) není možné odhalit. Jejich odhalování přijde na řadu v okamžiku, kdy bude dokončena konverze syntaktických anotací a kdy kontroly anotací na obou rovinách budou realizovány společně.
Příklad: Je-li k dispozici větný rozbor věty, je možné kontrolovat shodu podmětu (holého) s přísudkem. Slova anotovaná jako podmět a přísudek musí mít ve svých morfologických značkách na pozicích rodu a čísla stejné hodnoty, aby byla naplěnana shoda podmětu s přísudkem.
V tabulkách 2.2 a 2.3 jsou souhrnně uvedeny kvantitativní charakteristiky korpusu ČAK 1.0. Ještě podrobnější údaje jsou uvedeny dále v tabulce 3.5.
Tabulka 2.2. Kvantitativní charakteristiky ČAK 1.0
| styl | forma zdroje | počet souborů | počet vět | počet slovních jednotek |
|---|---|---|---|---|
| publicistický | psaná | 52 | 10 234 | 189 435 |
| publicistický | mluvená | 8 | 1 433 | 28 737 |
| odborný | psaná | 68 | 11 113 | 245 175 |
| odborný | mluvená | 32 | 4 576 | 115 853 |
| administrativní | psaná | 16 | 3 362 | 58 697 |
| administrativní | mluvená | 4 | 989 | 14 235 |
| celkem | psaná | 136 | 24 709 | 493 307 |
| celkem | mluvená | 44 | 6 998 | 158 825 |
| celkem | psaná a mluvená | 180 | 31 707 | 652 132 |
Tabulka 2.3. Kvantitativní charakteristiky ČAK 1.0 – vložené symboly
| styl | forma | počet výskytů '#' (v počtu vět) | počet výskytů '?' (v počtu vět) | počet výskytů '#' nebo '?' (v počtu vět) | počet vět bez '#' nebo '?' |
|---|---|---|---|---|---|
| publicistický | psaná | 1 769 (1 187) | 925 (680) | 2 694 (1 563) | 8 671 |
| publicistický | mluvená | 5 (5) | 25 (25) | 30 (30) | 1 403 |
| odborný | psaná | 2 149 (1 222) | 2 230 (1 418) | 4 379 (2 030) | 9 083 |
| odborný | mluvená | 9 (9) | 131 (108) | 140 (113) | 4 463 |
| administrativní | psaná | 901 (611) | 635 (476) | 1 536 (915) | 2 447 |
| administrativní | mluvená | 0 (0) | 16 (15) | 16 (15) | 974 |