



, konkrétně s daty pocházejícími z novin Wall Street Journal. Chtěli jsme si to udělat po svém (závislostně) a chtěli jsme to paralelně (angličtina i čeština).")


Získání analytického parsu pro češtinu
Česká analytická rovina je do detailů popsána v anotačním manuálu pro anotaci analytické roviny. Ruční analytická anotace vzniká z plain textu. Na PCEDT 2.0 se nachází 2000 takto anotovaných vět. Většina českých textů má ovšem pouze automaticky generovanou a-rovinu, která je oproti manuálu pro ruční anotaci poněkud zjednodušená; chybí například vyznačení dvojích závislostí.
Získání analytického parsu pro angličtinu
Anglická analytická rovina byla získána automatickou konverzí výstupu automatického parseru. Pro vybudování PCEDT jsme použili dependenční parser MST and Pennconverter.
Stromové struktury generované MST parserem se v několika ohledech liší od analytických stromů definovaných anotačním schématem PDT pro češtinu (manuál pro ruční anotaci anglické analytické roviny zatím neexistuje). Jelikož jsme chtěli, aby tato rovina (i když pouze automaticky generovaná), byla co nejpodobnější originální české anotaci analytické roviny, provedli jsme ještě jednu konverzi pomocí NLP platformy Treex. Například u složených slovesných tvarů (would have been playing atp.) nyní pomocná slovesa vždy závisí na uzlu významového slovesa. V této fázi ovšem nebyla přidána žádná "nová" anotace. Výsledná podoba dat se pouze nepatrně liší od analytické roviny definované pro češtinu.
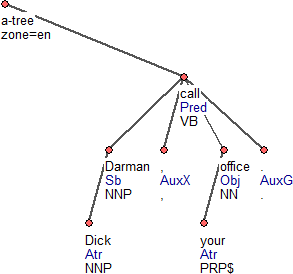
Obrázek 1
Struktura uzlu
Obrázek 1 ukazuje příklad stromu na analytické (povrchově syntaktické) rovině (a-strom). Tato a následující sekce popisují jeho strukturu a vnitřní strukturu jednotlivých uzlů. Anotovaná věta je reprezentována závislostním stromem (s uzly a hranami, jako obvykle). Každý strom má navíc technický kořenový uzel, jehož atributy jsou pouze podmnožinou atributů běžných uzlů. Tyto kořenové uzly se svou definicí liší od všech ostatních uzlů (viz níže).
Analytická rovina se od tektogramatické reprezentace a od složkové reprezentace liší tím, že znázorňuje pouze tokeny, které v lineárně zapsané větě (textu) skutečně existují. Nepoužívá žádné umělé uzly pro "stopy" nebo rekonstrukci elips. S uzly analytické roviny jsou asociovány následující atributy (komplexní nálepky):
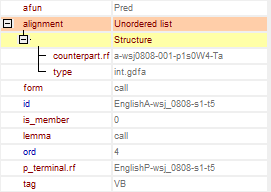
Obrázek 2
- afun: seznam možných hodnot najdete v sekci Seznam analytických funkcí
- id
- ord
- p_terminal.rf: reference k ID příslušného terminálního uzlu (listu) ve složkovém stromě (na p-rovině)
- form
- lemma
- tag: používá se originální tagset z PennTreebank
- no_space_after: přípustné hodnoty jsou "0", "1". Tokeny následované interpunkčním znaménkem mají hodnotu "1".
- is_member: přípustné hodnoty jsou "0", "1". Členy koordinací a jiných "paralelních struktur" mají hodnotu "1".
- alignment: zarovnání s českým analytickým stromem
Obrázek 2 ilustruje vnitřní strukturu uzlu na analytické rovině.
"Afun" znamená analytická funkce. Atribut afun popisuje závislostní vztah mezi závislým uzlem (synem), s kterým je asociován, a jeho řídícím uzlem (rodičem). (Kořenový uzel má vždy afun AuxS, který se u jiných uzlů nepoužívá.) Uzly, které reprezentují běžné tokeny, dostávají různé afuny podle svých syntaktických funkcí ve větě. Seznam afunů a jejich popisy najdete v sekci Section Seznam analytických funkcí.
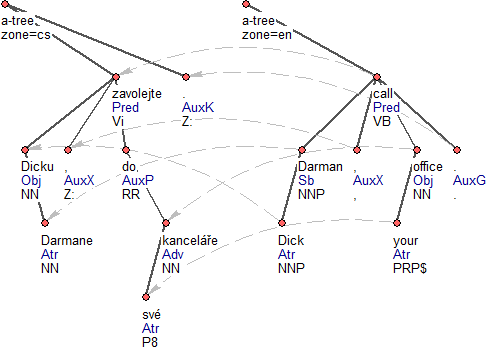
Obrázek 3
Atribut id v PCEDT 2.0 sestává z názvu jazyka, iniciály názvu roviny (A), názvu korpusu, pořadového čísla věty v korpusu (věty jsou číslovány napříč celým korpusem, ne po jednotlivých dokumentech) a čísla daného uzlu. Výjimkou je kořenový uzel. Jeho id neobsahuje žádné číslo uzlu, ale pouze číslo věty.
Atribut ord obsahuje pořadové číslo uzlu v rámci věty. Je to celé číslo, které odpovídá pozici daného tokenu v původním slovosledu. Počítá se od jedničky. Kořenový uzel má vždy ord="0".
PCEDT 2.0 je paralelní korpus automaticky zarovnaný na úrovni vět a tokenů. Zarovnání vede od anglických textů k českým a pro každou rovinu zvlášť. Anglické anotační roviny obsahují informaci o zarovnání ve formě odkazů z anglických uzlů k id odpovídajících českých uzlů. Informace o zarovnání je na anglické analytické rovině uložena v subatributech Alignment-counterpart.rf a Alignment-type. Anglicko-české zarovnání na analytické rovině je dobře vidět na Obrázek 3.
Obrázek 4
Struktura stromu
Nejvyšším uzlem ve stromě je vždy technický kořen (afun AuxS). Větná interpunkce (afun AuxK) závisí přímo na technickém kořenu. Z lingvistického hlediska je nejvyšším uzlem ve stromě samozřejmě hlavní predikát, popřípadě koordinační uzel (afun Coord), pokud řídí několik souřadně spojených hlavních predikátů jako členy koordinace. Rozvíjející slovo je vždy řízeno slovem, které syntakticky rozvíjí. Argumenty a příslovečná určení tedy závisí na slovesu (když je rozvíjejícím slovem předložková fráze nebo podřadná klauze, vstupují mezi ně předložky a podřadící spojky), adjektiva rozvíjející substantiva závisí na substantivech a adverbia rozvíjející adjektiva závisí na adjektivech.
Obrázek 5
Koordinace je řízena uzlem s afunem Coord (viz Obrázek 4. Tím může být interpunkční znaménko (např. čárka, dvojtečka, nebo středník) nebo souřadící spojka (např. and nebo or). Členy koordinace dostávají afuny podle své pozice a funkce v rámci věty, doplněné o příponu _Co. Původní české anotační schéma (pro manuální anotaci) rozlišuje mezi koordinací, apozicí a parentezí. Anglická anotace identifikuje pouze koordinace. Sekvence identifikované jako apozice nebo parenteze se nepovažují za parataktické. Většinou parser identifikuje jejich první člen jako řídící a ostatní pověsí na něj. Hodnotu is_member="1" tak dostávají pouze členy koordinací.
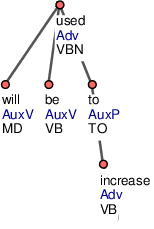
Složené slovesné tvary sestávající z významového slovesa a jednoho nebo několika pomocných sloves jsou vždycky řízeny významovým slovesem. Tento uzel dostane afun podle své pozice a funkce ve větě. Pomocná slovesa jsou jeho dětmi (viz Obrázek 5). Například ve frázi will be used uzel used řídí uzly will i be).
Obrázek 6
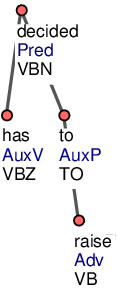
Slovesa kontroly (např. plan to do something) jsou řídícími uzly kontrolovaných sloves (viz Obrázek 6). Také modální slovesa jsou řídícími uzly významových sloves.
Obrázek 7
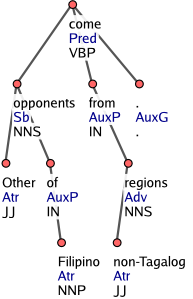
Předložky a podřadící spojky vždy řídí "svá" významová slova. Dostávají afuny pro pomocná slova (AuxP nebo AuxC). Afun vyjadřující funkci daného větného členu ve větě dostane vždy až dané významové slovo. V každé slovesné klauzi je kořenem celého podstromu její hlavní predikát. Například ve větě "I said that I like it", that závisí na said a dostane afun AuxC. Uzel reprezentující slovo that zase řídí uzel like, který nese afun Obj (objekt). Obrázek 7 ukazuje podstrom předložkové příslovečné klauze from non-Tagalog regions, která závisí na slovesu come.
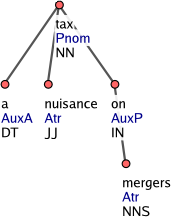
Větné členy rozvíjející předložkové větné členy se považují za přívlastky (afun Atr) a závisí na substantivech (Obrázek 8).
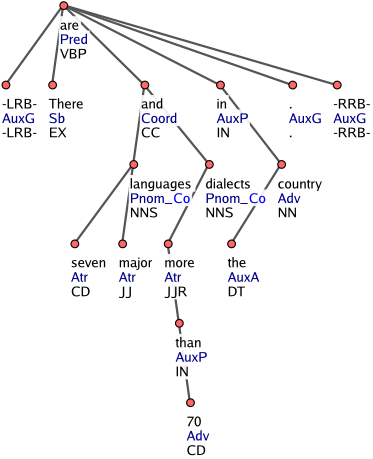
Existenciální there je vždy podmětem klauze. Členy závisí na substantivech a dostávají afun AuxA (tento afun se v češtině nepoužívá). Neslovesné klauze jsou považovány za případy elipsy slovesa a jejich řídící uzel dostává afun ExD.
Seznam analytických funkcí
Možné hodnoty atributu afun (analytical function):
| afun | Popis |
|---|---|
| Pred | Predikát. Uzel, který nezávisí na jiném uzlu (kromě technického kořene). |
| Sb | Subjekt |
| Obj | Objekt |
| Adv | Příslovečné určení |
| Atr | Přívlastek |
| Pnom | Jmenná část jmenného přísudku se sponou. Může jí být substantivum (Martin is a briliant speaker), adjektivum (Joan is pretty), nebo předložková fráze (This was of great importance). Komplementy ostatních sloves jsou označeny jako Obj (e.g. They considered him smart) |
| AuxV | Pomocná slovesa be, have and do, infinitivní částice to, partikule ve frázových slovesech |
| Coord | Koordinační uzel |
| AuxP | Předložka, součást víceslovného předložkového výrazu |
| AuxC | Podřadící spojka, podřadící spojovací výraz |
| AuxK | Větná interpunkce |
| AuxG | Grafické symboly uvnitř věty a takové, které netvoří koordinační uzel (např. čárky ve vícenásobné koordinaci) |
| AuxS | Technický kořen stromu |
| ExD | Technická hodnota signalizující elipsu řídícího uzlu, používá se také jako řídící uzel neslovesných vět. Zkratka znamená "externally dependent" |
| AuxA | Členy a, an, the |
| Neg | Negace vyjádřená částicemi not, n't |
| NR | Nerozpoznaná závislost |
Obrázek 8
Pozor! Anglická analytická anotace vznikla výlučně automaticky, a tudíž obsahuje mnoho chyb ve struktuře i v přiřazení nálepek. Lingvistická informace podávaná analytickou rovinou tedy může být nekonzistetní s lingvistickou informací podávanou ručně anotovanou tektogramatickou rovinou, která na analytickou rovinu odkazuje. V takových případech je samozřejmě správná tektogramatická anotace, s výjimkou anotátorských chyb.