Institute of Formal and Applied Linguistics
Charles University, Czech Republic
Faculty of Mathematics and Physics
Parsito
1. Introduction
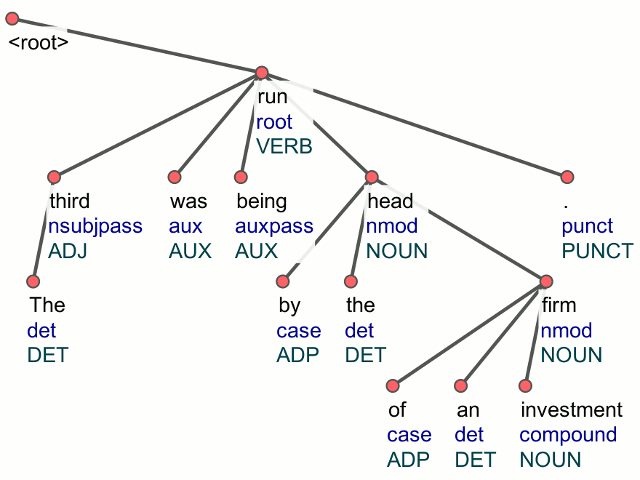
Parsito is a fast open-source dependency parser written in C++. Parsito is based on greedy transition-based parsing, it has very high accuracy and achieves a throughput of 30K words per second. Parsito can be trained on any input data without feature engineering, because it utilizes artificial neural network classifier. Trained models for all treebanks from Universal Dependencies project are available (37 treebanks as of Dec 2015).
Parsito is a free software under Mozilla Public License 2.0 and the linguistic models are free for non-commercial use and distributed under CC BY-NC-SA license, although for some models the original data used to create the model may impose additional licensing conditions. Parsito is versioned using Semantic Versioning.
Copyright 2015 by Institute of Formal and Applied Linguistics, Faculty of Mathematics and Physics, Charles University in Prague, Czech Republic.
2. Release
2.1. Download
Parsito releases are available on GitHub, both as source code and as a pre-compiled binary package. The binary package contains Linux, Windows and OS X binaries, Java bindings binary, C# bindings binary, and source code of Parsito and all language bindings). While the binary packages do not contain compiled Python or Perl bindings, packages for those languages are available in standard package repositories, i.e. on PyPI and CPAN.
2.1.1. Language Models
To use Parsito, a language model is needed. The language models are available from LINDAT/CLARIN infrastructure and described further in the Parsito User's Manual. Currently the following language models are available:
- Universal Dependencies 1.2 Models: parsito-ud1.2-151120 (documentation)
2.2. License
Parsito is an open-source project and is freely available for non-commercial purposes. The library is distributed under Mozilla Public License 2.0 and the associated models and data under CC BY-NC-SA, although for some models the original data used to create the model may impose additional licensing conditions.
If you use this tool for scientific work, please give credit to us by referencing Straka et al. 2015 and Parsito website.
3. Parsito Installation
Parsito Installation on separate page.
4. Parsito User's Manual
Parsito User's Manual on separate page.
5. Parsito API Reference
Parsito API Reference on separate page.
6. Contact
Authors:
7. Acknowledgements
This work has been using language resources developed and/or stored and/or distributed by the LINDAT/CLARIN project of the Ministry of Education of the Czech Republic (project LM2010013).
Acknowledgements for individual language models are listed in Parsito User's Manual page.
7.1. Publications
- (Straka et al. 2015) Straka Milan, Hajič Jan, Straková Jana and Hajič Jan jr. Parsing Universal Dependency Treebanks using Neural Networks and Search-Based Oracle. In Proceedings of the Fourteenth International Workshop on Treebanks and Linguistic Theories ({TLT\,14}), December 2015.
7.2. Bibtex for Referencing
@InProceedings{udparsing:2015,
author = {Straka, Milan and Haji\v{c}, Jan and Strakov\'{a}, Jana and Haji\v{c} jr., Jan},
title = {Parsing Universal Dependency Treebanks using Neural Networks and Search-Based Oracle},
booktitle = {Proceedings of Fourteenth International Workshop on Treebanks and Linguistic Theories ({TLT\,14})},
month = {December},
year = {2015},
}
7.3. Persistent Identifier
If you prefer to reference Parsito by a persistent identifier (PID),
you can use http://hdl.handle.net/11234/1-1584.