Prague Czech-English Dependency Treebank 3.0
PCEDT 3.0
English tectogrammatical layer in a nutshell
Content
Introduction
What is the tectogrammatical layer for?
The tectogrammatical annotation is built above the analytical layer. Like the analytical layer, it captures syntactic dependencies, but it is more semantically oriented and provides additional linguistic information. The basic idea about the tectogrammatical representation is that it emphasizes the similarities between languages and moderates their differences. The tectogrammatical representation of a sentence in a source language and in its translation to a target language are more similar than their analytical representations, since many language-specific features are cleared away from the tree structure into the inner structure of the nodes.
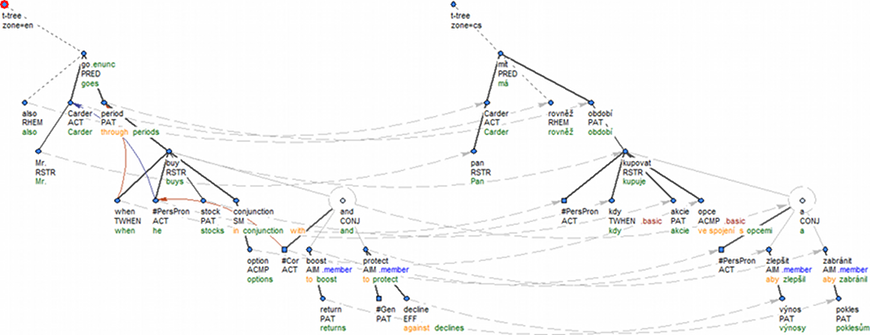
Figure 1
For illustration, the Penn Treebank sentence 1600/32 got a very precise translation to Czech and thus the source sentence and the target sentence ought to be represented in a similar way, if semantics is concerned.
[en] Mr. Carder also goes through periods when he buys stocks in conjunction with options to boost returns and protect against declines.
[cs] Pan Carder má rovněž období, kdy kupuje akcie ve spojení s opcemi, aby zlepšil výnosy a zabránil poklesům.
The translation is precise, but not literal. The Czech sentence does not use the most straightforward translation of the main predicate (má means has, while the English predicate says goes through) and the English infinitive clause to boost returns and protect against declines that serves as an adverbial purpose clause corresponds to a finite past-tense subordinate clause introduced by the subordinator aby. This is a systematic difference between Czech and English. The tectogrammatical representations smooth out these lexical and structural differences anchored in the very text, as Figure 1 demonstrates. For instance, the arguments and adjuncts of the main predicates get identical semantic labels and it does not even matter that one takes a direct object while the other takes a prepositional object. The structural difference between the English infinitive clause and the Czech finite subordinate clause with a subordinator is also "hidden"; i.e. it has moved from the tree structure into the inner structure of the nodes, partly as a number of different attribute values, partly as references to the analytical layer. The analytical representations, on the other hand, preserve these differences in the tree structure (Figure 2).
The most essential differences between the analytical layer and the tectogrammatical layer are:
- Of tokens realized in the text, only content words and coordinating conjunctions are represented as nodes in the tree. The linguistic information contributed by function words is stored in the inner structure of the node (see Section Node Structure)
- Instead of what is usually understood as lemma, the tectogrammatical representation introduces t-lemma. This is, especially in the English part, still mostly identical with the base form of a word, but some parts of speech are already rendered by a string introduced by #. This applies e.g. to personal pronouns and negation particles. The original word is normally present on the lower layers, but in the tectogrammatical tree it is encoded by the given t-lemma and a combination of grammatemes (a set of cognitive and grammatical categories - for more detail see Section Grammatemes). For instance, the pronoun he would get the t-lemma #PersPron and grammatemes for definiteness, gender and number. A few t-lemmas with # (we will call them t-lemma substitutes) do not represent any node present on the lower layers, but they are only present on the tectogrammatical layer. Nodes that do not correspond to any surface nodes are called generated nodes. They either get a t-lemma substitute, or they are copies of nodes located elsewhere in the text. All generated nodes have the attribute value is_generated="1".
- The generated nodes are used for instance to restore ellipsis. These generated nodes are either copies of other nodes present in the text, or purely artificial nodes with t-lemma substitutes. Whether a generated node has the t-lemma of an ordinary word or gets a t-lemma substitute depends on the position of the given node in the tree. With a few negligible exceptions, non-terminal nodes are copies of existing nodes with regular t-lemmas, whereas generated terminal nodes get t-lemma substitutes.
- All occurrences of verbs are assigned a frame in the valency lexicon Engvallex. When the actual usage occurs in a context where not all its obligatory argument slots are occupied, the slots are filled in with generated nodes with t-lemma substitutes (see Valency).
- Not only verb arguments, but all tectogrammatical nodes get semantic labels (functors). These semantic labels describe the syntactico-semantic relation of the given node to its parent (see Functors).
- Anaphora and coreference are resolved, even among the generated nodes.
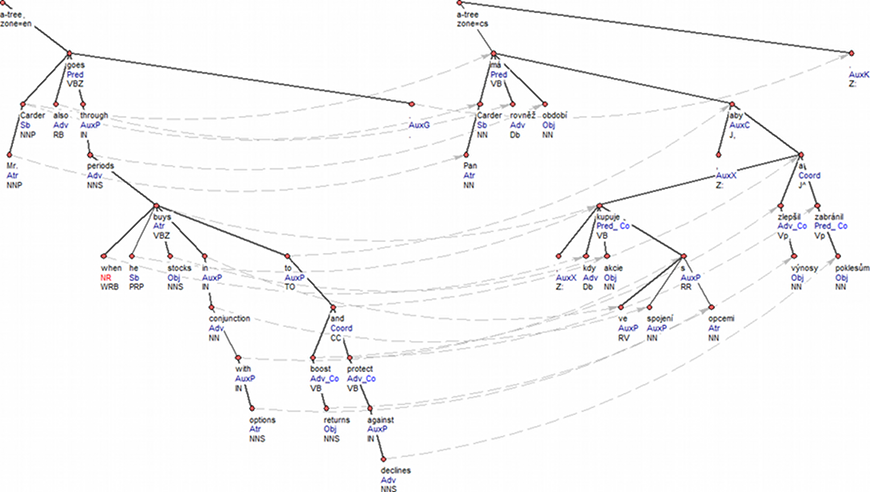
Figure 2
Note on the description of annotation at the English tectogrammatical layer
The general principles of the tectogrammatical representation have been most comprehensively described in the specification of the Czech tectogrammatical annotation. This has appeared in two versions. There are a comprehensive volume and an abbreviated version. Both contain a complete technical description of the data. The comprehensive specification gives the reader a detailed insight into the annotation of a number of linguistic phenomena. Based on these specifications, a similar documentation was elaborated for the English tectogrammatical representation in 2006. This documentation also contains most of the technical information present in the Czech specifications (e.g. lists of attribute values) and it describes the annotation of selected linguistic phenomena, some specific to English. The English annotation manual, however, suffers from the fact that it was too strongly conceived as a derivation of the Czech annotation manual and, no less, that, at the time of writing, there was no convenient tool available to non-programming linguists for querying the English data. The linguistic phenomena were thus selected and described on the basis of grammar textbooks and searches in the British National Corpus rather than based on the actual PTB-WSJ data. Later, we were confronted with the real PTB-WSJ data during the massive annotation and it turned out that some phenomena frequently represented in WSJ-PTB were neglected, while others, extensively presented in the textbooks, were only marginal issues in the American financial press texts. Particularly when the PML Tree Query engine was launched and querying the corpus became amazingly easy, it was plain to see that many linguistic instructions mentioned in the English manual proved untenable in practice, while other instructions kept throughout the corpus have not found their way into the manual. This brief description of the English tectogrammatical representation is meant to support the obsolete 2006 English annotation manual. We are still consulting a balanced corpus, whenever the PTB-WSJ data do not seem to be telling the whole story of a linguistic phenomenon, but instead of the BNC we then use the half-billion Corpus of Contemporary American English (COCA), which became freely available in 2008.