


V této části uvádíme popis adresářové struktury CD-ROM, a to až do druhé, příp. třetí úrovně zanoření, viz tabulka 3.1. Pokud v textu odkazujeme na obsah CD-ROM, který je zanořen hlouběji, explicitně na to upozorňujeme uvedením úplné cesty.
Tabulka 3.1. Adresářová struktura CD-ROM ČAK 2.0
index.html |
# průvodce ČAK 2.0 česky (formát html) | |||
index-en.html |
# průvodce ČAK 2.0 anglicky (formát html) | |||
Install-on-Linux.pl |
# instalační skript pro Linux (anglicky) | |||
Install-on-Windows.exe |
# instalační program pro MS Windows (anglicky) | |||
Instaluj-na-Linuxu.pl |
# instalační skript pro Linux (česky) | |||
Instaluj-na-Windows.exe |
# instalační program pro MS Windows (česky) | |||
bonus-tracks/ |
# bonusový materiál | |||
|
# elektronická cvičebnice češtiny | |||
data/ |
# datová komponenta | |||
|
# ČAK 2.0 ve formátu CSTS (soubory [ans][0-9][0-9][sw].csts) |
|||
|
# ČAK 2.0 ve formátu PML (soubory [ans][0-9][0-9][sw].[amw]) |
|||
|
# PML schémata a dtd pro CSTS | |||
doc |
# dokumentace | |||
|
# průvodce ČAK 2.0 česky a anglicky (formát pdf) | |||
tools/ |
# nástroje | |||
|
# korpusový manažer | |||
|
# Java Runtime Environment 6 Update 3 pro Linux a MS Windows | |||
|
# anotační morfologický editor | |||
|
# anotační syntaktický editor včetně modulu TrEdVoice pro hlasové ovládání | |||
|
# korpusový prohlížeč a vyhledávač | |||
|
# nástroje pro automatické zpracování českých textů | |||
|
# skript pro spouštění tokenizace a/nebo morfologické analýzy a/nebo tagování a/nebo parsování | |||
|
||||
tutorials/ |
# tutoriály k nástrojům |
Předmětem této části je organizace ČAK 2.0 do souborů, jejichž jména podléhají jisté konvenci, a samotná vnitřní reprezentace souborů.
Hlavním datovým formátem ČAK 2.0 je formát nazvaný Prague Markup Language (PML), založený na XML [31] a navržený pro bohatou reprezentaci lingvistické anotace textů. Každé zvolené rovině anotace odpovídá jeden samostatný soubor. Návrh PML probíhal souběžně s tektogramatickou anotací PZK 2.0.
Vedlejším datovým formátem ČAK 2.0 je formát CSTS. Jde o formát SGML [19] používaný v PZK 1.0 a rovněž v Českém národním korpusu [13]. Důvodem pro jeho použití v ČAK 2.0 je větší čitelnost tohoto formátu pro člověka, jeho snadné zpracování jednoduchými nástroji a rovněž to, že některé z nástrojů ČAK 2.0 pracují výhradně s CSTS. K dispozici je též nástroj pro převod mezi těmito dvěma formáty.
Následující oddíl obsahuje stručný přehled hlavních vlastností formátu PML; podrobné informace jsou publikovány v technické zprávě (Pajas, Štěpánek, 2005). V další části uvádíme stručný přehled hlavních vlastností formátu CSTS. Podrobnější informace je možno nalézt v dokumentaci PZK 2.0 [12].
V PML se mohou jednotlivé oddělené roviny anotace překrývat a mohou být konzistentně propojeny
jak mezi sebou, tak i s dalšími zdroji dat.
Každá rovina anotace je popsána v souboru
PML schéma, který je jakousi formalizací abstraktního
anotačního schématu pro tu kterou rovinu anotace.
PML schéma popisuje, které elementy se na dané rovině vyskytují,
jak jsou spojovány, vnořovány a strukturovány, hodnoty jakého typu se v nich
mohou vyskytovat a jakou roli hrají v anotačním schématu
(tato informace o tzv. PML roli
může být využívána i aplikacemi ke správnému určení způsobu zobrazení PML dat uživateli).
Z PML schématu mohou být automaticky generována další schémata, jako je
Relax NG [18], díky čemuž může být konzistence dat ověřena pomocí běžných nástrojů pro XML.
Obě verze schémat jsou k dispozici v adresáři data/schemas/.
Pro ilustraci uvádíme v tabulce 3.2 část PML schématu w-roviny dat
ČAK (data/schemas/wdata_schema.xml), která specifikuje, že
odstavec (typ para,
v případě ČAK 2.0 vždy celý dokument) sestává z posloupnosti elementů typu w-node.type;
tento typ je níže definován jako struktura obsahující mimo jiné dva povinné elementy: id (jednoznačný identifikátor
s rolí #ID) a token (slovní jednotku).
Tabulka 3.2. PML schéma w-roviny ČAK 2.0
|
<type name="w-para.type"> <sequence> <... <element name="w" type="w-node.type"/> </sequence> </type> <type name="w-node.type"> <structure name="w-node"> <member as_attribute="1" name="id" role="#ID" required="1"> cdata format="ID"/></member> <member name="token" required="1"><cdata format="any"/> </member> <member name="no_space_after" type="bool.type"/> </structure> </type> ... |
Každý PML soubor začíná hlavičkou odkazující na PML schéma souboru.
V hlavičce jsou uvedeny všechny externí zdroje, na které je z tohoto souboru odkazováno,
spolu s několika dalšími informacemi potřebnými pro správné vyhodnocení odkazů.
Zbytek souboru obsahuje vlastní anotaci. Část hlavičky souboru m-roviny (n01w.m), kde se odkazuje
na PML schéma tohoto souboru (mdata_schema.xml) a na příslušný soubor
w-roviny (n01w.w), uvádíme jako příklad v tabulce 3.3.
Tabulka 3.3. Část hlavičky souboru n01w.m
|
<head> <schema href="mdata_schema.xml" /> <references> <reffile id="w" href="n01w.w" name="wdata" /> </references> </head> ... |
Obdobně tabulka 3.4 ukazuje referenční část hlavičky souboru a-roviny (n01w.a), kde se odkazuje na PML-schéma tohoto souboru (adata_schema.xml) a na příslušný soubor
m-roviny (n01w.m) a w-roviny (n01w.w).
Tabulka 3.4. Část hlavičky souboru n01w.a
|
<head> <schema href="adata_schema.xml" /> <references> <reffile id="m" href="n01w.m" name="mdata" /> <reffile id="w" href="n01w.w" name="wdata" /> </references> </head> ... |
Anotace je vyjádřena pomocí XML elementů a atributů pojmenovaných
a použitých v souladu s příslušným PML schématem. Pro ilustraci uvádíme v tabulce 3.5 příklad morfologické anotace části věty
Váš boj je i naším bojem.
Otvírací značka elementu
s obsahuje
identifikátor celé věty, stejně tak otvírací značky elementu m
obsahují identifikátory dané anotace odpovídajících slovních jednotek w-roviny, na které se odkazuje z elementu
w.rf.
Další elementy obsahují formu (form), morfologickou značku (tag)
a lemma (lemma) a element src.rf udává
zdroj anotace, v tomto případě ruční.
Tabulka 3.5. Ukázka anotace věty na m-rovině ve formátu PML
|
<s id="m-n01w-s14"> <m id="m-n01w-s14W1"> <src.rf>manual</src.rf> <w.rf>w#w-n01w-s14W1</w.rf> <form>Váš</form> <lemma>tvůj_^(přivlast.)</lemma> <tag>PSYS1-P2-------</tag> </m> <m id="m-n01w-s14W2"> <src.rf>manual</src.rf> <w.rf>w#w-n01w-s14W2</w.rf> <form>boj</form> <lemma>boj</lemma> <tag>NNIS1-----A----</tag> </m> <m id="m-n01w-s14W3"> <src.rf>manual</src.rf> <w.rf>w#w-n01w-s14W3</w.rf> <form>je</form> <lemma>být</lemma> <tag>VB-S---3P-AA---</tag> </m> ... <m id="m-n01w-s14W7"> <src.rf>manual</src.rf> <form_change>insert</form_change> <form>.</form> <lemma>.</lemma> <tag>Z:-------------</tag> </m> </s> |
Tabulka 3.6 ukazuje příklad analytické anotace věty Váš boj je i naším bojem. Pro přehlednost jsou vynechány méně důležité elementy.
Závislostní struktura věty je zachycena strukturou vnořovaných elementů. Synovské uzly jsou obaleny
elementem children. Každý uzel je dále obalen elementem LM, jehož atributem je identifikátor tohoto uzlu; výjimkou jsou jednoprvkové seznamy uzlů, kde tento
element může být vynechán, identifikátor uzlu je pak atributem elementu children. Element
m.rf odkazuje na příslušný prvek nižší roviny, který obsahuje konkrétní slovní formu, element
afun obsahuje analytickou funkci uzlu. Element ord
obsahuje pořadí uzlu ve stromu zleva doprava, které je shodné s pořadím slova ve větě.
Tabulka 3.6. Ukázka anotace věty na a-rovině ve formátu PML
|
<LM id="a-n01w-s14"> <s.rf>m#m-n01w-s14</s.rf> <afun>AuxS</afun> <ord>0</ord> <children> <LM id="a-n01w-s14W3"> <afun>Pred</afun> <m.rf>m#m-n01w-s14W3</m.rf> <ord>3</ord> <children> <LM id="a-n01w-s14W2"> <afun>Sb</afun> <m.rf>m#m-n01w-s14W2</m.rf> <ord>2</ord> <children id="a-n01w-s14W1"> <afun>Atr</afun> <m.rf>m#m-n01w-s14W1</m.rf> <ord>1</ord> </children> </LM> <LM id="a-n01w-s14W6"> <afun>Pnom</afun> <m.rf>m#m-n01w-s14W6</m.rf> <ord>6</ord> <children id="a-n01w-s14W5"> <afun>Atr</afun> <m.rf>m#m-n01w-s14W5</m.rf> <ord>5</ord> <children id="a-n01w-s14W4"> <afun>AuxZ</afun> <m.rf>m#m-n01w-s14W4</m.rf> <ord>4</ord> </children> </children> </LM> </children> </LM> <LM id="a-n01w-s14W7"> <afun>AuxK</afun> <m.rf>m#m-n01w-s14W7</m.rf> <ord>7</ord> </LM> </children> </LM> |
XML elementy všech souborů patří do vyhrazeného jmenného prostoru
http://ufal.mff.cuni.cz/pdt/pml/ (pouze název jmenného prostoru, nejedná se o smysluplný odkaz).
Formát PML poskytuje jednotnou reprezentaci většiny běžných anotačních konstrukcí,
jako jsou struktury atribut-hodnota, seznam alternativních hodnot určitého typu
(atomického nebo dále strukturovaného), odkazy v rámci PML souboru, odkazy mezi různými PML soubory
(v ČAK 2.0 použité k odkazům mezi rovinami) nebo do dalších externích zdrojů typu XML.
Ve formátu CSTS jsou všechny roviny anotace uchovány v jednom souboru.
Soubor CSTS začíná (nepovinnou) hlavičkou
(element h) a dále obsahuje alespoň jeden element doc. Element doc sestává z hlavičky
(element a) a obsahu (element c). Element c pak sestává z posloupnosti odstavců (element p) a vět v těchto odstavcích (element s).
Každá slovní jednotka věty je na samostatném řádku souboru (element f, resp. d pro interpunkci), dále na tomto
řádku následuje anotace této slovní jednotky na všech rovinách. Element l obsahuje
lemma slovní jednotky, element t obsahuje její morfologickou značku.
Element A obsahuje analytickou funkci slovní jednotky. Jednoznačný identifikátor
slovní jednotky v rámci věty je uložen v elementu r. Element g
obsahuje odkaz na řídící uzel příslušného slova; v tomto elementu je uveden identifikátor příslušného
řídícího uzlu.
Tabulka 3.7 ukazuje, jak ve formátu CSTS vypadá kompletní anotace věty Váš boj je i naším bojem.
Tabulka 3.7. Ukázka anotace věty ve formátu CSTS
|
<s id=n01w-s14> <f id=n01w-s14W1>Váš<l>tvůj_^(přivlast.)<t>PSYS1-P2------- <r>1<g>2<A>Atr <f id=n01w-s14W2>boj<l>boj<t>NNIS1-----A----<r>2<g>3<A>Sb <f id=n01w-s14W3>je<l>být<t>VB-S---3P-AA---<r>3<g>0<A>Pred <f id=n01w-s14W4>i<l>i<t>J^-------------<r>4<g>5<A>AuxZ <f id=n01w-s14W5>naším<l>můj_^(přivlast.)<t>PSZS7-P1------- <r>5<g>6<A>Atr <f id=n01w-s14W6>bojem<l>boj<t>NNIS7-----A----<r>6<g>3<A>Pnom <D> <d id=n01w-s14W7>.<l>.<t>Z:-------------<r>7<g>0<A>AuxK |
DTD soubor pro formát CSTS se nachází v adresáři data/schemas/. Podrobný popis tohoto formátu je
možno nalézt v dokumentaci PZK 2.0 [12].
V adresářích tools/tool_chain/csts2pml/ a tools/tool_chain/pml2csts/
jsou k dispozici převodní skripty mezi oběma formáty.
Každý datový soubor ČAK 2.0 odpovídá jednomu anotovanému dokumentu. První znak jména souboru indikuje
styl textu: n označuje novinové články (publicistiku),
s označuje vědecké texty (odborný styl), a označuje texty administrativní. Následuje
dvoumístné pořadové číslo dokumentu v rámci skupiny dokumentů jednoho stylu; písmeno za číslem udává, zda jde o původně psaný text
(písmeno w) nebo o přepis mluvené řeči, tzv. mluvený text (písmeno s). Jména souborů jsou také
součástí identifikátorů vět a prvků vět obsažených v těchto souborech, např. <m id="m-n01w-s1W1">
v tabulce 3.5. V příloze A jsou uvedena jména souborů pro jednotlivé dokumenty.
Příklad: Soubory se jménem podle šablony a[0-9][0-9]s* obsahují přepisy mluvené
řeči s administrativním obsahem.
Ve formátu PML přípona souboru vyjadřuje rovinu anotace dokumentu. Přípona .w označuje w-rovinu, .m označuje m-rovinu a .a označuje a-rovinu.
Mluvíme potom o w-souborech, m-souborech a a-souborech. Ke každému a-souboru existuje právě jeden m-soubor a právě jeden w-soubor. Z každého a-souboru vedou odkazy do příslušného m-souboru a w-souboru a z každého m-souboru vedou odkazy
do příslušného w-souboru (viz výše). Z tohoto důvodu by soubory neměly být přejmenovány.
Z w-souboru do m-souboru (ani do a-souboru) odkazy nevedou, stejně tak nevedou odkazy z m-souboru do a-souboru.
Ve formátu CSTS je pouze jediná přípona pro všechny soubory, a sice přípona "csts".
Příklad: s17w.a označuje soubor obsahující anotace na a-rovině
odborného psaného dokumentu. Ze souboru vedou odkazy do souborů s17w.m a s17w.w,
ze souboru s17w.m vede odkaz do souboru s17w.w.
Název s17w.csts označuje CSTS soubor, který obsahuje anotace ze všech tří anotačních rovin (w-rovina, m-rovina, a-rovina)
odborného psaného dokumentu.
ČAK 2.0 sestává ze 180 ručně anotovaných textových dokumentů obsahujících celkem 31 707 vět s 652 131 slovními jednotkami (tyto údaje jako i všechny ostatní jsou počítány z m-souborů). Slovních jednotek bez interpunkce je 570 760. Slovních jednotek bez interpunkce a bez čísel zapsaných číslicemi je 565 910. V tabulce 3.8 jsou uvedeny velikosti jednotlivých částí dat rozdělených podle stylu a podle formy.
Tabulka 3.8. Velikost jednotlivých částí ČAK 2.0 podle stylu a formy
| styl | forma | počet souborů | počet vět | počet slovních jednotek | počet slovních jednotek bez interpunkce | počet slovních jednotek bez interpunkce a bez čísel zapsaných číslicemi |
|---|---|---|---|---|---|---|
| publicistický | psaná | 52 | 10 234 | 189 435 | 165 469 | 163 693 |
| publicistický | mluvená | 8 | 1433 | 28 737 | 24 864 | 24 859 |
| odborný | psaná | 68 | 11 113 | 245 174 | 216 280 | 214 127 |
| odborný | mluvená | 32 | 4576 | 115 853 | 100 281 | 100 272 |
| administrativní | psaná | 16 | 3362 | 58 697 | 51 431 | 50 524 |
| administrativní | mluvená | 4 | 989 | 14 235 | 12 435 | 12 435 |
| celkem | psaná | 136 | 24 709 | 493 306 | 433 180 | 428 344 |
| celkem | mluvená | 44 | 6998 | 158 825 | 137 580 | 137 566 |
| celkem | psaná a mluvená | 180 | 31 707 | 652 131 | 570 760 | 565 910 |
Zvlášť uvádíme v tabulce 3.9 kvantitativní údaje pro znaky '#' a '?', které byly ručně vloženy do ČAK jakožto znaky zástupné za chybějící slova a čísla zapsaná číslicemi.
Tabulka 3.9. Kvantitativní charakteristiky ČAK 2.0 – vložené znaky '#' a '?'
| styl | forma | počet výskytů '#' (v počtu vět) | počet výskytů '?' (v počtu vět) | počet výskytů '#' nebo '?' (v počtu vět) | počet vět bez vložených symbolů |
|---|---|---|---|---|---|
| publicistický | psaná | 1776 (1187) | 925 (680) | 2701 (1563) | 8671 |
| publicistický | mluvená | 5 (5) | 25 (25) | 30 (30) | 1403 |
| odborný | psaná | 2153 (1224) | 2230 (1418) | 4383 (2031) | 9082 |
| odborný | mluvená | 9 (9) | 131 (108) | 140 (113) | 4463 |
| administrativní | psaná | 907 (616) | 635 (476) | 1542 (919) | 2443 |
| administrativní | mluvená | 0 (0) | 16 (15) | 16 (15) | 974 |
Pro úplnost dodáváme, že každý zveřejněný experiment provedený na datech ČAK 2.0 by měl obsahovat informaci o tom, jaká část dat byla pro jaký účel v experimentu použita.
Souhrnně konstatujeme, že anotace ČAK 2.0 je rozdělena do tří rovin,
a to do roviny slovní (w-rovina), morfologické (m-rovina) a analytické (a-rovina). Každá z těchto rovin má vlastní PML schéma
(v adresáři data/schemas/
soubory wdata_schema.xml, mdata_schema.xml, adata_schema.xml).
Adresář data/pml/
obsahuje celkem 496 souborů, a to 180 w-souborů, 180 m-souborů a 136 a-souborů. Mluvené texty nebyly anotovány na analytické rovině. Pokyny pro analytickou anotaci psaných textů není možné aplikovat na mluvené texty.
data/csts/, který
obsahuje celkem 180 souborů, z toho 136 souborů obsahuje morfologickou a syntaktickou anotaci,
zatímco 44 souborů obsahuje pouze morfologickou anotaci.
Vzhledem k motivaci přičlenit ČAK k PZK předkládáme tabulku 3.10, kde je uvedeno základní srovnání obou korpusů. Všímáme si pouze těch charakteristik, které mají oba korpusy společné. K přímému začlenění ČAK do PZK dojde někdy v budoucnu při vydání další verze PZK.
Tabulka 3.10. Srovnání ČAK 2.0 a PZK 2.0
| charakteristika | PZK 2.0 | ČAK 2.0 | |||
|---|---|---|---|---|---|
| počet slov (tis.) | počet vět (tis.) | počet slov (tis.) | počet vět (tis.) | ||
| anotace morfologická | 2000 | 116 | 652 | 32 | |
| anotace analytická | 1500 | 88 | 493 | 25 | |
| forma psaná | 2000 | 116 | 493 | 25 | |
| forma mluvená | -- | -- | 159 | 7 | |
| styl publicistický | 1620 | 94 | 218 | 12 | |
| styl administrativní | -- | -- | 73 | 4 | |
| styl odborný | 380 | 22 | 361 | 16 | |
Anotování dat, opravy anotací, vyhledávání v anotovaných datech a zpracování dat automatickými procedurami zprostředkovává celá řada nástrojů. Vzhledem k tomu, že ČAK 2.0 je korpus anotovaný na m-rovině a a-rovině, nabízíme nástroje, které umožňují práci s daty, tedy i s ČAK, právě na těchto dvou rovinách. Tabulka 3.11 poskytuje základní orientaci v nástrojích, které jsou součástí CD-ROM. Pro každý nástroj je uvedena jeho základní charakteristika spolu s určením, na jaký druh práce je nástroj vhodný. V dalších oddílech pak následuje podrobnější popisy jednotlivých nástrojů.
Tabulka 3.11. Přehled nástrojů
| nástroj | popis | určení |
|---|---|---|
| Bonito | korpusový manažer |
|
| LAW | morfologický anotační editor |
|
| TrEd | syntaktický anotační editor |
|
| Netgraph | korpusový prohlížeč |
|
| tool_chain | automatická procedura pro zpracování českých textů |
|
Grafický nástroj Bonito [32] ulehčuje uživatelům práci s jazykovými korpusy, zejména při vyhledávání a při základních statistických
výpočtech nad vyhledanými daty. Bonito je nadstavbou korpusového manažeru Manatee, který provádí nejrůznější operace nad korpusovými
daty. Podrobná dokumentace k nástroji Bonito je součástí nástroje samotného a vyvolá se z hlavního
menu Nápověda.
Hlavní obrazovka Bonito je uvedena na obrázku 3.1. Základní ovládání nástroje ukážeme na konkrétních příkladech.

Vysvětlivky k obrázku 3.1
1 Hlavní menu
2 Tlačítko pro výběr korpusu
3 Dotazovací řádek
4 Hlavní okno pro zobrazení výsledků dotazu
5 Sloupec s výskyty odpovídajícími dotazu
6 Konkordanční řádky
7 Vybrané konkordanční řádky
8 Vedlejší okno pro zobrazení historie dotazu a širšího kontextu
9 Stavový řádek
Z korpusového nástroje Bonito je možné vyvolat morfologickou analýzu, a to z menu
Manažer | Morfologie. Nové okno, které tak otevřete, si můžete nechat připravené po celou dobu práce s korpusovým nástrojem. Můžete z něj spouštět morfologickou analýzu nebo syntézu (generování). Morfologická analýza zadaného slova vypíše všechna možná lemmata a příslušné značky. Při zaškrtnutí syntézy zase dostanete všechny možné slovní tvary, které lze ze zadaného lemmatu vytvořit, spolu s jejich morfologickými značkami. Viz obr. 3.2.

Tutoriál obsahuje podrobnější návod pro práci s Bonito.
LAW (Lexical Annotation Workbench, [33]) je integrované prostředí pro morfologické anotování. Podporuje přímou morfologickou anotaci (tj. přiřazování lemmatu a značky danému slovu), porovnání anotací jednoho textu (například vytvořených více anotátory), vyhledávání slov, značek atd. Editor pracuje na všech operačních systémech, které podporují Javu, včetně systémů Windows a Linux. LAW je otevřeným systémem rozšiřitelným prostřednictvím externích modulů – např. pro různá zobrazení dat, import/export souborů a nápovědy. LAW podporuje formáty PML [14], csts [12] a TNT [38].
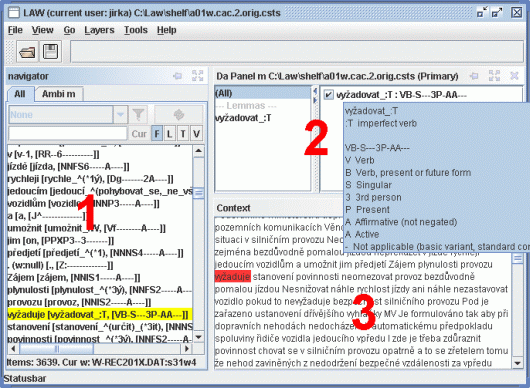
Navigátor – zobrazuje seznamy slov dokumentu filtrované podle různých kritérií a umožňuje výběr určitého slova pro disambiguaci.
Da Panely – zobrazují morfologickou informaci o slovu a umožňují její disambiguaci, tzn. výběr správného lemmatu a značky. Panel se skládá ze dvou oken – seznamu skupin a seznamu položek. Seznam položek zobrazuje všechna lemmata a značky přiřazené danému slovu (na dané m-rovině). Pomocí seznamu skupin lze položky omezit jen na určité lemma, slovní druh, podrobný slovní druh nebo rod. Jeden Da Panel je vždy hlavní (primary), určité akce se pak týkají jen tohoto panelu (např. Ctrl-T aktivuje seznam lemmat a značek v hlavním panelu).
Kontextová okna – kontextové informace, např. text dokumentu, syntaktické struktury atd.
Otevřete m-soubor, který chcete anotovat:
File | Open(Ctrl-O). Odpovídající w-soubor se otevře automaticky.Přepněte se v Navigátoru do seznamu nejednoznačných slov (Ambi + jméno daného m-souboru), ve kterém se zobrazí nejednoznačná slova, tj. slova, pro která morfologická analýza nabízí více možností, a vyberte ze seznamu první slovo.
-
Zmáčkněte
Enter. Kurzor se přesune do hlavního Da Panelu. Vyberte správné lemma a značku a opět zmáčkněteEnter. Kurzor se přesune na další nejednoznačné slovo.Pokud uděláte chybu, přepněte se v Navigátoru do seznamu všech položek (All), nalezněte chybně anotované slovo a vyberte jej. Příslušná anotace se zobrazí v Da Panelu. Vyberte správné lemma a značku a přepněte se zpátky do seznamu nejednoznačných slov (Ambi X).
Uložte výsledek anotování:
File | Save(Ctrl-S).
TrEd (Tree Editor, [37]) je integrovaným prostředím primárně navrženým pro syntaktické anotování vět, při kterém je větě přiřazena stromová struktura. Zároveň může být použit i k prohlížení dat a obsahuje také několik druhů vyhledávacích funkcí.
TrEd podporuje vstupní a výstupní formáty PML a CSTS, které jsme čtenářům již představili v části 3.2.1. TrEd je zároveň modulárním systémem, proto je snadné doplnit podporu pro další formáty.
TrEd nabízí různé možnosti nastavení v závislosti na požadavcích uživatele. Jeho funkčnost může být dále rozšířena pomocí uživatelsky definovaných maker v jazyce Perl, které je možné vyvolat buď přímo klávesovou zkratkou, nebo přes položku v menu.
Programátorsky orientované uživatele bude jistě zajímat varianta nástroje TrEd bez grafického rozhraní, a to nástroj btred pro dávkové zpracování dat (Batch-mode Tree Editor). Dalším doplňkem je nástroj NTrEd, který umožňuje paralelizovat procesy spuštěné nástrojem btred jejich distribucí na více výpočetních strojů.
Pro otevření souborů v TrEd zvolte menu File | Open. Vyberte jakýkoliv soubor *.a (tj. soubor s analytickou anotací) nebo soubor *.csts, TrEd jej otevře a ihned zobrazí strom pro první větu daného souboru.
Typický vzhled TrEdu je na na obrázku 3.4. Jde o větu Problémy motivace jsou tak staré jako lidstvo. Vysvětlivky následují.
1 Okno se stromem, který reprezentuje analytickou anotaci věty.
2 Věta.
3 Stavový řádek. Zobrazuje pro vybrané slovo (zvýrazněný uzel, zde Problémy) různé informace (zde identifikační číslo uzlu, lemma a morfologická značka).
4 Aktuální kontext. Kontext je prostředí, ve kterém uživatel pracuje s anotacemi. V jednom kontextu je povoleno pouze anotace prohlížet (např. v kontextu PML_A_View se dají prohlížet analytické anotace), v jiném je měnit (např. v kontextu PML_A_Edit se dají analytické anotace měnit). Kontext je možné změnit kliknutím na jméno aktuálního kontextu a následným výběrem nového kontextu ze zobrazeného seznamu.
5 Aktuální zobrazovací styl. Může být změněn podobným způsobem jako kontext.
6 Editace zobrazovacího stylu.
7 Zobrazení seznamu všech vět aktuálního souboru.
8 Tlačítka pro otevření, uložení a opětovné otevření souboru.
9 Tlačítka pro přesunutí na předchozí/následující strom v aktuálním souboru a pro správu oken.
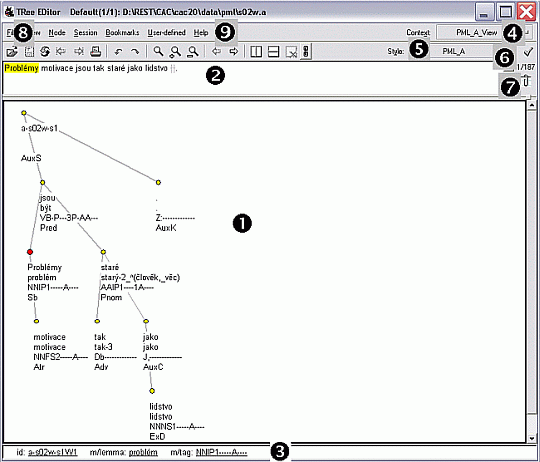
Soubory ČAK 2.0 jsou implicitně otvírány v kontextu PML_A_View, který neumožňuje jejich editaci, pouze prohlížení.
Pokud si přejete soubory měnit, přepněte se do kontextu PML_A_Edit. V obou kontextech je k dispozici jeden zobrazovací styl – PML_A.
V libovolném kontextu můžete zobrazit seznam všech maker definovaných v daném kontextu a jejich klávesové zkratky, a to vybráním menu
View | List of Named Macros.
Netgraph [35] je aplikace typu klient-server, která umožňuje prohledávat ČAK 2.0 současně několika uživateli připojenými přes internet. Netgraph je navržený tak, aby prohledávání bylo co nejjednodušší a intuitivní, při zachování vysoké síly dotazovacího jazyka (Mírovský, 2008).
Dotaz v Netgraphu je jeden uzel nebo strom s vlastnostmi definovanými uživatelem, který má být vyhledán v korpusu. Prohledávání korpusu pak znamená hledání vět (samozřejmě ve formě anotovaných stromů), v nichž je hledaný uzel nebo strom obsažen. Uživatel má možnost zadat dotazy nejrůznější složitosti, od těch nejjednodušších (jako je hledání všech stromů korpusu, které obsahují dané slovo) po pokročilejší (jako např. hledání všech vět, obsahujících sloveso rozvité objektem, který není ve třetím pádě, a nejméně jedním příslovcem atd.). Dotazy mohou být dále rozšířeny tzv. meta atributy, které umožňují vyhledávat ještě složitější konstrukce.
Dotazy se v Netgraphu vytvářejí v uživatelsky přívětivém grafickém prostředí. Příkladem
je dotaz na obrázku 3.5. V tomto jednoduchém dotazu hledáme všechny stromy,
které obsahují uzel označený jako predikát rozvitý nejméně dvěma uzly označenými jako subjekt a objekt.
Pořadí těchto uzlů v nalezených stromech není v dotazu nijak omezeno.

Jedním z výsledků, které server vyhledá, může být strom z obrázku 3.6.
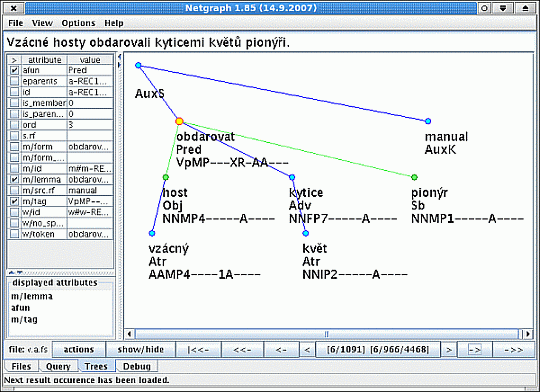
Uživatel vždy používá klientskou část programu Netgraph. Tímto klientem se může připojit k veřejnému
serveru quest.ms.mff.cuni.cz na portu 2001. Pokud si uživatel nainstaluje i serverovou
část Netgraphu, může se připojit lokálně k tomuto vlastnímu serveru a prohledávat korpus bez přístupu
k internetu.
Paralelně s prací nad daty jsou vyvíjeny aplikace pro morfologické a syntaktické zpracování českých textů. Součástí CD-ROM jsou dvě základní morfologické aplikace – morfologická analýza a tagování – a jedna syntaktická aplikace – parsování. Tyto tři aplikace jsou doplněny tokenizací.
Tokenizace je proces, který rozdělí daný text na jednotlivá slova. Výsledkem je tzv. vertikála, tedy soubor, v němž je každé slovo nebo interpunkční znaménko na zvláštním řádku. Pod pojmem tokenizace se často rozumí i tzv. segmentace, což je označení začátků odstavců a vět. I naše tokenizace text současně segmentuje.
V našem pojetí je však tokenizace ještě něco navíc – převádí vertikálu do formátu CSTS (viz část „Formát CSTS“). Převod do tohoto formátu spočívá hlavně v přidání hlavičky před vertikálu a označení jednotlivých slov jednoduchými značkami, které rozlišují vlastnosti slov viditelné přímo z jejich ortografického zápisu. Jde zejména o odlišení interpunkčních znamének, čísel zapsaných číslicemi nebo slov obsahujících číslice. Dále se speciální značkou označí slova začínající velkým písmenem a slova, která jsou celá napsána velkými písmeny. Výsledek tokenizace, tedy vertikála ve formátu CSTS, je potom přímo vstupním formátem pro další zpracování.
Morfologická analýza zpracovává jednotlivé slovní formy a určuje pro ně lemmata (základní tvary, např. pro podstatná jména první pád jednotného čísla, pro slovesa infinitiv) a možné morfologické interpretace.
Základem morfologické analýzy je morfologický slovník, který obsahuje tvaroslovné informace o českých slovech a jejich tvarech. Každý slovní tvar má přiřazeno lemma a morfologickou značku (morfologický tag), která popisuje morfologické vlastnosti tohoto tvaru. V použitém morfologickém slovníku mají mnohá lemmata doplňující informace o stylu, sémantice nebo o způsobu odvození. V případě zkratek bývají lemmata opatřena komentářem s vysvětlujícím textem v příloze B.
Vzhledem k vysoké homonymii češtiny lze většině slovních tvarů přiřadit více morfologických značek, občas i více lemmat. Např. slovní tvar pekla má dvě různá lemmata – podstatné jméno peklo a sloveso péci. Obě lemmata dále mohou pro uvedený slovní tvar mít několik různých morfologických značek. Při morfologické analýze se probírají jednotlivé slovní formy z celého korpusu a porovnávají se se slovními formami obsaženými v morfologickém slovníku. V případě shody se danému slovnímu tvaru přiřadí příslušná lemmata a morfologické značky. Výsledkem morfologické analýzy pro konkrétní slovo je tedy množina dvojic lemma–morfologická značka.
Na morfologickou analýzu navazuje tagování (někdy také desambiguace nebo disambiguace). Během této fáze se vybere ze všech možných lemmat a morfologických značek přiřazených v předchozí fázi jediná dvojice, která by měla být v konkrétním kontextu správná. Vzhledem k obtížnosti úlohy není možné navrhnout takovou metodu tagování, která by pracovala se stoprocentní úspěšností. Program, který tagování provádí, je označován jako tagger. Tagger, který je součástí CD-ROM, je založen na skrytých markovovských modelech s využitím průměrovaného perceptronu (Collins, 2002). Jedná se o metodu statistickou. Vstupem taggeru je text, který pro každé slovo obsahuje množinu všech možných morfologických značek a lemmat (výstup z morfologické analýzy). Na výstupu pak k těmto datům přidává jednoznačně vybranou značku a jí odpovídající lemma. Tagger byl natrénován na datech PZK 2.0.
Parsování představuje další úroveň zpracování textů, která navazuje na tagování. Při parsování se pro každé slovo věty určí jeho syntaktická závislost na jiném slovu věty a přiřadí se mu analytická funkce. Program, který parsování provádí, je označován jako parser. Parser, který je součástí CD-ROM, je založen na stejné metodologii jako použitý tagger. Vstupem parseru je text, který pro každé slovo textu obsahuje právě jednu dvojici lemma-morfologická značka. Na výstupu je stromová struktura ohodnocená analytickými funkcemi. Parser byl natrénován na trénovacích datech PZK 2.0.
Aby uživatel mohl nástroje pohodlně používat, vytvořili jsme skript tool_chain, který prostřednictvím
základních přepínačů dokumentovaných v tabulce 3.12 spustí požadovaný nástroj. Řetězením přepínačů je možné spustit více nástrojů za sebou.
Příklad: Chceme-li surový text zpracovat morfologickou analýzou, spustíme tool_chain -tA
Připomenutí:
Při práci s formátem PML musí být se souborem, který vstupuje do skriptu tool_chain, v adresáři i soubory, na které se z něho odkazuje.
Pokud je vstupním souborem m-soubor, musí ho „doprovázet“ i příslušný w-soubor.
Tabulka 3.12. Skript tool_chain
| parametr | typ zpracování | formát vstupního souboru |
formát výstupního souboru |
|---|---|---|---|
-t |
tokenizace | surový text | CSTS |
-A |
morfologická analýza | CSTS | PML m-soubor, CSTS |
-T |
tagování | PML m-soubor, CSTS (výstup morfologické analýzy) | PML m-soubor, CSTS |
-P |
parsování | PML m-soubor, CSTS | PML a-soubor, CSTS |
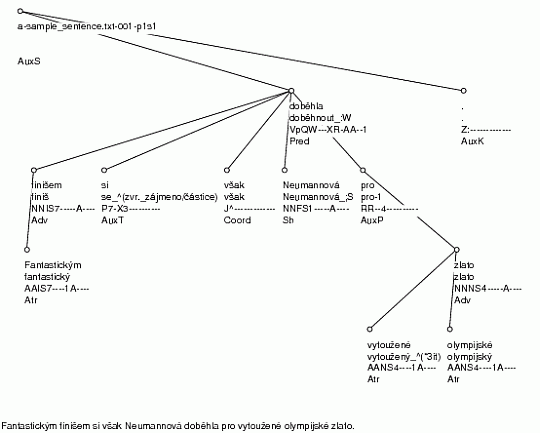
Příklad: Ukážeme zpracování věty
Fantastickým finišem si však Neumannová doběhla pro vytoužené olympijské zlato.
Výsledky morfologické analýzy (spuštěním tool_chain -tA) a tagování
(spuštěním tool_chain -T) jsou
souhrnně uvedeny v tabulce
3.13.
V případě více možných lemmat odpovídajících dané slovní
formě (např. slovní forma si je analyzována buď jako sloveso být, nebo jako zvratná částice
se) jsou tyto základní tvary odděleny symbolem svislého lomítka „|“. Abychom usnadnili čtenáři pátrání po chybách, kterých
se tagger dopustil, potvrzujeme, že se tagger žádných chyb nedopustil.
Výsledek parsování (spuštěním tool_chain -P) je uveden na obrázku 3.7.
U každého uzlu stromu je zobrazena slovní forma, zjednoznačněné lemma, zjednoznačněná morfologická značka a analytická funkce.
Abychom i v tomto případě usnadnili čtenáři pátrání po chybách, potvrzujeme, že se parser žádné chyby nedopustil.
Tabulka 3.13. Ukázka textu zpracovaného morfologickou analýzou a tagováním
| vstupní text | výsledek morfologické analýzy | výsledek tagování |
|---|---|---|
| Fantastickým | fantastický AAFP3----1A---- AAIP3----1A---- AAIS6----1A---7 AAIS7----1A---- AAMP3----1A---- AAMS6----1A---7 AAMS7----1A---- AANP3----1A---- AANS6----1A---7 AANS7----1A---- | fantastický AAIS7----1A---- |
| finišem | finiš NNIS7-----A---- | finiš NNIS7-----A---- |
| si | být VB-S---2P-AA--7|se_ ^(zvr._zájmeno/částice) P7-X3---------- | se_^(zvr._zájmeno/částice) P7-X3---------- |
| však | však J^------------- | však J^------------- |
| Neumannová | Neumannová_;S NNFS1-----A---- NNFS5-----A---- | Neumannová_;S NNFS1-----A---- |
| doběhla | doběhnout_:W VpQW---XR-AA--1 | doběhnout_:W VpQW---XR-AA--1 |
| pro | pro-1 RR--4---------- | pro-1 RR--4---------- |
| vytoužené | vytoužený_^(*3it) AAFP1----1A---- AAFP4----1A---- AAFP5----1A---- AAFS2----1A---- AAFS3----1A---- AAFS6----1A---- AAIP1----1A---- AAIP4----1A---- AAIP5----1A---- AAMP4----1A---- AANS1----1A---- AANS4----1A---- AANS5----1A---- | vytoužený_^(*3it) AANS4----1A---- |
| olympijské | olympijský AAFP1----1A---- AAFP4----1A---- AAFP5----1A---- AAFS2----1A---- AAFS3----1A---- AAFS6----1A---- AAIP1----1A---- AAIP4----1A---- AAIP5----1A---- AAMP4----1A---- AANS1----1A---- AANS4----1A---- AANS5----1A---- | olympijský AANS4----1A---- |
| zlato | zlato NNNS1-----A---- NNNS4-----A---- NNNS5-----A---- | zlato NNNS4-----A---- |
| . | . Z:------------- | . Z:------------- |
Pro vyzkoušení nástrojů uživatelům doporučujeme , aby si vybrali libovolný český text a zpracovali jej skriptem tool_chain -tA . Následně
výstup skriptu otevřete v nástroji LAW a začněte zjednoznačňovat přiřazené značky slov.
Soubor s ručně zjednoznačněnými značkami zpracujte skriptem tool_chain -P. Následně výstup skriptu
otevřete v nástroji TrEd a můžete začít opravovat závislosti a analytické funkce.