Visualization of the Week
2018-03-26 (Sixth)
Pavel Straňák/Amir Kamran: Big Brother is Keeping Tabs
Very interactive: https://lindat.mff.cuni.cz/en/statistics
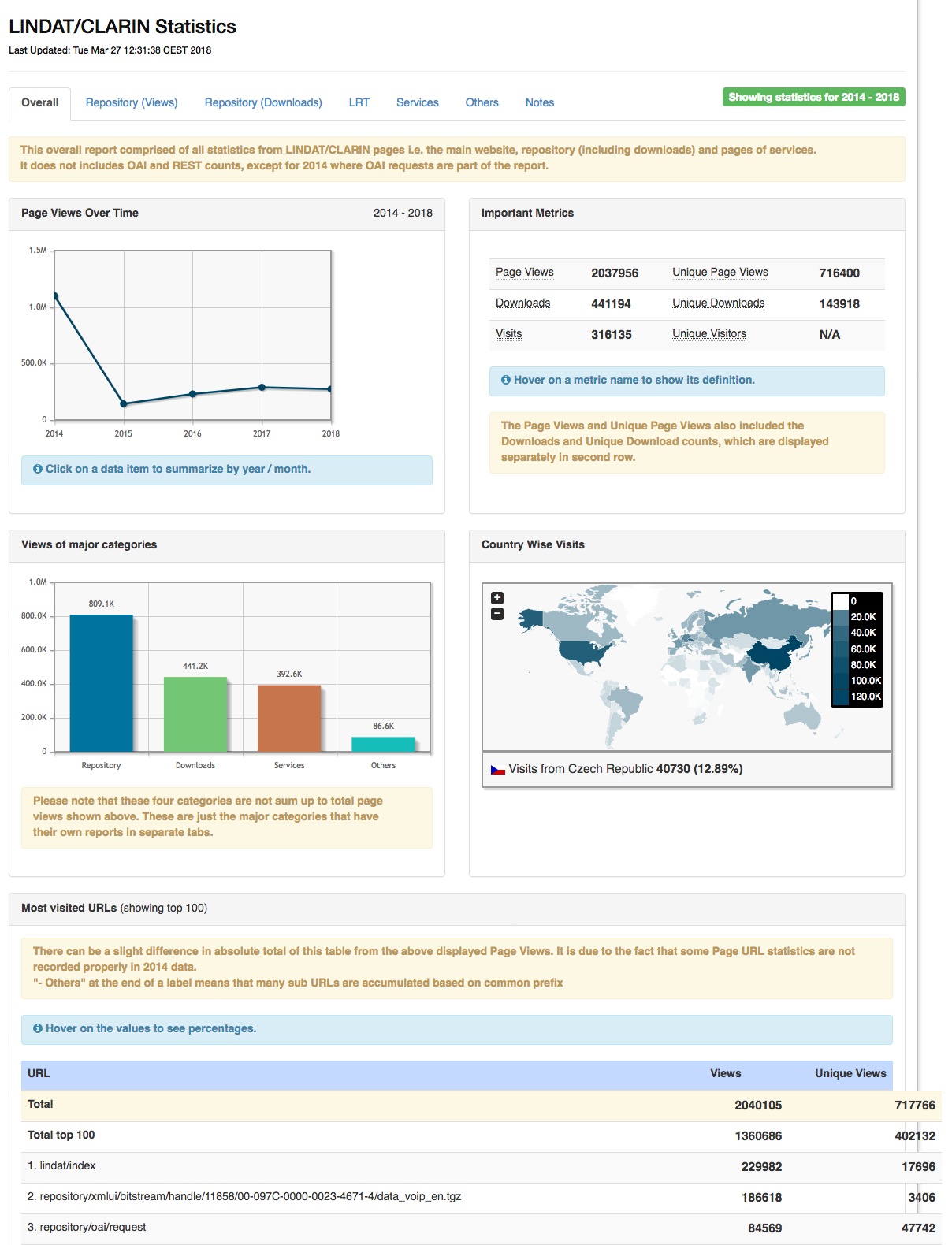
This is how the LINDAT technical team keeps track of LINDAT usage. These stats are important for management decisions, such as not killing off Treex::Web.
2018-03-19 (Fifth)
Milan Straka: Fake a Snake
The first interactive visualization! http://ufallab.ms.mff.cuni.cz/~straka/relu_approximation/relu_approximation.html
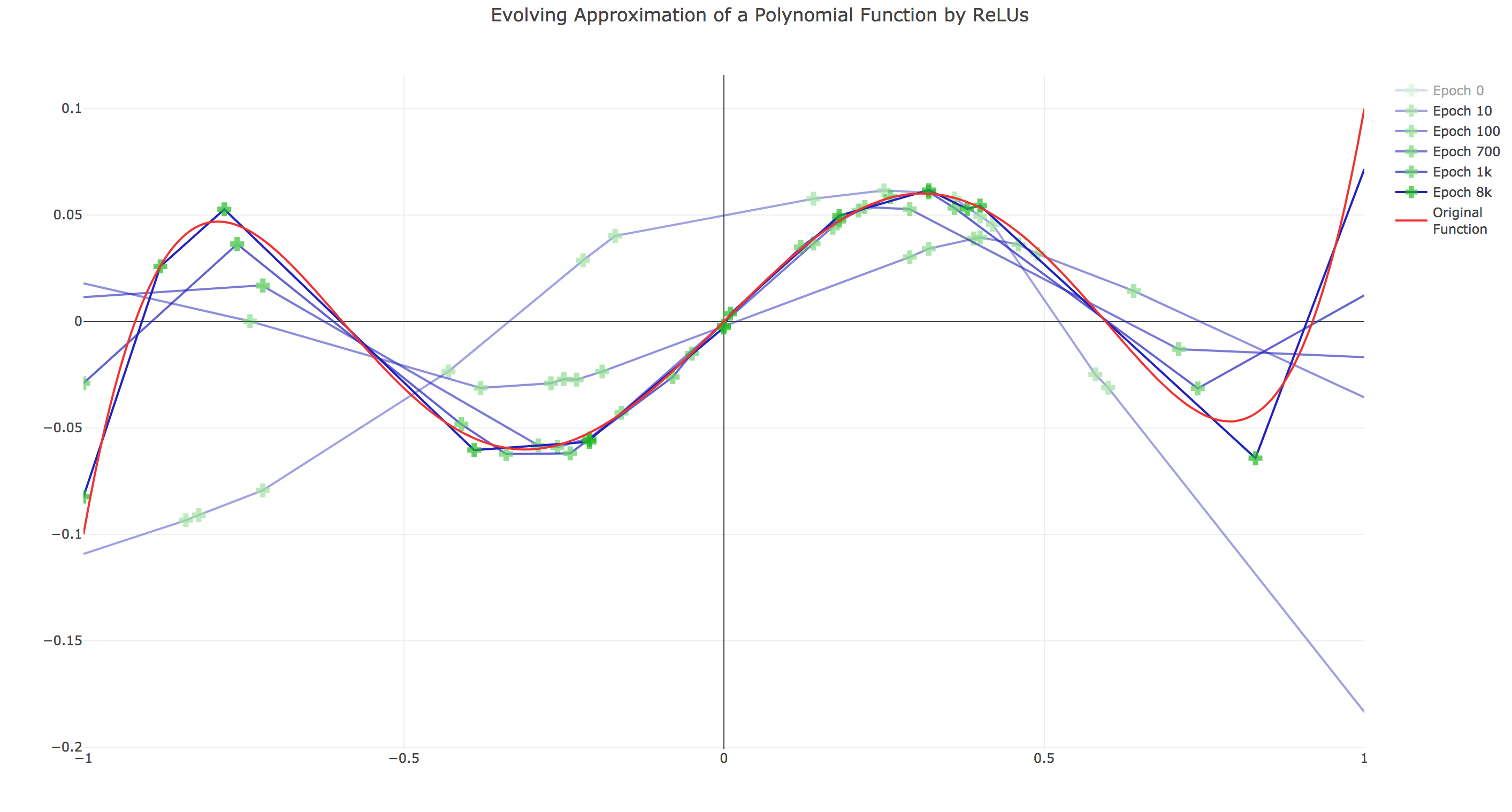
A neural network with one hidden layer and a nonlinearity can approximate any function, given that the hidden layer is sufficiently large (however, what is sufficient is hard to guess for complicated functions). Here is how a polynomial is gradually approximated with a 20-unit hidden layer using ReLU nonlinearities.
2018-03-12 (Fourth)
Ondřej Cífka: Through a Hydra's Eyes
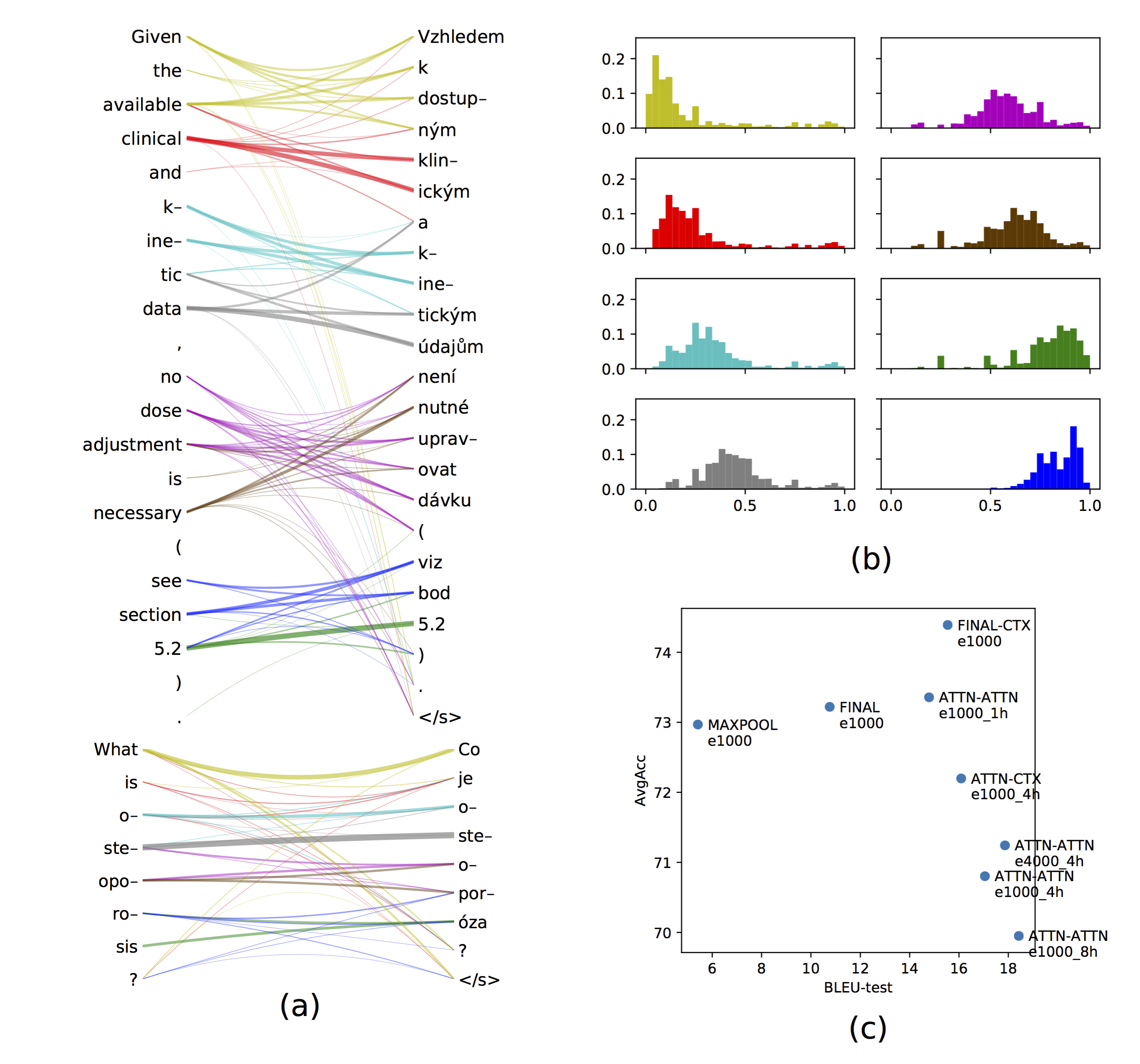
The action of multi-head attention when using it as a sentence representation in an encoder-decoder architecture. Eight attention heads (each color-coded). Take-home message was: the heads just cover the source sentence left to right, they are not necessarily looking for semantically interpretable things. This is maybe because the decoder combines them into a context vector, with no way of distinguishing which head is which.
2018-03-05 (Third)
Silvie Cinková: A Cloud of Teachers
Courses:

Teachers:

The visualization tries to make sense of the world of Digital Humanities (DH) in the Czech Republic. Instead of relying too much on self-categorization, which can be inconsistent across various universities, faculties and departments that provide Digital Humanities education, this visualization takes the raw text of course syllabi and uses Latent Semantic Analysis to discover how the field is structured. The top 10 terms for each LSA cluster (direction in the latent space) are shown, scaled by their corresponding weight.
Apparently, there is some balance between teaching DH as an "add-on" to humanities (and social sciences), and teaching the methodologies of DH.
2018-02-26 (Second)
Tom Kocmi: The End of Journalism

Summarization of titles from abstracts (first paragraphs) is decent, but summarization from texts to abstracts is somewhat... misleading.
2018-02-19 (First!)
Martin Popel: Meteor BLEU Swarm
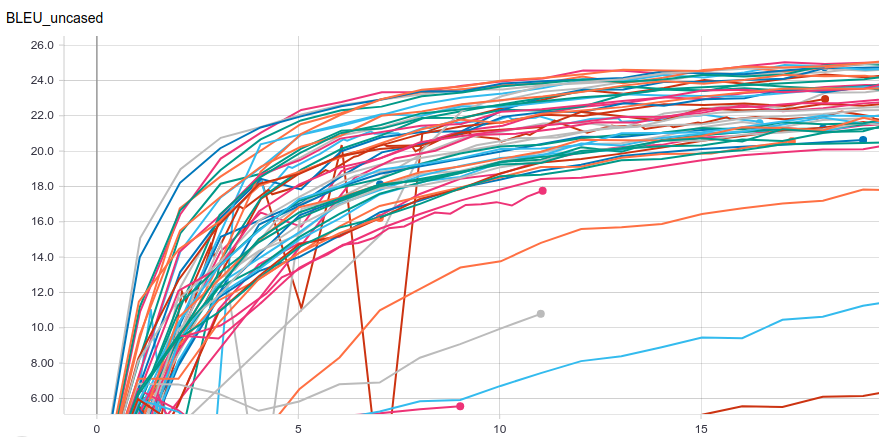
Discussion on learning rates and batch sizes in machine translation with the Transformer model. One interesting take-away: it's apparently faster to train 8 Transformers on 8 GPUs consecutively than to allocate 1 GPU to each & run them in parallel.