


The Czech Academic Corpus version 1.0 is a corpus with a manual annotation of morphology of the Czech language consisting of approximately 600,000 words.
The process and length of the Czech Academic Corpus project conflicts with every embedded notion of a traditional project. The primary goal of this project was to create a corpus that would contain manual annotation of morphology and syntax of Czech. This manual annotation of morphology and syntax was initially developed more than twenty years ago (1971-1985) as a base for constructing a frequency dictionary of Czech at that time. Originally the corpus utilized the straightforward name: Corpus of the Pragmatic Style. Independent from the CAC, an annotation of the Prague Dependency Treebank (PDT) was launched in 1996. While working on the second version of PDT [11] [1] the idea of converting the internal format and annotation schemes CAC in a way that they would be compatible within PDT was proposed. This conversion would facilitate the possibility of integrating the annotations directly into PDT. The presented first version of CAC is a result of conversion of the internal format and morphological annotations.
CAC 1.0 offers:
- Data material for the linguist-theoretician that reflects real language usage
- Data of substantial size for computational linguists that should contribute to the amelioration of the applications of natural language that cannot exist without analysis of the texts on the morphological level
- Interesting teaching aid for teachers and students that can be used in Czech lessons for practice in Czech morphology
The CAC project continues with conversions of syntactic annotations into the chosen concept in PDT that should result into the edition of the second version. This second version will facilitate the direct integration of CAC into PDT. This added functionality will enrich the PDT both quantitatively and qualitatively from the view of the integration of the types of texts used, concrete texts of administrative style and spoken texts (transcripts of the spoken language).
Documents contained in CAC are mostly unabridged articles derived from a wide range of media. These articles include newspapers, magazines, and transcripts of the spoken language from radio and TV programs covering administration, journalism and scientific fields. Texts are taken from the 70s and 80s of the twentieth century and thus, the selection of texts is influenced by the climate of this time period. Symbolically the first journal article was taken from the daily newspaper Rudé Právo (equiv. of “Red Law”). The selection of the scientific texts was also influenced by the omnipresent regime. Noteworthy texts demonstrating this theme include Critique of the Bourgeois Theories of Society and Scientific Revolution and Socialism. Fortunately, some space was allocated to empirical works including How we understand chemical equations and Astronomical Almanac. The total enumeration of used sources can be found in Appendix A.
Before discussing the annotated corpus it is important to specify what was subject to annotation. From the linguistic theory viewpoint, one must first characterize the so-called layer of annotation. The original annotation of CAC covers two layers: a morphological layer and a syntactical layer. CAC 1.0 came to fruition as a result of converting the original internal format and the original morphological annotations and in this case we can only assess CAC as bearing only the morphological layer. For the sake of completeness, we have to add that CAC 1.0 is also operating with one more layer – the word layer (see Chapter 3, Section 3.2.1). In fact, the word layer is not a layer for annotation as it is consisting of the original text divided into word tokens. However, we will refer to the word layer as an annotation layer. Every word token is provided with a unique identifier. Thus far, the term “sentence” has been intentionally omitted since the word layer does not arrange segmentation of texts into sentences. Instead, this process takes place in the morphological layer. These layers are referred to as the w-layer for the word layer and the m-layer for the morphological layer.
A morphological layer of annotation indicates that word tokens are provided along with data (annotation), which characterize their morphological properties (as apparent in the word lemma which is the canonical form of a lexeme), part of speech, and morphological categories (case, number, tense, person...). Formally, part of speech classes combine together with morphological categories to represent morphological tags. In CAC 1.0, tags are designated in PDT as strings of definite length (15 positions) where each position corresponds to a single category. Included in the guide is a definitive list containing the detailed descriptions of these morphological positional tags.
Example: The word form Prahu is analyzed as affirmative (11th position) noun (1st and 2nd position) feminine (3rd position), singular (4th position) in accusative (5th position). All the other positions are correctly defined with a symbol '-' that represents irrelevance of the morphological category towards the part of speech. For example, one does not determine person with nouns (8th position).
Table 2.1. Examples of lemmas and tags of certain word units
| word token | lemma | tag | description |
|---|---|---|---|
| Prahu | Praha | NNFS4-----A---- |
noun, feminine, singular, accusative, affirmative |
| 123 | 123 | C=------------- |
digit tokens |
| ) | ) | Z:------------- |
punctuation mark (right bracket) |
The conception of the internal format of CAC 1.0 treats annotation layers separately where each layer of annotation in the document corresponds to one file. This relationship in CAC 1.0 means that there are two groups for every document, one for the w-layer and one for the m-layer. However, the distinction between layers does not restrict interconnection between groups for particular layers of annotation. In fact, the opposite is true as demonstrated later in this section.
As was implied above, segmentation of texts into sentences is a part of an m-layer. This means that unlike the w-layer, the m-layer contains sentence-final punctuation. Additionally, the number of word tokens in both layers may differ, implying a concatenation of the wrongly split word into one word, or reversely, indicating a division of wrongly connected words into more units. The correctly written text should be contained in the m-layer.
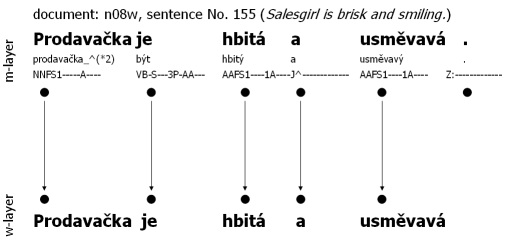
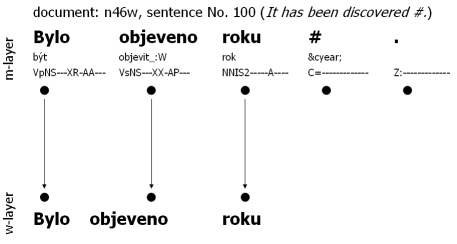
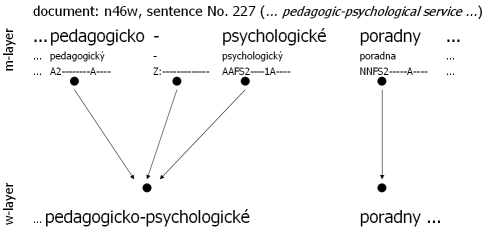
Example: The following diagrams illustrate the interconnection of layers, and therefore groups, in the sense of word tokens. Interconnection is shown with arrows. All three examples were chosen from CAC 1.0 deliberately in order for the user to directly view the groups (name of the document and number of the sentence is provided for every sentence). Figure 2.1, Technical Interconnection of w-layer and m-layer: No Changes serves to illustrate the 1:1 ratio of the layers. Notice that with the exception of the final-sentence punctuation, the layers do not differ. Figure 2.2, Technical Interconnection of w-layer and m-layer: Insertion of Word Token exemplifies the situation where a word token is inserted into the text but the year information is clearly missing in the text. Since it is almost impossible for the corrector to add the missing year, the symbol '#' is used. However, this symbol does not have a counterpart on the w-layer. By contrast, Figure 2.3, Technical Interconnection of w-layer and m-layer: Division of the Word Token manifests a situation were multiple nodes on the m-layer correspond to a common node at the w-layer. This occurs because the word token pedagogicko-psychologické is segmented into three distinct tokens on the m-layer.
The idea of the Czech Academic Corpus came to life between 1971 and 1985 thanks to the Mathematic Linguistics Department within the Institute of the Czech Language under guidance of Marie Těšitelová. The idea to collect new textual material that would not be classified manually but rather methodically emerged in her work on the extensive volume Frequency of Words, Word Classes and Forms in the Czech language (Jelínek, Bečka, Těšitelová, 1961). Těšitelová´s proposal was to join this method of classification with computer technology which at that time was in the form of punch card controlled mainframes including the IBM 370 and the Tesla 200. The discussion on the concept of academic grammar of Czech finally led to the traditional, systematic, and well elaborated concept of morphology and dependency syntax (Šmilauer, 1972).
Handwritten sources of texts remained for some time in the archive but owing to decreased interest they were finally destroyed, which later was discovered to be extremely unfortunate. Fortunately the electronic version of CAC was successful in keeping up with the fast technical progress, changes of format, and data carriers. That is why CAC could be used in 1994 for the first experiments of morphological tagging of Czech texts while using the annotated corpus (Hladká, 1994). Experiments were conducted at the Institute of Formal and Applied Linguistics, Faculty of Mathematics and Physics, Charles University (http://ufal.mff.cuni.cz/). These experiments proved to be decisive for the next evolution of the Czech computational linguistics.
The summary (Hladká, Králík, 2006) is dedicated to the overview of years when CAC could not process texts having more than 2,000 words or was annotated in blue and in red on the paper or when it was being migrated from punch cards to audio magnetic tape.
The continuation of the Czech Academic Corpus was largely influenced by the Prague Dependency Treebank whose annotations cover three layers: morphological, syntactic-analytical, and tectogrammatical (layer of meaning). The complexity of annotating is reflected in the volume of data annotated at these layers. The largest volume of data, 2 million words, is annotated only morphologically; 1,5 million words have also a syntactic annotation and from them 800,000 words is provided with tectogrammatical annotation. The experience acquired from annotating such a huge volume of data is so exceptional and illuminating that it gave its way to become one of the main motivations for further work within CAC.
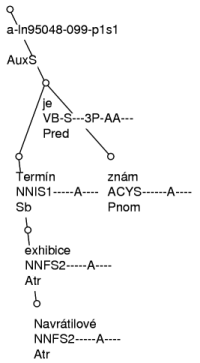
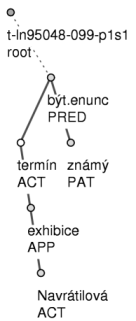
Example: The sentence Termín exhibice Navrátilové je znám [The date of Navratilova exhibition match is known.] from PDT 2.0 can be used to demonstrate key principles of morphological, syntactic, and tectogrammatical annotation. Figure 2.4 and Figure 2.5 illustrate the annotation of this sentence at all three layers. Figure 2.5 is a syntactic annotation (tree structure and analytical functions correspond to parsing) together with a morphological annotation. Figure 2.5 visualizes the tectogrammatical structure by means of a tree structure together with functors. For addition information on these trees it is recommended to also inspect the directives which were used to implement the annotation of PDT 2.0 (Hana, Zeman, 2005, Hajič et al., 1999, Mikulová et al., 2006).
The continuation of CAC was outlined and divided into three phases lasting five years. Due to our aforementioned experience in such projects, a detailed plan was developed including an assessment of the time requirements and machining capacity for each of the steps. At the time of publishing the CD-ROM CAC 1.0, converting of the internal format and the morphological annotations is complete. These first two goals were reached after starting just two years ago. The following list enumerates the particular steps and summarizes the respective details. A more complete description of the details can be found in Hladká, Králík, 2006.
Conversion of the internal format: Conversion of the originally simple textual CSV format (comma-separated values) into the format csts [9] based on the world standard SGML [16].
Automatic conversion of morphological annotations: Conversion of the original morphological annotation scheme into positional morphological tags. The mapping of the tags and all the subsequent checks and evaluation of the results were executed in compliance with the morphological annotation of PDT (Hana, Zeman, 2005).
Manual addition of the missing annotations: If the morphological analysis was incapable of analyzing a certain word token, annotations were added manually to that word token.
-
Correction of the texts: Digit tokens and punctuation were omitted from CAC since the beginning of the annotation. These omissions included words that are read differently than their written form (25 vs. twenty-five) or units that are not pronounced at all such as punctuation. It was quite necessary to solve this problem as it is considered a fundamental deficiency from the viewpoint of the applications of the natural language. The solution seemed to be unattainable as the handwritten sources of texts were not available as mentioned above. The only alternative was to read all documents of CAC and highlight where, according to the corrector, digit tokens or a punctuation character should be. It was desirable to make a distinction between the different representations of the numbers, i.e. whether they related to an amount, a year, a date, or an enumeration. If none of the possibilities corresponded in the context, the corrector had a choice to decide into which category the number was ultimately assigned. If more than one category appeared to fit the number, the corrector chose all relevant options. At the same time the corrector was marking out parts of sentences that, for whatever reason, seemed obscure in nature such as an atypical word order in a sentence or a missing word.
In addition to manually removing certain tokens of text, the correctors also added elements to the texts when necessary. The various formats of added elements are outlined below.
Added digit tokens:
word=#,lemma=&camount;(amount),lemma=&clabel;(label),lemma=&cyear;(year),lemma=&cdate;(date),lemma=&cother;(other),tag=C=-------------Obscure situations:
word=?,lemma=?,tag=Xx-------------
Manual revision of correction: Elaboration of contrarieties among correctors.
Conversion of the internal format: Conversion of the internal format csts into the XML-based format PML[10].
The final revision of morphological annotations: Inevitably, mistakes in data may exist despite the aspiration and tremendous efforts to write conversions from the original data format and from the original annotation scheme by the manual annotators and correctors. To help reveal these human errors, automatic validation scripts were used. The tool Netgraph [20] and TrEd/btred/ntred [22] helped search for places in texts where a violation of annotation or grammar rules may have occurred. The conspicuous places were then checked manually and corrected automatically according to the nature of the error. Concrete potential mistakes were derived from similar checks conducted in PDT 2.0 and from work conducted on data in CAC 1.0.
Despite multiple checks of annotations, mistakes can still be found. Unfortunately, it is impossible to predict the number of errors due to the level of checks conducted on the data. Automatic detection of these errors will be the next step once the conversion of syntactic annotations and validation of the annotations on both layers is complete.
Example: If parsing of a sentence is available, it is possible to check agreement between the subject and predicate. Words annotated as subject and predicate must have identical morphological values on the position of gender and number in order to be valid.
Table 2.2 and Table 2.3 include recapitulative characteristics of CAC 1.0. More detailed information can be seen in Table 3.5.
Table 2.2. Quantitative characteristics of CAC 1.0
| style | form | number of documents | number of sentences | number of word tokens |
|---|---|---|---|---|
| journalism | written | 52 | 10 234 | 189 435 |
| journalism | transcription | 8 | 1 433 | 28 737 |
| scientific | written | 68 | 11 113 | 245 175 |
| scientific | transcription | 32 | 4 576 | 115 853 |
| administrative | written | 16 | 3 362 | 58 697 |
| administrative | transcription | 4 | 989 | 14 235 |
| total | written | 136 | 24 709 | 493 307 |
| total | transcription | 44 | 6 998 | 158 825 |
| total | written and transcription | 180 | 31 707 | 652 132 |
Table 2.3. Quantitative characteristics of CAC 1.0 – inserted symbols
| style | form | number of '#' tokens (number of sentences) | number of '?' tokens (number of sentences) | number of '#' or '?' (number of sentences) | number of sentences w/o '#' or '?' tokens |
|---|---|---|---|---|---|
| journalism | written | 1 769 (1 187) | 925 (680) | 2 694 (1 563) | 8 671 |
| journalism | spoken | 5 (5) | 25 (25) | 30 (30) | 1 403 |
| scientific | written | 2 149 (1 222) | 2 230 (1 418) | 4 379 (2 030) | 9 083 |
| scientific | spoken | 9 (9) | 131 (108) | 140 (113) | 4 463 |
| administrative | written | 901 (611) | 635 (476) | 1 536 (915) | 2 447 |
| administrative | spoken | 0 (0) | 16 (15) | 16 (15) | 974 |
[1] We cite not only the bibliography but the internet sources as well – number in square brackets refers to a list of url links listed in Appendix B.