Prague Czech-English Dependency Treebank 3.0
PCEDT 3.0
English analytical layer in a nutshell
Obtaining the analytical parse for English
The English analytical layer has been obtained by an automatic conversion of the output of an automatic parser; in the PCEDT case the dependency MST parser and Pennconverter have been used.
The tree structure as produced by the MST parser differs in certain points from the main guidelines for the PDT-based analytical layer. Since we wanted this layer (albeit automatically generated) to be as close to the Czech annotation (of the same layer) as possible, additional conversion of the output of the parser has been done. For instance, complex verb forms (e.g. would have been playing) are always governed by the lexical verb node while the auxiliary verbs are its daughters. However, no "new" annotation has been introduced at this stage. The resulting annotation style differs from the specification of the analytical layer for Czech only in some minor points.
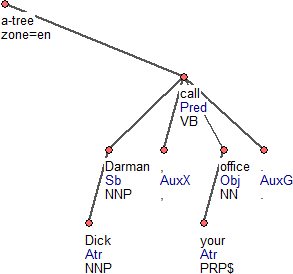
Figure 1
Node structure
Figure 1 presents an example of a tree on the analytical (surface-dependency) layer (an a-layer tree, or a-tree). This section and the following section describe its structure and the inner structure of the complex labels of analytical nodes (a-nodes). The annotated sentence has a form of a dependency tree (with nodes and edges, as usual). Each tree has an extra technical root node, the attributes of which are only a subset of the attributes of the regular nodes and which differ also in their definition from all the other nodes (see below).

Figure 2
Unlike the tectogrammatical representation and the phrase-structure representations, the analytical representation reflects only tokens that are actually present in the text. It does not use any trace- or gap-like "artificial" nodes. The following attributes (complex labels) are attached to the analytical-layer nodes (see also Figure 2):
- afun "Afun" means analytical function. The attribute afun labels the dependency relation between the child node it is attached to and its governing (parent) node. (The root node always has the afun AuxS, used nowhere else.) Nodes that represent regular tokens get different afuns according to their syntactic function in the sentence. Section Analytical function labeling (see below) provides a list of afuns and their descriptions.
- id The id attribute consists (in PCEDT 3.0) of the name of the language, the initial of the layer name (A), the name of the corpus, the ordinal number of the sentence in the corpus (the sentences are numbered throughout the entire corpus) and the number of the node itself. The root node is an exception: its id does not contain any node number but only the sentence number.
- ord The ord attribute keeps the ordinal number of the node within the sentence. It is an integer which corresponds to the position of the token in the original word order, numbered from 1. The root has always ord="0".
- p_terminal.rf: reference to the id of the corresponding terminal node in the phrase-structure tree
- form
- lemma
- tag: the PTB tagset is used
- no_space_after: possible values are 0,1. Tokens followed by a punctuation mark have 1.
- is_member: possible values are 0,1. Members of a coordination or other "parallel structure" have 1.
- alignment The corpus is an (automatically) sentence- and word-aligned parallel corpus. The alignment is directed from the English part to the Czech part, for each layer separately. The English annotation layers contain the alignment information in a form of references from the English nodes to their corresponding Czech nodes, using node IDs. At the English analytical layer, it is the alignment sub-attributes alignment/counterpart.rf and alignment/type. Figure 3 illustrates the English-Czech alignment at the analytical layer.
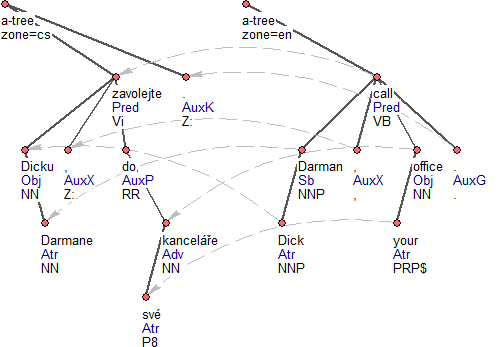
Figure 3
Tree structure
The topmost node in a tree is always the technical root (afun AuxS). The sentence punctuation (afun AuxK) is governed directly by the technical root. Linguistically, of course, the topmost node is (within the dependency framework) always the main predicate, or a coordination node (afun Coord) governing several main predicates as members of the coordination. The modifying word is always governed by the word it syntactically modifies. Hence, arguments and adverbials of a verb are governed by that verb (with a preposition or a subordinator in between, if the modifier is a prepositional phrase or a subordinate clause), adjectives modifying nouns are governed by the nouns and adverbs modifying adjectives are governed by the adjectives.
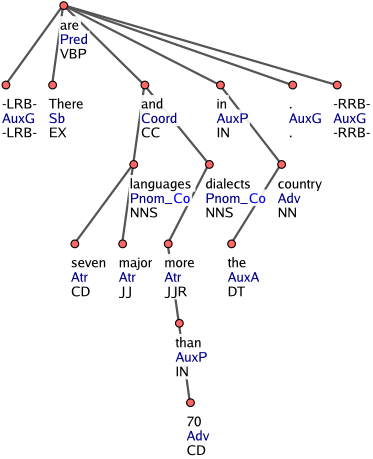
Figure 4
A coordination is governed by a node with the afun Coord (see Figure 4). This can be a punctuation (e.g. comma, colon or semicolon) or a coordinating conjunction (e.g. and, or). The members of the coordination get their afuns according to their position and function in the sentence, followed by the "suffix" _Co. The original Czech annotation scheme distinguishes among coordination, apposition and parenthesis. The English annotation uses this scheme only for coordination; sequences identified as apposition or parenthesis are not regarded as paratactic. Rather, their members are regarded as being governed by the first member. Only coordination members have thus is_member="1".
Complex verb forms consisting of a lexical verb and one or several auxiliary verbs are always governed by the lexical verb. This node gets its afun according to its position and function in the sentence. The auxiliary verbs are its children (see Figure 5). In the group will be used, the node used governs the nodes will and be). Verbs of control (e.g. plan to do something) govern the controlled verbs; so do modal verbs.

Figure 5
Prepositions and subordinating conjunctions always govern "their" content words. They get the "auxiliary" afuns AuxP, AuxC (see Figure 4); it is the content word (governed by a preposition/subordinating conjunction) that gets an afun according to its syntactic function in the sentence. In a clause, the predicate is the root node of the subtree representing the clause. E.g. in the sentence "I said that I like it", that is governed by said and gets the afun AuxC. In turn, that governs the node like, which has the afun Obj (object).
Modifiers of nouns, even the prepositional ones, are treated as Atr (attributes) and are governed by the nouns (Figure 4).
Nominal part of a copular predicate gets the afun Pnom. This can be a noun (Martin is a briliant speaker), an adjective (Joan is pretty) or a prepositional group (This was of great importance). Verb complements of other verbs are marked as Obj (e.g. They considered him smart).
The existential there is always the clause subject (see Figure 4). Determiners are governed by nouns and get the afun AuxA (see Figure 4; the afun AuxA does not exist in Czech). Verbless clauses are treated as cases of verbal ellipsis and the governing node gets the afun ExD.
Analytical function labeling
The possible values of the afun (analytical function) attribute are listed here.
- Pred Predicate. A node not depending on other node.
- Sb Subject
- Obj Object
- Adv Adverbial
- Atr Attribute
- Pnom Nominal part of a copular predicate
- AuxV Auxiliary verbs be, have and do, the infinitive particle to, particles in phrasal verbs
- Coord Coordination node
- AuxP Preposition, parts of a secondary (multiword) preposition
- AuxC Subordinating conjunction, subordinator
- AuxK Terminal punctuation of a sentence
- AuxG Non-terminal and non-coordinating graphic symbols (e.g. commas in a serial coordination)
- AuxS The technical root of the tree
- ExD A technical value signalling a "missing" (elliptical) governing node; stands for "externally dependent"
- AuxA Articles a, an, the
- Neg Negation expressed by the negation particle not, n't
- NR Not recognized dependencies
Please note: the English analytical annotation is only automatic and thus imperfect, with errors both in the structure and in the labeling. Therefore, there might be inconsistency (in terms of the linguistic information provided) along the node links between the manually annotated tectogrammatical layer and the analytical one. In such a case, the tectogrammatical layer (obviously) contains the correct interpretation of the sentence in question (barring annotation errors).