Czech Named Entity Corpus
Introduction
The Czech Named Entity Corpus 1.1 is a corpus of 5868 Czech sentences with manually annotated 33662 Czech named entities, classified according to a two-level hierarchy of 62 named entities. It is a minor update to the Czech Named Entity Corpus 1.0, a first publicly available corpus providing a large body of manually annotated named entities in Czech sentences, including a fine-grained classification. The corpus is available under the CC BY-NC-SA 3.0 license.
NE Hierarchy and Classes
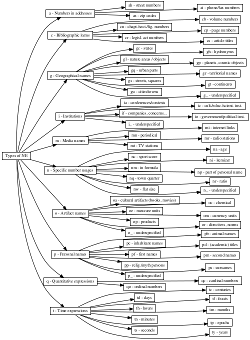 The named entities in Czech are classified according to a two-level hierarchy taken from Ševčíková et al., 2007. The hierarchy is the same as in CNEC 1.0.
The named entities in Czech are classified according to a two-level hierarchy taken from Ševčíková et al., 2007. The hierarchy is the same as in CNEC 1.0.
Data Formats
Named entities are saved in formats:
- plain text – manual annotations in plain text format
- simple xml – simple xml format
- treex – xml format from Treex (formerly TectoMT) with morphologic analysis
- html – html with highlighted named entities
Downloads
Czech Named Entity Corpus 1.1 can be downloaded from LINDAT/CLARIN repository.
Evaluation
The Czech Named Entity Corpus 1.1 is evaluated using the canonical script distributed with the corpus. The evaluation metric is a strict (both span and type must be correct) span-based micro F1.
Changes
The difference between Czech Named Entity Corpus 1.1 and 1.0 are the following:
- fixed some misannotated entities
-
make all formats contain the same data
- provide the same tokenzation in all formats
- add two sentences omitted in some format
- fixed typos in entity names in plain text format
- replaced tmt format by treex format
- removed the original text format
- split all formats into train, dtest and etest, not only treex