Czech Named Entity Corpus
Czech Named Entity Corpus 2.0
The Czech Named Entity Corpus 2.0 is a corpus of 8993 Czech sentences with manually annotated 35220 Czech named entities. It is a major update to the Czech Named Entity Corpus 1.0, a first publicly available corpus providing a large body of manually annotated named entities in Czech sentences, including a fine-grained classification. The corpus is available under the CC BY-NC-SA 3.0 license.
The corpus uses 46 atomic named entity types, which can be embedded, e.g., the
river name can be part of a name of a city as in <gu Ústí nad <gh
Labem>>. There are also 4 so-called NE containers: two or more NEs
are parts of a NE container (e.g., two NEs, a first name and a surname, form
together a person name NE container such as in <P <pf Jan><ps
Novák>>). The 4 NE containers are marked with a capital one-letter
tag: P for (complex) person names, T for temporal
expressions, A for addresses, and C for bibliographic
items.
NE Hierarchy and Classes
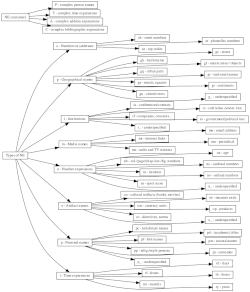 The named entities in Czech are classified according to an updated version of the hierarchy of CNEC 1.0 described in Ševčíková et al., 2007.
The named entities in Czech are classified according to an updated version of the hierarchy of CNEC 1.0 described in Ševčíková et al., 2007.
Data Formats
Named entities are saved in formats:
- plain text – manual annotations in plain text format
- simple xml – simple xml format
- treex – xml format from Treex (formerly TectoMT) with morphologic analysis
- html – html with highlighted named entities
Downloads
Czech Named Entity Corpus 2.0 can be downloaded from LINDAT/CLARIN repository.
Evaluation
The Czech Named Entity Corpus 2.0 is evaluated using the canonical script distributed with the corpus. The evaluation metric is a strict (both span and type must be correct) span-based micro F1.
Changes
Named Entity Hierarchy
The changes in the named entity hierarchy compared to CNEC 1.0 are the following:
-
overhaul the number entities
-
entities of supertype c were merged into n; in order to accommodate bibliographic entities a new type nb “vol./page/chap./sec./fig. numbers” was added
- cs → oa
- cn → nb
- cb → nb
- cp → nb
- cr → n_ , or
-
entities of supertype q were moved into n
- qc → nc
- qo → no
-
low frequent entities of supertype n were removed and some renamed and merged
- removed nm, nr, nw
- nc was renamed to ns
- np → no
- nq → n_
-
some time entities were removed
- tc → no
- tp → no
- tn → nc
- ts → nc
-
entities of supertype c were merged into n; in order to accommodate bibliographic entities a new type nb “vol./page/chap./sec./fig. numbers” was added
- new entity me representing email was added
- gp entity was merged into g
- mr and mt were merged into new ms
- oc entity was merged into o
- pb entity was merged into p
New Data
New data was annotated and added:
- 125 sentences with many addresses and emails were added,
- 3000 sentences containing only a few named entities were added so that the resulting corpus better represents the density of named entities (density of named entities in CNEC 1.1 is too high).