Table of Contents
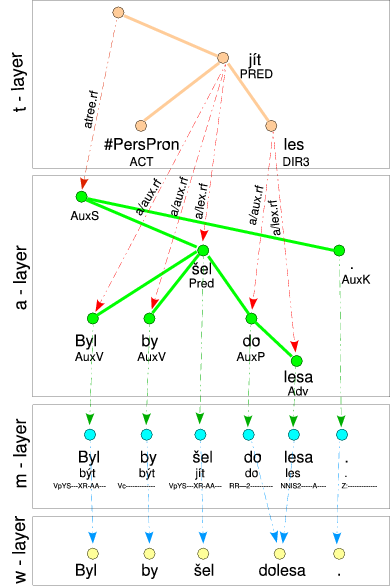
The data in PDT 2.0 are annotated on three layers-the morphological layer (Section 2.1, "Morphological layer"), analytical layer (Section 2.2, "Analytical layer"), and tectogrammatical layer (Section 2.3, "Tectogrammatical layer"). In fact, there is also one non-annotation layer, representing the "raw-text". On this layer, called word layer, the text is segmented into documents and paragraphs and individual tokens are recognized and associated with unique identifiers.
The word layer is also called the w-layer, the morphological one the m-layer, the analytical one the a-layer, and the tectogrammatical one the t-layer. Similarly, a node of a tree expressing analytical annotation of a sentence is called the a-node etc.
Figure 2.1, "Linking the layers" shows the relations between the neighboring layers as annotated and represented in the data. The rendered Czech sentence Byl by šel dolesa. (lit.: He-was would went toforest.) contains past conditional of the verb jít (to go) and a typo.
This section briefly describes the morphological layer. For more information see the Manual for Morphological Annotation.
At the morphological layer, the sequence of tokens of the w-layer is divided into sentences. Annotation of a sentence consists of attaching several attributes to the tokens of the w-layer, the most important of which are morphological lemma and tag.
Attribute lemma carries the lemma of the token. It represents its basic or normalized form, and it matches the unique key of the corresponding entry in the morphological dictionary. The tag attribute contains 15-character long morphological tag that expresses the part of speech of the token and its various morphological categories. The attribute id contains a PDT 2.0-unique identifier of the m-layer unit which is then used for back reference from the analytical layer (for the overall linking scheme, see Figure 2.1, "Linking the layers"), and the reference-type w.rf attribute refers back to the w-layer. Several other attributes handle possible (but rare) corrections and/or normalizations relative to the w-layer; the most important of them is the form attribute which contains the correct form of the text token (which might differ from the text token in case of spelling errors, incorrectly split or joined words, unsuitable representation of decimal points in numbers or of other technical problems with the original text).
See a sample sentence in Table 2.2, "Morphological analysis of the example sentence"
The morphological layer of PDT has been annotated by a group of seven annotators. The group proceeded in two separate phases. During the first phase-after each text had been processed by the automatic morphological analyzer-two annotators independently chose the lemma and the morphological tag from the list suggested by the morphological analyzer. In the second (adjudication) phase, an annotator-arbiter resolved the differences between them.
After the separate checking of the morphological and syntactical-analytical layers, a mutual revision was done. The comparison concentrated on the aspects of analytical functions vs. morphological tags, preposition vs. the case of depending node, and finally, the "case, gender, number" agreement between a dependent and its governing node.
This section briefly describes the analytical layer. For more information see the Annotations at Analytical Level.
A sentence at the analytical layer is represented as a rooted ordered tree with labeled nodes and edges. One token of the morphological layer (see Section 2.1, "Morphological layer") is represented by exactly one node of the tree and the dependency relation between two nodes is captured by an edge between the two nodes. The actual type of the relation is given as a function label of the edge. Most of the edges represent dependency relations, while others mirror various linguistic or technical phenomena, e.g. coordination, apposition, punctuation, etc. Linear ordering of the nodes, which corresponds to the original sentence word order, is also recorded, allowing "correct" graphical rendering of the tree.
A set of six attributes is attached to every node (except for the technical root of the tree that has less attributes). The attribute id contains a PDT 2.0-unique identifier of the node which is referred back (linked) from the tectogrammatical layer (see Figure 2.1, "Linking the layers"). The linear-order attribute ord contains the corresponding token position in the original sentence. For technical simplicity, the analytical function attribute afun belonging to an edge is moved to the dependent end of the edge and appears as a node attribute. The attributes is_member and is_parenthesis_root mark proper coordination, apposition and parenthesis interpretation. Finally, the attribute m.rf links the node to the corresponding morphological one.
See a sample tree in Figure 2.3, "The analytical tree of the example sentence"
All the analytical data have been annotated manually by a team of six annotators. At the beginning, the annotators had to build the whole tree and assign all the analytical functions, while in the later stages, sentences were pre-processed by a parser and a tree was proposed to the annotators. A rule-based function assigning analytical functions was available as well. Nevertheless, the annotators had to revise the output of both the procedures since the result of these procedures was often inacurate.
After the annotation process had finished, the data passed many checking tests. An example of such a test was verification of the assertion that the verbal nominal predicate (indicated by analytical function Pnom) must always have the verb být (to be) as its head. All the violations of these rules/tests were manually checked and corrected.
This section briefly describes the tectogrammatical layer. For more information see the Tectogrammatical Annotation of the PDT: Annotator's Guidelines.
The tectogrammatical representation of a sentence captures the following aspects:
-
Tectogrammatical structure and functors. Every sentence is represented as a rooted tree with labeled nodes and edges. The tree reflects the underlying (deep) structure of the sentence. The nodes stand for auto-semantic words only (with some exceptions of a technical nature). Unlike the analytical layer, not all the morphological tokens are represented at the tectogrammatical layer as nodes (for example, there are no prepositions on the tectogrammatical layer) and some of the tectogrammatical nodes do not correspond to any morphological token (for example, the structure contains a node representing omitted subject in pro-drop constructions). Grammatemes are attached to some nodes; they provide information about the node that cannot be derived from the structure, the functor and other attributes (for example number for nouns, modality and tense for verbs etc.). The edges of the tree represent relations between the nodes they connect; the type of the relation is indicated by the label of a particular edge (similarly to the analytical layer). Every node representing a verb or a certain type of a noun has a valency frame assigned to it (by means of a reference to a valency dictionary entry-see Section 3.8, "PDT-VALLEX").
-
Topic-focus articulation (TFA). Each node is assigned one of the three values assigned on the basis of contextual boundness: a node can be contextually bound, contrastively contextually bound, or contextually non-bound. In addition, the nodes in the topic part of the sentence are ordered according to the assumed communicative dynamism.
-
Coreference. At the current phase of annotation, coreference relations between nodes of certain category types are captured, distinguishing also the type of the relation (textual, grammatical, or the "second dependency" of complement).
The total of 39 attributes is assigned to every non-root node of the tectogrammatical tree; based on the node type (attribute nodetype), only a certain subset of the attributes is necessarily filled in. Often, the attributes are of a list or set type, containing more than one value.
-
Tectogrammatical structure and functors. Similarly to the analytical layer, a set of attributes is attached to every node; however, there are many more attributes at the tectogrammatical layer for the description of the linguistic structure than at the analytical one. The attribute
idcontains a unique identifier of the node, the attributefunctordescribes the type of the edge leading from the node to its governor (the edge may represent dependency relation or other technical phenomena). The attributet_lemmastands for the tectogrammatical lemma of the node. Grammatemes are rendered as a set of 16 attributes grouped by the "prefix"gram(e.g.gram/verbmodfor verbal modality). Attributes for back reference (linking) to the analytical layer are provided (see Figure 2.1, "Linking the layers"), as well as other attributes for coordination and apposition, parenthesis, direct speech, quotations, etc. -
Topic-focus articulation. Classification of nodes as contextually bound, contrastively contextually bound, or contextually non-bound is represented by the corresponding value of attribute
tfa. The numeric attributedeepordis used for the underlying ordering of nodes based on communicative dynamism. -
Coreference. Attributes
coref_text.rf,coref_gram.rf, andcompl.rfcontainids of coreferential nodes of the respective types. Attributecoref_specialcontains information about special cases of coreference.
See a sample tree in Figure 2.4, "The tectogrammatical tree of the example sentence (a detailed view)"
As the tectogrammatical structure is also based on the relation of dependency, automated procedures were used to convert dependency-based analytical trees to an intermediate tectogrammatical-like ones. All the generated intermediate trees were then processed by human annotators, who added a great amount of missing information and corrected the wrong one. Coreference, topic-focus articulation, and some of the grammatemes were annotated separately. All the data were then checked by many post-annotation tests (see Section 4.7, "Macros for error detection").
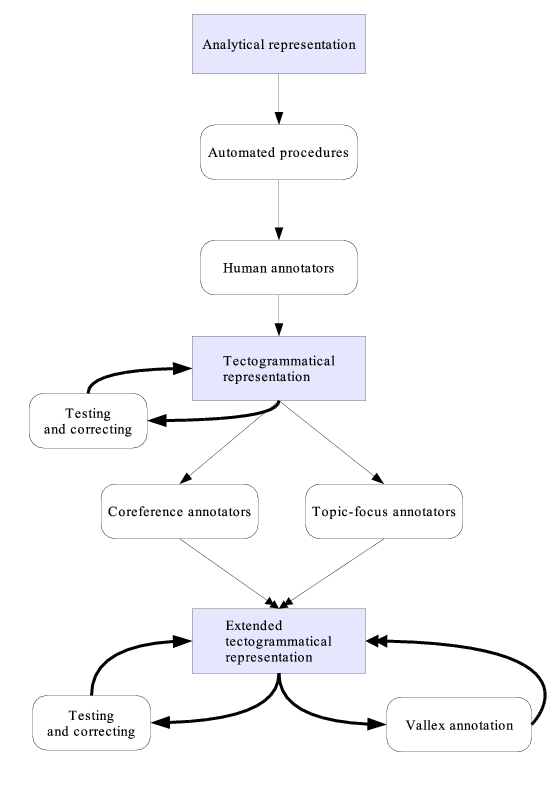
In Figure 2.2, "Data and annotation workflow diagram" the data and work flow diagram is shown. Thick arrows represent iterated operation, double arrows indicate merging procedures that were used when different sub-layers were being annotated on the same data at the same time.
Table 2.1. An example sentence
| Některé | kontury | problému | se | však | po | oživením | Havlovým | projevem | zdají | být | jasnější | . |
| Some | contours | problem (gen) | reflexive pronoun | though | after | resurgence (instr) | Havel's | speech (instr) | they-seem | to-be | clearer | . |
| Some contours of the problem seem to be clearer after the resurgence by Havel's speech. | ||||||||||||
An example sentence can bee seen in Table 2.1, "An example sentence".
The annotation of the sample sentence on the morphological layer can bee seen in Table 2.2, "Morphological analysis of the example sentence". Note that the instrumental form of oživení was changed to locative form. The reason (indicated in form_change element) is a spelling error.
Table 2.2. Morphological analysis of the example sentence
| Form | Lemma | Morphological tag |
|---|---|---|
| Některé | některý | PZFP1---------- |
| kontury | kontura | NNFP1-----A---- |
| problému | problém | NNIS2-----A---- |
| se | se_^(zvr._zájmeno/částice) | P7-X4---------- |
| však | však | J^------------- |
| po | po-1 | RR--6---------- |
| oživení | oživení_^(*3it) | NNNS6-----A---- |
| Havlovým | Havlův_;S_^(*3el) | AUIS7M--------- |
| projevem | projev | NNIS7-----A---- |
| zdají | zdát | VB-P---3P-AA--- |
| být | být | Vf--------A---- |
| jasnější | jasný | AAFP1----2A---- |
| . | . | Z:------------- |
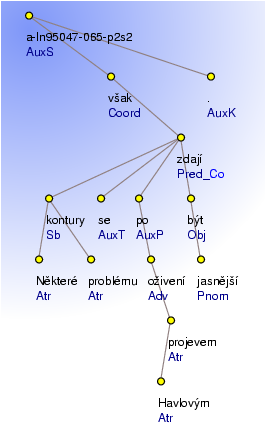
Annotation of the sample sentence on the analytical layer can be seen in Figure 2.3, "The analytical tree of the example sentence". Note that the word zdají is labeled as the only coordination member. This is how a coordination with the previous sentence has been annotated on analytical layer.
The annotation of the sample sentence on the tectogrammatical layer is in Figure 2.4, "The tectogrammatical tree of the example sentence (a detailed view)".
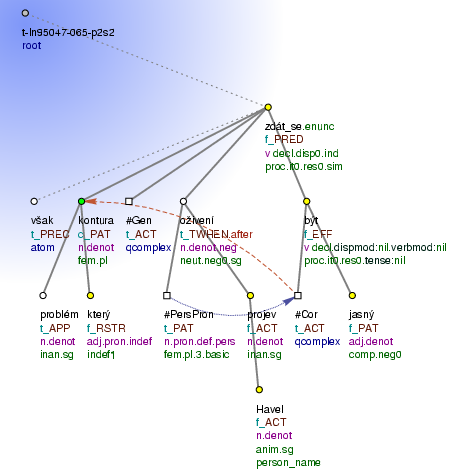
Note that the word však is no longer a coordination node. It was labeled by the functor PREC as a linking word to the previous sentence. Also note that the word se became part of the complex verb form zdát_se, that the preposition po disappeared (but it is referred to from the word oživení and it is the basis of the functor and sub-functor values of this word), that the pronoun některý has t_lemma který but its indefiniteness is expressed by the value of gram/sempos and gram/indeftype, etc.
For more examples, see Section 3.7, "Sample data".