


This section provides a visual representation of the directory structure contained on the CD up to the second, or third tier (see Table 3.1). Any references made to the content of the CD that reside deep within the tree structure utilize the full absolute path of the file. The contents of the data (data/), tools (tools/) and bonus material (bonus-tracks/) directories are thoroughly specified.
Table 3.1. Directory structure of CD-ROM CAC 1.0
../../cz/html/ |
# CAC guide Czech (html) | |||
index-en.html |
# CAC guide English (html) | |||
Install-on-Linux.pl |
# instalation script for Linux (English) | |||
Install-on-Windows.exe |
# installation program for MS Windows (English) | |||
Instaluj-na-Linuxu.pl |
# installation script for Linux (Czech) | |||
Instaluj-na-Windows.exe |
# installation program for MS Windows (Czech) | |||
bonus-tracks/ |
# special bonus | |||
|
# electronic exercise book of Czech | |||
data/ |
||||
|
# CAC 1.0 (files [ans][0-9][0-9][sw].[mw]) |
|||
|
# PML schemas | |||
doc |
||||
|
# CAC guide (Czech and English, pdf) | |||
tools/ |
# tools | |||
|
# corpus manager | |||
|
# lexical annotation workbench | |||
|
# automatic morphological treatment of Czech texts | |||
|
# running morphological analyser and/or tagger | |||
|
The next section describes CAC 1.0 naming conventions and the inner representation of instances.
PML (Prague Markup Language), is a generic XML-based data format designed for the representation of rich linguistic annotation of text. Each of the layers defines its own PML schema. PML was developed in concurrence with the annotation of PDT 2.0. The following text introduces a brief summary of the main characteristics of PML, detailed information can be found in the technical report (Pajas, Štěpánek, 2005).
In PML, individual layers of annotation can be stacked one over another in a stand-off fashion. These layers of annotation can be linked together as well as with other data sources in a consistent way. Each layer of annotation is described in a PML schema file, which could be imagined as a formalization of an abstract annotation scheme for the particular layer of annotation. The PML schema file describes which elements occur in that layer, how they are nested and structured, what the attribute types are for the corresponding values, and what role they play in the annotation scheme (this PML-role information can also be used by applications to determine an adequate way to present a PML instance to the user). Other formal schemata such as Relax NG can be automatically generated from a PML schema, so that formal consistency of PML-schema instances can be verified using conventional XML-oriented tools (a XSLT stylesheet providing conversion of PML schema to Relax NG is available in data/schemas/pmlSchema2RelaxNG/pml2rng.xsl. Table 3.2 illustrates part of the PML schema of the w-layer (data/schemas/pmlSchema2RelaxNG/pml2rng.xsl).
In the illustrated example, the paragraph (para, in case of CAC 1.0 the whole document) consists of an array of w-node.type elements.
This type is closely defined as a structure containing also obligatory elements: id (unambiguous identifier with role #ID) and token.
Table 3.2. PML schema of w-layer in CAC 1.0
|
<type name="w-para.type"> <sequence> <... <element name="w" type="w-node.type"/> </sequence> </type> <type name="w-node.type"> <structure name="w-node"> <member as_attribute="1" name="id" role="#ID" required="1"> <cdata format="ID"/></member> <member name="token" required="1"><cdata format="any"/> </member> <member name="no_space_after" type="bool.type"/> </structure> </type> ... |
Every PML instance begins with a head tag followed by the PML schema. The header contains reference to all external sources that are being referred to from this instance together with some additional information necessary for correct link resolving. The rest of the instance is dedicated to the annotation itself. Table 3.3 provides an example of a PML schema (mdata_schema.xml) and the appropriate instance within the w-layer (a01w.w) being linked to part of the head of the instance of the m-layer (a01w.m).
Table 3.3. Part of the header of the instance of the m-layer a01w.m
| <head>
<schema href="mdata_schema.xml" /> <references> <reffile id="en_w" href="a01w.w" name="wdata" /> </references> </head> ... |
Annotation is expressed by XML elements and attributes, named and used in conformity with the particular PML schema. Table 3.4 illustrates an instance of annotation at the beginning of the sentence and the first word of the sentence on the m-layer of the instance a01w.m. The opening tag of the element s contains an identifier of the whole sentence followed by the opening tag of the element m which contains an identifier to the annotation wesponding to the token of the w-layer that is being referred to from the element w.rf. Other elements contain form (form), morphological tag (tag) and src.rf provides with a source of annotation, in this case manually:
Table 3.4. Example of annotation of the instance a01w.m
| <s id="en_m-a01w-s1">
<m id="en_m-a01w-s1W1"> <w.rf>w#w-a01w-s1W1</w.rf> <form>Federální</form> <tag> <lemma>federální</lemma> <src.rf>manual</src.rf> </m> ... |
XML elements of a PML instance occupy a dedicated namespace found at: http://ufal.mff.cuni.cz/pdt/pml/ (it is not a meaningfull link, it is just a name of namespace). The PML format offers unified representations for the most common annotation constructs such as attribute-value structures, lists of alternative values of a certain type (either atomic or further structured), references within a PML instance, links among various PML instances (used in CAC 1.0 to create links across layers), and links to other external XML-based resources.
Each data file used in CAC 1.0 relates to one annotated document (annotated at one layer of annotation). The base of the file name contains a single letter that classifies the subject of the text contained in the file. For example, n indicates newspaper articles, s marks scientific texts, and a denotes administrative texts. Next, the file name specifies a two-digit ordinal number of the document within the group of documents of the same style. Following this two-digit number, a letter indicates if the text is derived from written text (letter w) or if it is a transcript of spoken language (letter s). The file names of the documents are included as identifiers of sentences and elements in these sentences. For example, Table 3.4. illustrates the formation of the qualified name a01w.m which indicates that the file is the first administrative text document and the originating source was from written text. Accordingly, this file name becomes part of the identifier in the PML schema in the tag <m id="en_m-a01w-s1W1">. Appendix A provides names of instances and files for particular documents.
Example: Instances carrying name according to template a[0-9][0-9]s* contain transcripts of the spoken language in an administrative style.
The filename extension expresses the layer of annotation (.w signifies the w-layer and m denotes the m-layer). The distinction and relationship between w-files and m-files is paramount. Each m-file has just one corresponding w-file. Each m-file contains links to the appropriate w-file (see above) but w-files do not explicitly link to the m-files. Due to this dependency, it is critical that files should not be renamed.
Example: s17w.m defines a file containing annotations in the m-layer of written document in the scientific style. Therefore, s17w.m contains links to its corresponding w-file s17w.w.
CAC 1.0 is composed of 180 manually annotated documents containing 31,707 sentences and 652,132 tokens as calculated from the m-files. Tokens without punctuation total 570,761 and tokens without punctuation and digit tokens reach 565,928. Table 3.5 states sizes of the individual parts of data according to style and form.
Table 3.5. Size of the parts of CAC 1.0 according to style and form
| style | form | number of docs | number of sentences | number of word tokens | number of word tokens w/o punctuation | number of word tokens w/o digit tokens |
|---|---|---|---|---|---|---|
| journalism | written | 52 | 10 234 | 189 435 | 165 469 | 163 700 |
| journalism | transcription | 8 | 1 433 | 28 737 | 24 864 | 24 859 |
| scientific | written | 68 | 11 113 | 245 175 | 216 281 | 214 132 |
| scientific | transcription | 32 | 4 576 | 115 853 | 100 281 | 100 272 |
| administrative | written | 16 | 3 362 | 58 697 | 51 431 | 50 530 |
| administrative | transcription | 4 | 989 | 14 235 | 12 435 | 12 435 |
| total | written | 136 | 24 709 | 493 307 | 433 181 | 428 362 |
| total | transcription | 44 | 6 998 | 158 825 | 137 580 | 137 566 |
| total | written and transcription | 180 | 31 707 | 652 132 | 570 761 | 565 928 |
Every experiment conducted on CAC 1.0 data made public should contain information about the data that was used to obtain the derived results.
Annotation of CAC 1.0 is divided into two layers: w-layer (word layer) and m-layer (morphological layer). Every layer
includes its own PML schema located in the directory structure (data/schemas/ files wdata_schema.xml,
mdata_schema.xml). The directory structure data/pml/ is composed of a total of 360 files, 180 w-files and 180 m-files.
The graphic tool Bonito simplifies tasks commonly associated with language corpora, especially searching and calculating basic statistics on the search results. Bonito is a system upgrade of the corpus manager Manatee, which conducts various operations on corpus data. A detailed documentation for the tool Bonito is included the application itself and can be launched from the main menu Help.
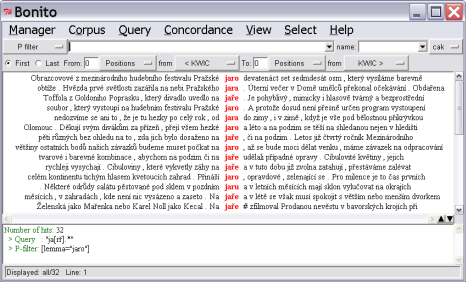
Figure 3.1 illustrates the main interface for the Bonito tool. The command of the tool is demonstrated in the preceding examples.

Footnotes for the Figure 3.1
1 Main Menu
2 Button for the selection of the corpus
3 Query box (New query)
4 Main window for display of results
5 Column with occurrences corresponding to the question
6 Concordance rows
7 Chosen Concordance rows
8 Window for display of query history and broader context.
9 Status bar
Users are often interested in which context words occur in the corpus. For example, a user may want to investigate the occurrence of the word jaro in different contexts. The user can put this word into window (3) (query box/new query) and press Enter. After submitting the query, the answer is displayed in the main window (4) in the form of the concordances where occurrences of the chosen word will be displayed in the contexts in the corpus. The displayed rows are referred to as concordances or concordance rows (6).
To generate more targeted concordances, the query can also be in the form of a simple regular expression. For example, all forms of the word jaro (“spring”) can be attained by entering the regular expression ja [rř].* (see Figure 3.1). The search will provide all the possible and required forms although some of the results may include undesirable word forms such as the adjective jarní (“springy”) or even the noun jarmark (“fair”). If the result set is not exceedingly large and contains just a few undesirable concordances, one can manually delete these concordances by selecting the rows with a left-button click of the mouse followed by the command button Concordance|Delete selected. One can also toggle a selected row between emphasized and un-emphasized (Select|Invert). The un-emphasized, or inverted, rows can then be deleted to create a more accurate result set.
One of the most advantageous methods to proliferate precise and appropriate results is to modify the query expression to accommodate only the forms that the user is interested in. For example, the previous regular expression can be modified to produce a more precise result set by using the query ja(ro|ra|ře|ru|rem|r|rech|ry). Since this format may prove to be unnecessarily complex in certain situations, the user can alternatively narrow the result with a P filter (positive filter) or N filter (negative filter). The filters can be selected by clicking on the button New query and selecting the desired filter. If the query jarn.+ is entered in the negative filter, all occurrences corresponding to the regular expression, in this case forms of the word jarní will be omitted from the concordance rows. In contrast to the negative filter, the user has the option of applying a positive P filter where the user simply enters the query lemma=”jaro”. The result will only display occurrences where attribute lemma equals the string “jaro” thus limiting the total number of concordances (see Figure 3.2). To keep track of recent queries, a query history is displayed in the lower window to help aid in developing the query expression and filter settings (box 8).
As is evident from the previous examples, it is possible to formulate increasingly complex queries and combine these values with all attributes that the corpus has defined. A list of the corpus attributes can be accessed by selecting the item Information Summary from the Corpus menu (see Figure 3.3).
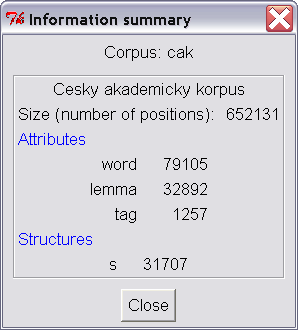
In the case of CAC 1.0, three attributes are empirically defined: word, lemma and morphological tag. The only implicit attribute that can be modified by the user is the attribute word. For this reason, it was sufficient in the previous example to submit on the word jaro into the query box without any specification of the attribute. The user can also employ a combination of attributes in the search. The following query [lemma=”jaro” & tag=”NNN.6.+“ & word=“j.+“] will return all occurrences for the lemma jaro that occur in locative (plural and singular since the position of number in the character is filled with full stop) and begin with a lowercase letter. The query for lemma will also search for occurrences of the lemma at the beginning of a sentence, something we could not do with the previous query.
The formation of optimal queries is paramount to generating the most relevant results in the Bonito tool. Minor oversights or omissions of square brackets, quotation marks, or whitespaces can lead to an empty or unanticipated search result. To reduce the occurrence of such errors, a graphic editor is provided to generate more illuminating and error free formation of queries and can be launched through the menu: Query|Graphical Construction. However, more experienced users may find it more efficient to manually enter queries directly into the query box rather than using the graphic editor.
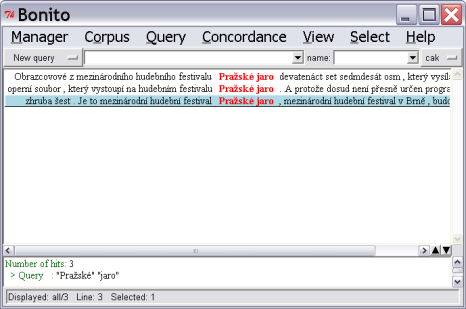
It is also possible to search for more words at the same time. To do this, simply enter each new query separated by gaps (see Figure 3.4). Be careful while searching for non-alphanumeric characters as they are significant for regular expressions with regards to the question mark and full stop. In order to search for these characters in a query expression they must be escaped with a slash “\” symbol such as \? to search for a question mark and similarly \. for a full stop. By putting down just a full stop, the result will search for all positions of the corpus with just one character (and full stops will be one of them).
If you double click on the concordance row, a broader context will be displayed in the lower window (see Figure 3.4). Here it is possible to enlarge or narrow the context by means of up or down arrows (first you should click the left mouse button into the space with broader context). It is possible to display in the main window not only concordances themselves but also attributes for individual words which are defined for the corpus (see Figure 3.3). The selection of attributes can be made via View|Attributes. Additionally, every row can be displayed with a name of the source document from which the concordance comes from (View|References).
Via View|Context you can change the size of the context, i.e. how many words, characters or sentences should be displayed. The item View|Range enables automatic selection of the number of rows. This is extremely useful for searches that have numerous results with many rows that would be difficult to inspect manually. The selection of a random sample of data is maybe used most frequently.
You can classify concordances according to the returned word form or even according to words found in both left and right context (Concordance|Simple Sort). Classifying can also be quite complex when done according to additional criteria (Concordance|Generic Sort). After selecting the mentioned functions, the appropriate parameters for classifying into the
emerged windows can then be entered.
The result of any modified, partially deleted, or classified query in the main window can be exported into the file (Concordance|Save to File) for further usage.
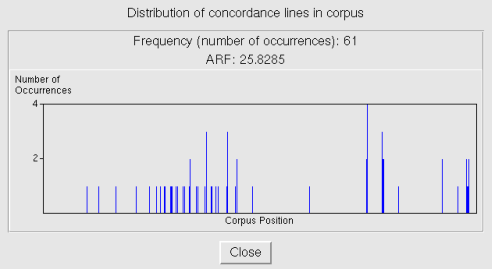
Finally, it is worth noting that there are many useful statistics functions that are accessible through the menu Concordance|Statistics. The item Distribution Overview will display a new window with a graph depicting the distribution of the searched concordances within the frame of the entire corpus (see Figure 3.5). It is immediately evident from the diagram if occurrences are distributed evenly or not. The window will also contain a numerical value expressing the average reduced frequency (Savický, Hlaváčová, 2002) which is a more objective expression of inequality of the distribution of occurrences.
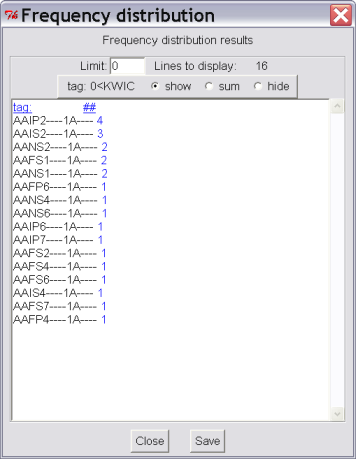
Selecting Concordance|Frequency Distribution will display chosen attributes of the found values together with their corresponding frequencies. Figure 3.6 demonstrates the frequency distribution of morphological tags from the previous example for lemma jaro.
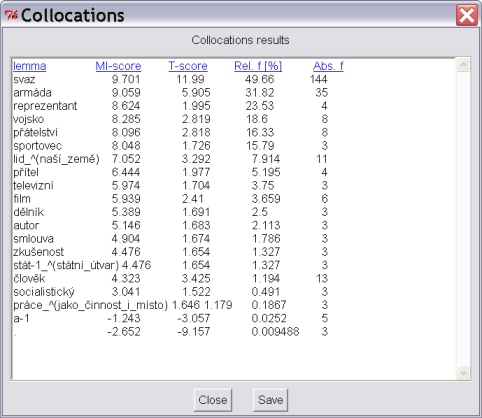
The last important statistical functions are collocations (Concordance|Collocations). Through this feature, it is possible to highlight words (or lemmas or tags) that occur in the assigned surroundings of the found occurrences (see Figure 3.8). The result is a chart that states for every word from the assigned surroundings along with its relative frequency within the frame of the found concordances by means of MI-score and T-score. The sequence of rows can be arranged according to category simply by clicking on the category heading on the chart. The most important collocations will always be located on top.
Figure 3.7 contains collocations to the lemma sovětský.
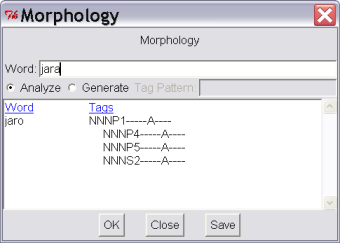
Bonito makes it possible to run the Czech morphological analyser directly through the menu
Manager|Morphology. The morphological analyser gives not only the analysis of a given word form (i.e. all possible
lemmas and morphological tags), but
the synthesis of a given lemma and tag (i.e. all possible word tokens) as well – see Figure 3.9.
Switching the language to English (Czech) is possible through the menu Manager – Change language (Manažer – Změna jazyka).
Lexical Annotation Workbench is an integrated environment for morphological annotation. It supports simple morphological annotation (assigning a lemma and tag to a word), integration and comparison of different annotations of the same text, searching for a particular word, tag etc. The workbench runs on all operating systems supporting Java, including Windows and Linux. It is an open system extensible via plugins – e.g., views, import/export filters, helps. The primary file format is the PDT 2.0 format (a PML instanciation [10]); it is possible to import and export data in the csts format [9] and the TNT format [23]. In the near future, the workbench will be extended with various statistical analysis functions and assistance from external tools like taggers and parsers.
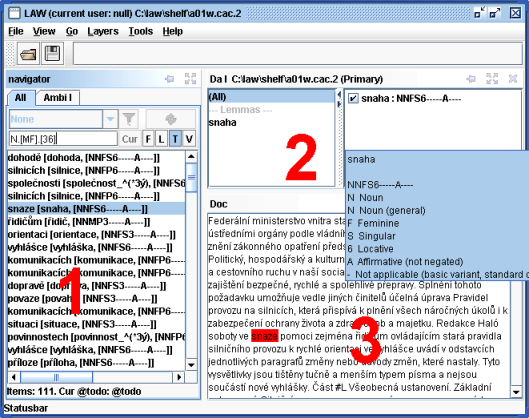
Navigator – for navigating through words of the document (browsing, filtering, searching, etc.)
Da Panels – for displaying and disambiguating morphological information (lemmas, tags) of a word. The panel consists of two windows – a grouping list and a list of items. The latter displays all the lemma-tag items associated with the current word (on the particular m-layer). The former makes it possible to restrict the items to a particular group, e.g., items with a particular lemma, detailed pos or gender. One of the panels is primary -- certain actions apply to that panel (e.g. Ctrl-T moves focus to the list of items in the primary panel).
Context Views – various contexts, e.g. plain text of the document, syntactic structures, etc.
Open a file with the m-layer you want to annotate
File | Open(Ctrl-O). The associated w-layer opens automatically.Switch to the ambi-list in Navigator displaying the ambiguous words of the layer you want to annotate and select the first word.
-
Press Enter. The cursor moves to the primary Da Panel. Select the correct lemma and tag and press Enter again. The cursor will move to the next ambiguous word.
If you made a mistake, switch to the all list, find the word where you made the mistake, select it, the associated annotation appears in the DaPanel. You can now select the correct item and then switch back to the ambi list.
Save the result of your work by
File | Save(Ctrl-S).
The data and applications for morphological analysis of the Czech texts were developed simultaneously. Two basic morphological applications for morphological analysis and tagging are also included in the CD.
Morphological analysis evaluates individual word forms and determines lemmas as well as possible morphological interpretations for the word form.
The application tagging (tagger) processes the morphological analysis results in regard to the sentence context. Regarding the character of the task, it is impossible to generate a method of tagging that would function with 100% accuracy. The tagger application is based on Hidden Markov Model (HMM) and implements the use of the averaged perceptron statistical method (Collins, 2002). Its entry is a text that contains the set of all possible morphological tags and lemmas for every word (output from the morphological analysis). In the output, the tagger defines this dataset with unambiguously determined tag and corresponding lemma. The tagger was trained on data in PDT 2.0 and its accuracy (percentage of correct tags) on CAC is 91,8 %. However, some errors are caused by differences between PDT and CAC. Therefore morphological analysis does not offer the correct tag for some words. This happens systematically
for numerals (in CAC represented by #) and unknown words (represented by ?). If we do not take these systematical differences into account, the final accuracy will be 93,1 %.
Tools are launched with the main script morph_chain which, according to switch, will elaborate the input file with a relevant tool. Usage of script is documented in the chart Table 3.6. Further details are provided in Chapter 5.
Table 3.6. Script morph_chain
| Option | Input file format | Output file format |
Description |
|---|---|---|---|
-A |
raw text, PML m-file | PML m-file | morphological analysis |
-T |
PML m-file | PML m-file | tagging (desambiguation) |
-AT |
raw text, PML m-file | PML m-file | tagging (morphological analysis precedes tagging) |
Tools are implemented in the programming languages C/C++ and Perl with the main script morph_chain in bash. Unfortunately, the C/C++ source code cannot be published due to copyright restrictions. The executable programs are compiled for the Linux operation system running on i386 architecture.
Example: Let´s have a look at the morphological analysis of Fantastickým finišem si však Neumannová doběhla pro vytoužené olympijské zlato [Neumannova powered down the final straight to win longed-for gold]. The results of the morphological analysis and tagging (concretely by executing morph_chain -AT) are collectively stated in Table 3.7. If additional possibilities of base word forms exist (e. g. the word form si is analyzed either as the verb být or as the reflexive particle se) the word form possibilities are separated with the pipe symbol "|". Incorrectly defined analyses are highlighted in bold for the reader to easily search for mistakes in tagging and the correct analysis is presented with regard to the context.
Table 3.7. Example of text treated with morphological analysis and tagging
| Text | Morphological analysis | Tagging |
|---|---|---|
Fantastickým |
fantastický AAFP3----1A---- AAIP3----1A---- AAIS6----1A---7 AAIS7----1A---- AAMP3----1A---- AAMS6----1A---7 AAMS7----1A---- AANP3----1A---- AANS6----1A---7 AANS7----1A---- |
fantastický AAIS7----1A---- |
finišem |
finiš NNIS7-----A---- |
finiš NNIS7-----A---- |
si |
být VB-S---2P-AA--7| se_^(zvr._zájmeno/částice) P7-X3---------- |
se_ ^(zvr._zájmeno/částice) P7-X3---------- |
však |
však J^------------- |
však J^------------- |
Neumannová |
Neumannová_;S NNFS1-----A---- NNFS5-----A---- |
Neumannová_;S NNFS1-----A---- |
doběhla |
doběhnout_:W VpQW---XR-AA--1 |
doběhnout_:W VpQW---XR-AA--1 |
pro |
pro-1 RR--4---------- |
pro-1 RR--4---------- |
vytoužené |
vytoužený_^(*3it) AAFP1----1A---- AAFP4----1A---- AAFP5----1A---- AAFS2----1A---- AAFS3----1A---- AAFS6----1A---- AAIP1----1A---- AAIP4----1A---- AAIP5----1A---- AAMP4----1A---- AANS1----1A---- AANS4----1A---- AANS5----1A---- |
vytoužený_^(*3it) AANS1----1A---- (AANS4----1A----) |
olympijské |
olympijský AAFP1----1A---- AAFP4----1A---- AAFP5----1A---- AAFS2----1A---- AAFS3----1A---- AAFS6----1A---- AAIP1----1A---- AAIP4----1A---- AAIP5----1A---- AAMP4----1A---- AANS1----1A---- AANS4----1A---- AANS5----1A---- |
olympijský AANS1----1A---- (AANS4----1A----) |
zlato |
zlato NNNS1-----A---- NNNS4-----A---- NNNS5-----A---- |
zlato NNNS1-----A---- (NNNS4-----A----) |
. |
. Z:------------- |
. Z:------------- |