Table of Contents
One of the two main purposes of PDT 2.0 (see the Section 1.1, "What is PDT 2.0") is to give linguists a large number of real-world examples of (not only) the phenomena described previously by various theoretical works on the topic of dependency, tectogrammatical description and on the functional generative description approach in general. Without an intuitive search tool, however, such corpus would be of no or only a limited use.
Naturally, there are many ways how to do it. For instance, the most complex searches can be performed using btred/ntred, but programming skills (specifically, the knowledge of Perl and the btred/ntred interface) are necessary to do so. To most "ordinary" users we recommend Netgraph, a tool designed and developed for searching PDT 1.0 and PDT 2.0.
Netgraph is a client-server application that allows multiple users to search PDT 2.0 on-line and simultaneously through Internet. Netgraph is designed for making the search as easy and intuitive as possible and still keeping the strong power of the query language.
The Netgraph server and client communicate to each other through Internet. The server searches the treebank (the treebank and the server are located on the same computer or local network). The client serves as the front-end for users and may be located at any node in the Internet. It sends user queries to the server and receives results from it. Both the server and the client can, of course, also reside at the same computer.
Netgraph server is written in C and C++ and works smoothly on Linux, other Unix-like systems, and Apple Mac OS. (An experimental version exists for MS Windows, too.) It requires the treebank in the FS format, encoded in UTF-8. Netgraph server allows setting user accounts with various access permissions.
Netgraph client is written in Java and is platform-independent. It exists in two forms-as a stand-alone Java application (which is full-featured and needs to be installed first, along with a Java 2 Runtime Environment), and as a Java applet (which provides the full search power but runs in a web browser without installation; it requires a Java 2 plug-in to be installed in your browser, though).
A query in Netgraph is a single node or a subtree with user-specified properties which s/he wishes to find in the corpus. Searching the corpus thus means searching for sentences (in the form of annotated trees, of course) that contain the query as a subtree. The properties of the subtree which the user can specify range from the most simple ones (such as searching for all trees in the corpus that contain a given word) to very elaborate ones (such as searching for all sentences with any verb that is modified by an Addressee which is not in the dative case and by at least one directional adverbial, etc.) This simple definition is extended using so called meta-attributes in order to allow setting even more complex queries. The meta-attributes allow setting conditions on transitive edges, optional nodes, position of the query nodes in the trees, size of trees, order of nodes, relations between attributes at different nodes in the trees, negation, and many other such things.
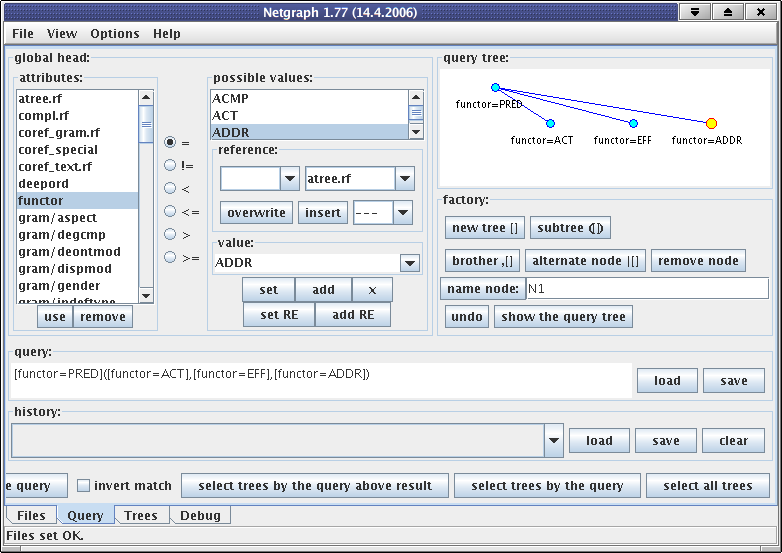
Queries in Netgraph are created using a user-friendly graphic environment. An example of such a query is in Figure 4.1, "Creating a query in Netgraph". In this query, we are interested in all trees containing a node labeled as predicate and governing at least three nodes labeled as Actor, Effect, and Addressee. There is no condition on the order of the nodes.
One of the results (sent back by the server) may look like as in Figure 4.2, "A result tree in Netgraph".
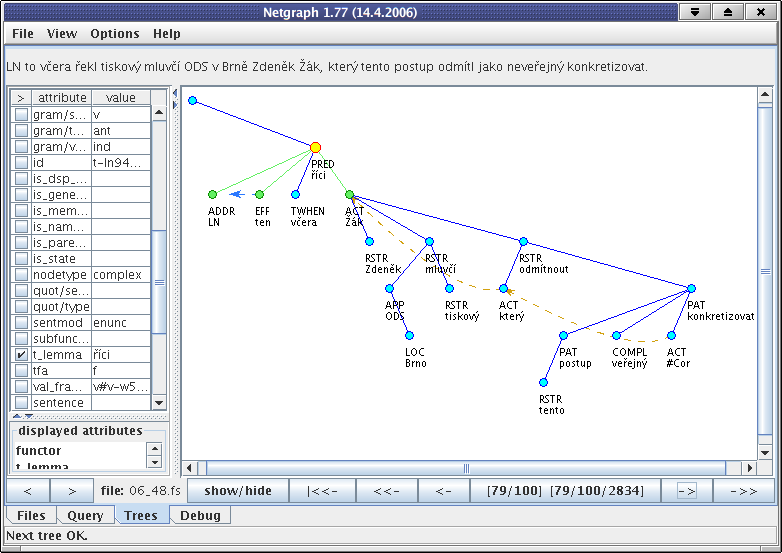
The nodes matching the query are highlighted by yellow and green color. As you can see, the predicate in the result has got more sons than we have specified in the query. This is in accordance with the definition of searching in Netgraph-it is sufficient that the query tree is included in the result tree only as a subtree. Also note that the order of the nodes in the result is different from their order in the query. Meta-attributes allow controlling both the real number of sons and the order of nodes, if required.
For information about how to install Netgraph, see quick installation instructions for Netgraph client and quick installation instructions for Netgraph server. You should also read the Netgraph Client Manual and the Netgraph Server Installation Manual.
Please note that you need to install Netgraph server only if you want to search your own tree corpus. For searching PDT 2.0, a powerful Netgraph server is provided by Institute of Formal and Applied Linguistics at quest.ms.mff.cuni.cz on port 2200. It is accessible for anonymous user via Internet and you can connect to it using Netgraph client (see quick installation instructions for Netgraph client).
For more information about Netgraph, read the Netgraph client manual. If you want a full non-anonymous access to the server, or to get more information, updates and news please visit the Netgraph home page.
The most perspicuous and most comfortable visualization of the data is provided by TrEd. It originally served as the main annotation tool, but it can be used as a data browser as well, with several types of search functions available. For TrEd installation instructions, see TrEd documentation.
To open files in TrEd select the menu and click . Select any of the *.t.gz files (i.e. a file with tectogrammatical annotation of a document) and TrEd will open it and immediately display the tree for the first sentence in the file.
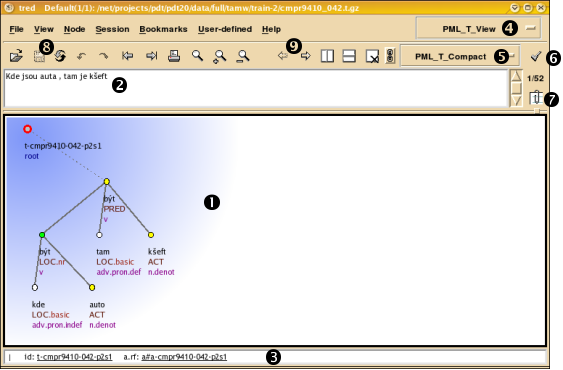
For an illustration of a typical screen, see Figure 4.3, "Tectogrammatical tree in TrEd"; the Czech sentence is Kde jsou auta, tam je kšeft. (lit.: Where are cars, there is business.).
-
Here you can see one or more windowing frames. Each frame displays one tree.
-
In this field you see the plain textual form of the sentence displayed in the currently selected frame.
-
Status line. It displays various information depending on the current context.
-
Current context. You can change the context by clicking on the name and selecting a different one from the list (such as
PML_T_Edit). -
Current stylesheet. It can be changed in a similar way as the context.
-
Click here to edit the stylesheet.
-
Click here to get the list of all the sentences in the current file. The index of the current tree in the current file is displayed above this button.
-
Buttons to open, save and reload a file. The icons mean Undo, Redo, Previous and Next File, Print, Find, Find Next, Find Previous.
-
Buttons for moving to the previous/next tree in the current file and for frame management.
By default, PDT 2.0 tectogrammatical files in the PML format are opened in the PML_T_View context that does not allow the user to edit anything. If you want to edit the files, you can switch to the PML_T_Edit context. In both contexts, two style-sheets are provided. The default one is PML_T_Compact but you can use the PML_T_Full if you want to see more details. For information on contexts and stylesheets, see the documentation of TrEd macros.
In any context, select -> from the menu to see the list of all macros defined in the context and their possible keyboard shortcuts.
Whereas Netgraph (Section 4.1, "Searching trees: Netgraph") allows a non-programmer to comfortably search the PDT trees, and the tree editor TrEd (Section 4.2, "Viewing (browsing) trees: TrEd") allows for a quick, comfortable and customizable browsing and viewing of linguistic tree structures, for tool developers and programmers in general full access to the data becomes necessary. You can always process the data directly (it is XML, after all), but we recommend you to access the data via btred/ntred Perl-based interface tailored for the PDT 2.0 data. btred is a Perl program that allows the user to apply another Perl program (called btred macro) on the data stored in one of the PDT formats. ntred is a client-server version of btred and it is suited for data processing on multiple machines in parallel (mnemonics for btred/ntred: "b" stands for "batch processing", "n" stands for "networked processing").
If you follow the above recommendation, you get several advantages:
- Object-oriented tree representation, which is used in
btred/ntredenvironment, offers a rich repertory of basic functions for tree traversing and for many other basic operations on trees; besides that, several highly non-trivial functions are provided, suitable for linguistically motivated traversing of trees (reflecting e.g. the interplay of dependency and coordination relations). btred/ntredtechnology was extensively used by several programmers during the development of PDT 2.0; this long-time experience has led to many improvements and makes the tools and accompanying libraries reasonably stable.- If you have more computers at your disposal, you can use
ntredand process the data in parallel, which makes the computation considerably faster. Depending on the situation, it may shorten the time needed for passing the whole PDT 2.0 to just a few seconds (with only about 10 CPUs available for the distributedbtredto run on). - Programmers can use
btred/ntred(in combination withTrEd) as a powerful and fast search engine-you write a macro which finds the treebank positions you are interested in, run it byntredand then simply view the retrieved positions inTrEd. - All you need to become fluent in writing
btred/ntredmacros is to know the basics of Perl syntax and to remember a few names of variables and subroutines predefined in thebtred/ntredenvironment. - Once you learn the
btred/ntredstyle of work, you can re-use all of its benefits when processing data from other treebanks (be they dependency- or constituency-based).
Read the btred/ntred tutorial to get started. See also the btred and ntred manual pages.
Conversion between data formats is a tough task unless all the formats can bear exactly the same amount of information. Unfortunately, this is not the case of data formats that emerged over the years of history of PDT. Thus, various tools are provided to make at least some of the conversions easier. They may also serve as examples for more complex transformations required for a particular purpose. For a full description, see PDT 2.0: internal format conversion tools.
In the distribution, the scripts are located in the directory tools/format-conversions/pdt_formats. Most of the scripts also require the btred tool from the TrEd toolkit.
The following types of conversions are supported:
The conversion scripts are provided for the purposes of importing Penn Treebank and Negra corpus formats to FS format. The conversion scripts reside in the directory tools/format-conversions/from_negra+ptb. You can read their short documentation.
Please note that no conversion of annotation schemata is performed. In other words, constituency trees remain constituency trees, no dependency structure is automatically derived.
Together with the data, we also supply tools which perform automatic annotation-they create dependency trees represented at the analytical layer from unannotated Czech sentences. The tools are stored in the directory tools/machine-annotation. The tools perform the following tasks in a sequence:
-
tokenization of the input plain text and segmentation into sentences,
-
morphological analysis and tagging (morphological disambiguation),
-
dependency parsing,
-
analytical (dependency) function assignment for all nodes of the parsed tree.
There are no tools (yet) for the continuation of this process to the tectogrammatical layer. Please watch the web page http://ufal.ms.mff.cuni.cz/pdt2.0update/ with PDT 2.0 updates for updates and new tools.
You can read the detailed description of the tools.
When developing a new parser, it is important to evaluate its performance not only on the human-annotated m-layer files, but also on the machine-annotated ones. Due to space reasons it was not possible to include machine-annotated m-layer files in the CD-ROM. Instead, a special tool for generating the data for parser development and evaluation is provided.
The tool resides in the directory tools/machine-annotation/for_parser_devel/. It is run by the command
run_for_parser_devel input_directory output_directory
The input directory has to have the same structure like data/full/, which typically be its first argument. The tool copies the whole directory structure of the input directory into the output directory. It also copies all the data files except for the m-layer ones, which are substituted with the newly generated m-layer files. The new m-files contain automatically assigned lemmas and tags. However, note that the new files are not equivalent to what would be obtained by machine annotation applied directly on a plain text, since the new files preserve the sentence and token boundaries as well as identifiers of m-layer units as contained in the manually annotated files.
Although the annotators have seen every node of every tree (often more than once), they have still made some errors. Some of them have been caused by an inadvertence of the annotators, other errors surfaced because the annotation rules evolved and changed during the annotation process, while the data were not re-annotated every time a rule changed. Therefore, a large set of programs (TrEd/btred/ntred macros, see Section 4.2, "Viewing (browsing) trees: TrEd") was developed during the annotation phase and during the checking phase, each macro searching the data for a violation of a rule, an invariant or a suspicious annotation, reporting the affected corpus positions. The data have then been manually or automatically repaired or the macro was changed if necessary.
Note: For help on writing macros for TrEd, see the documentation of TrEd.
The macros were divided into three groups: find, fix and check. Macros from the find group were just searching for all the suspicious data. Macros from the fix group were used where automatic reparation was possible, such as when an unambiguous, defined annotation rule change appeared in the middle of the annotation process. The last group (check) contained macros similar to those in the find group, but they included lists of exceptions to the general rules. (In fact, there was also another group called misc that contained miscellaneous macros and scripts.)
The macros were also divided into groups with respect to which layer of annotation they apply to (see Chapter 2, Layers of annotation for details on layers).
The macros from the check group are included in directory tools/checks. Warning: These macros are not intended to be used anymore because the format of the data has changed but one can browse them to get the taste of what kind of checks have been applied to PDT 2.0, and what macros can be programmed to deal with tree structures.