Czech Named Entity Corpus
Czech Named Entity Corpus 1.0
This version of the corpus is outdated. Please use Czech Named Entity Corpus 1.1.
Introduction
The aim of Named Entity Recognition (NER) is to identify proper names in text and to classify them into predefined categories such as names of persons, geographical names, names of organizations etc. The task of NER is motivated by the needs of Natural Language Processing (NLP) applications such as information extraction and machine translation. Similarly to most other tasks in NLP, it is advantageous to use annotated data when developing a named entity recognizer, especially for training and evaluation purposes. The presented Czech Named Entity Corpus 1.0 is the first publicly available corpus providing a large body of manually annotated named entities in Czech sentences, including a fine-grained classification.
NE Hierarchy and Classes
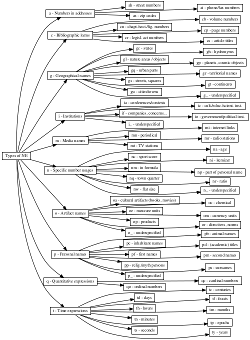 The named entities in Czech are classified according to a two-level hierarchy taken from Ševčíková et al., 2007.
The named entities in Czech are classified according to a two-level hierarchy taken from Ševčíková et al., 2007.
Data Formats
Named entities are saved in formats:
- original text – original manual annotations with comments divided into three parts
- plain text – manual annotations without comments merged into one part
- simple xml – simple xml format
- tmt – xml format from TectoMT with morphologic analysis
- html – html with highlighted named entities
Downloads
Czech Named Entity Corpus 1.0 can be downloaded from LINDAT/CLARIN repository.
Evaluation
Czech Named Entity Corpus 1.0 is evaluated using the canonical script distributed with the corpus. The evaluation metric is a strict (both span and type must be correct) span-based micro F1.