Table of Contents
The tree editor tred allows for a quick and comfortable viewing of linguistic tree structures, but as soon as you need to handle a bigger piece of the PDT data at a time, tools allowing automatic processing become necessary. We recommend you to access the PDT data via btred/ntred Perl-based interface tailored for the PDT purposes. btred is a Perl program that allows the user to apply another Perl program (called btred macro) on the data stored in one of the PDT formats. ntred is a client-server version of btred and is suited for data processing on multiple machines in parallel (mnemonics for btred/ntred: "b" stands for "batch processing", "n" stands for "networked processing").
If you follow the above recommendation, you gain several advantages:
- Object-oriented tree representation, which is used in btred/ntred environment, offers a rich repertory of basic functions for tree traversing and for many other basic operations on trees; besides that, there are also several highly non-trivial functions available, suited for linguistically motivated traversing of trees (reflecting e.g. the interplay of dependency and coordination relations).
- btred/ntred technology was extensively used by several programmers during the development of the PDT; this long-time experience has led to many improvements and also helped to make the tools and accompanying libraries reasonably error-prone.
- If you have more computers at your disposal, you can use ntred and process the data in parallel, which makes the computation considerably faster. Depending on the situation, it may shorten the time needed for passing the whole PDT to just a few seconds.
- Programmers can use btred/ntred (in combination with TrEd) as a powerful and fast search engine—you write a macro which finds the treebank positions you are interested in, run it by ntred and then simply view the retrieved positions in TrEd.
- All you need to become fluent in writing btred/ntred macros is to know the basics of Perl syntax and to remember a few names of variables and subroutines predefined in the btred/ntred environment.
- Once you learn the btred/ntred style of work, you can re-use all its benefits when processing the data of other treebanks (be they dependency- or constituency-based).
The following text should serve as a short introduction to btred/ntred style of work with the PDT 2.0 data. More detailed information about the two commands is available in btred and ntred manual pages.
Note that some of the examples in this tutorial are specific to PDT 2.0 data only and need not be directly applicable to other data formats even if supported by TrEd.
The Perl code which you want to execute can be specified directly on the command line:
$ btred -e 'print "Hello world!\n"' data/sample/*.t.gz
In this example, btred loads all the specified files one-by-one and evaluates
the Perl code for each of them. In other words, it prints as many
"Hello world!" lines as there are data/sample/*.t.gz files.
In this way, you can process three types of PDT 2.0 data files:
*.m.gz, *.a.gz, and
*.t.gz.
It is not recommended to mix files from various layers at a time
(e.g. due to the fact that when processing a file from a certain
layer, btred loads the interlinked files from the lower layers by itself).
It is often the case that you want to perform an action not only for each file, but
repeatedly for each tree in each file, or even for each node of each tree in each
file. To avoid writing the iteration code yourself, you can use
-T and -N switches (iterate over
all trees and iterate over all nodes, respectively). Thus the command
$ btred -TNe 'print "Hello world!\n"' data/sample/*.t.gz | wc -l
prints the total number of all nodes in all trees in all processed files.
Naturally, command line evaluation is suited only for very simple
macros. Longer macros can be stored in
a separate macro file. The difference is that the macro file as a
whole is evaluated only once and you have to use the option
-e to determine which subroutine
should be executed in each iteration.
The iteration options (-T and
-N shown above) can be
optionally specified directly in the macro. Example macro file helloworld.btred:
#!btred -TN -e hello()
sub hello {
print "Hello world!\n"
}
The tectogrammatical nodes in the processed files can be then counted as follows (not very elegantly, though):
$ btred -I helloworld.btred data/sample/*.t.gz | wc -l
So far, we specified the files to be processed simply by using a file name mask
on the command line (data/sample/*.t.gz in the
above examples).
But when one works with the full data of PDT 2.0, it often happens
that the total length of command line arguments exceeds its limit.
In such a case, expansion of the wildcards can be "postponed" from
shell to btred:
$ btred -TNe 'print "Hello world!\n"' -g 'data/full/tamw/train*/*.t.gz'
Instead of specifying the files on the command line, you can first create a file containing the list of files to be processed (one per line), either by choosing a subset of the distributed full data file list (which, of course, contains only relative paths!):
$ grep 'tamw/train-[1-4].*a.gz' data/full/filelist > half-train-a.fl
or by other means, e.g. using find:
$ find data/full/*awm/train-[1-4]/ -name '*a.gz' > half-train-a.fl
and open the file list (instead of a single file) in btred by using -l:
$ btred -TNe 'print "Hello world!\n"' -l half-train-a.fl
(The file lists created by the above commands contain one half of all training a-files: train-1 to
train-4 from tawm and awm).
Until now, we only iteratively executed a blind code, without really touching the data. The trees and nodes can be accessed via special variables which are predefined in the btred environment. The most important ones are:
$this– current node, and$root– root of the current tree.
See Section 14.8. Public API: pre-defined macros in the TrEd User's Manual to see them all. Remember that these variables should not be re-declared in your code;
if you use the strict module in your code to restrict
unsafe constructions (including the usage of undeclared variables),
you have to introduce these variables by the following line:
use vars qw($this $root);
Nodes, represented as Perl objects, have attributes of several types (see the exhaustive list of attributes):
-
Values of simple attributes are obtained directly using
$node->{attr}syntax.Example:
my $current_functor = $this->{functor}; -
Values of structured attributes can be obtained in two almost equivalent notations:
$node->{level1attr}{level2attr}or$node->attr('level1attr/level2attr'). Example:my $semnoun_number = $this->{gram}{number};or
my $semnoun_number = $this->attr('gram/number');The slash with the
->attr()notation is slightly slower but also safer if a part of a non-defined structured attribute is accessed (which is the case e.g. of thenumbergrammateme, since it is present only in semantic nouns). -
In case of a list attribute, the array of its values can be obtained by calling
ListV($node->{listattrname}).Example: list of identifiers of tectogrammatical nodes which are antecedents (with respect to textual coreference) of the current node:
my @ids = ListV($this->attr('coref_text.rf');If it is guaranteed that the list is not empty, n-th value in the list can be accessed directly by an array index, such as in:
my $first_antec_lemma = PML_T::GetNodeByID($this->{'coref_text.rf'} ->[0])->{t_lemma};(Apostrophes or quotes around
coref_text.rfare necessary only because of the dot in the attribute name.)
Remember that there are different sets of attributes available on
different layers (as documented in the exhaustive list of
attributes). Example - for each node of each analytical tree
in the sample data, print its analytical function
(-q is used to surpress btred progress messages):
$ btred -TNqe 'print $this->{afun}."\n"' /net/projects/pdt/pdt20/data/sample/*.m.gz
Sample from the output:
AuxS Pred Sb Atr AuxP Adv Adv Obj
Note that when you access the m-layer attributes directly in the m-files, the attributes are embeded in a structure named '#content', as shown in the following example. The example prints the frequency list of forms of vocalized prepositions (according to their frequency in m-layer files in the sample data). The (sorted) frequency list is created by pipelining btred with standard shell commands:
$ btred -TNe 'print $this->attr("#content/form")."\n"\
if $this->attr("#content/tag")=~/^RV/' data/sample/*.m.gz | sort | uniq -c | sort -nr
Output:
25 ve
11 ze
8 se
2 Ve
1 ke
Nodes, as Perl objects, have attributes and methods.
The methods can be accessed using the
$node->method(arguments) syntax.
All the available methods are documented in Table FSNode
methods in the TrEd User's Manual.
The most important methods for traversing the tree are
parent() (returning the parent node) and
children() (returning the array of child nodes).
The following example combines both and prints lemmas of nodes the
parent of which is the technical root of the tree and which have
a directional modifier among its children:
btred -TNe 'print "$this->{t_lemma}\n" if
$this->parent==$root and grep{$_->{functor}=~/^DIR/} $this->children()' \
data/sample/*.t.gz -q
Besides the methods associated with the node objects, there are
many useful functions which take nodes as arguments
and which are implemented in PML macro files (see PML.mak documentation).
They are loaded into the btred/ntred environment by default
unless -m parameter is used (see the
btred manual page).
As for tree traversing, there are functions GetEParents($node) and
GetEChildren($node) (E standing for effective)
in PML_T (resp. PML_A) package. Although it often makes the code more
difficult, they should be used instead of $node->parent() and
$node->children()
in most situations because GetEParents and
GetEChildren correctly resolve the complex interplay
between dependency and coordination edges in the tectogrammatical
(resp. analytical) trees.
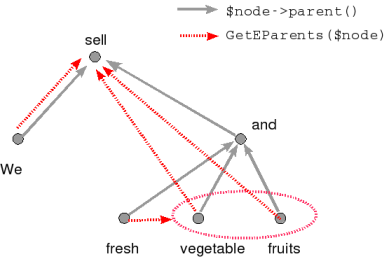
For instance, in the tree of the sentence We sell fresh vegetable and fruits, the
nodes corresponding to fresh,
vegetable
and fruits are all children (in the sense of children()) of and,
but the correct linguistic interpretation is
different: (1) fresh has two effective parents (the "true governors" in terms
of dependency relations, obtained by calling GetEParents()), namely vegetable
and fruits, and (2) the effective parent of vegetable
(and also of fruits) is sell. Obviously, the graph of dependency
relations is not a tree any more.
Figure 1. The difference between parents (in the sense of tree topology,
$node->parent()) and effective parents
(dependency governors, GetEParents($node))
illustrated on a simplified fragment of an analytical tree.
The following example uses the functions
GetEParents() and
GetEChildren() when printing sentences containing
a patient ("deep object") in plural dependent on a negated verb (be there any
coordination node in between or not):
#!btred -TNe pluralpat()
sub pluralpat() {
if ($this->attr('gram/number') eq "pl" and $this->{functor} eq "PAT"){
foreach my $eparent (PML_T::GetEParents($this)) {
if (grep {$_->{t_lemma} eq "#Neg"} PML_T::GetEChildren($eparent)) {
print "($this->{t_lemma}) ".PML_T::GetSentenceString($root)."\n";
}
}
}
}
Sample from the output:
(příjem) Jakmile se někde objevilo, že někdo nadměrně bohatne, už se kontrolovalo, kolik příjmů přiznával a zda nějaké nezatajuje. (předloha) Tyto předlohy totiž předsednictva SN a SL na program nezařadila. (Rom) Cedule s nápisem "Romy neobsluhujeme!" se o tomto víkendu objevila na jednom z bister v Praze na Smíchově. (procento) Provoz osobních automobilů ruší ve spánku 22 procent obyvatel, hluk nákladních vozidel budí 20 procent občanů a také sousedi nenechají spát 20 procent populace v České republice.
In many tasks it is necessary to work with information from more than one layer. When data files of a given layer are processed in btred, the content of associated files of all lower layers is easily accessible. Due to the different nature of the relation between the layers (see Figure 2, “Relations between neighboring layers in PDT 2.0 (Sample sentence: Byl by šel dolesa., lit. [He] would have gone intoforest.)”), there are different mechanisms for accessing the data on a lower layer:
- The relation between a-layer and m-layer is the simplest
one: there is a 1:1 relation between the units of m-layer
and a-layer. On the a-layer, attributes of the m-layer
are accessible in the same way as if they were joined in a single structured
attribute, named with the letter of the lower layer. Thus
the lemma and tag (in fact situated on the m-layer) can be obtained
from a-layer as
$this->attr('m/lemma')and$this->attr('m/tag'). -
Due to the possible occurrence of mistakes in the original
texts (especially superfluous or missing blanks between two
tokens), the correspondence between the units of m-layer and w-layer is
not that simple. The word forms on m-layer are corrected:
if two tokens were joined, then one m-layer unit refers to two
w-layer units; in the other case, when one token was split,
two (or more) m-layer units refer to the same w-layer unit.
On the m-layer, the list of the original tokens
can be accessed as
ListV($this->{'w'}). However, cases other than 1:1 are extremely rare, that is why it is mostly sufficient to access only the first token from the list:$this->attr('w/token'). The relations between the layers can be composed and w-layer attributes can be accessed directly from a-layer, e.g.$this->attr('m/w/token'). -
In general, the relation between the units of a-layer and t-layer is
again M:N
(including 0:N and M:0), but in this case it is not a result of errors
in the input text, but of a systematic, linguistically relevant correspondence.
There are three attributes capturing this relation:
atree.rf, which is present only in the technical root and refers to the corresponding root of the analytical tree, anda/lex.rfanda/aux.rf, which are present only in nodes different from the technical root.a/lex.rfrefers to an analytical node which is the source of the lexical meaning (or of its biggest part) of the tectogrammatical node (or is possibly empty in case of certain types of restored nodes).a/aux.rfcontains a list (possibly empty) of references to analytical nodes corresponding to functional words (such as prepositions, subordinating conjunctions, or auxiliary verbs), which are syntactically bound with the autosemantic word referred to ina/lex.rf. List of all analytical nodes corresponding to the given tectogrammatical node can be obtained by callingPML_T::GetANodes($this).
Figure 2. Relations between neighboring layers in PDT 2.0 (Sample sentence: Byl by šel dolesa., lit. [He] would have gone intoforest.)
![Relations between neighboring layers in PDT 2.0 (Sample sentence: Byl by šel dolesa., lit. [He] would have gone intoforest.)](pics/bn-layers.png)
Example: Print complex verbal forms (including reflexives) which express future tense and contain an auxiliary verb:
#!btred -TN -e complex_future_form()
sub complex_future_form {
if ($this->{gram}{tense} eq "post" and
grep {$_->{afun} eq "AuxV"} PML_T::GetANodes($this)) {
print join " ",
map {$_->attr('m/form')}
sort{$a->{ord}<=>$b->{ord}}
grep {$_->attr('m/tag')=~/^(V|P7)/}
PML_T::GetANodes($this);
print "\t sentence: ", PML_T::GetSentenceString($root), "\n\n";
}
}
Sample from the output:
bude vést sentence: Politickou sekci bude nadále vést britský Major John, historickou trojnásobný Major z Hellerovy hlavy, zdravotnickou major Hoollighanová, policejní major Zeman. bude umístěna sentence: Jiří Ševčík se stal ředitelem sbírky moderního umění Národní galerie, která bude umístěna ve Veletržním paláci, jehož rekonstrukce se však už roky vleče. se budete zabývat sentence: Čím zejména se budete nyní zabývat?
Example: Print sentences containing a possessive pronoun present in the surface shape of the sentence, the textual antecedent (at least one of them, if there are more) of which is expressed as a prepositional group and is present in the same sentence:
#!btred -TN -e antec_pg()
use strict;
use vars qw ($root $this);
sub antec_pg() {
if ($this->{t_lemma} eq '#PersPron' and $this->attr('a/lex.rf')){
my $mainanode=PML_T::GetANodeByID($this->attr('a/lex.rf'));
if ($mainanode->attr('m/tag')=~/^PS/) {
my @antecedents = map {PML_T::GetNodeByID($_)}
ListV($this->{'coref_text.rf'});
my @candidates =
grep {$_->root() == $root}
grep { my $antec=$_;
grep{$_->attr('m/tag')=~/^R/} map {PML_T::GetANodeByID($_)}
ListV($antec->attr('a/aux.rf'))
} @antecedents;
if (@candidates) { print PML_T::GetSentenceString($root),"\n\n" }
}
}
}
Note that information from m-layer (detecting posessive pronoun) and t-layer (detecting textual coreference) is utilized in this example, whereas a-layer units serve here only for connecting t-layer and m-layer units. Sample from the output:
Izrael žádá od palestinské policie, aby zasáhla proti palestinským teroristům, a soudí, že autonomní Jericho se proměnilo v jejich útočiště. V případě rodinného domu lze získat úvěr v rozmezí 100 tisíc až pět miliónů korun také na jeho opravy a rekonstrukci.
There is a special set of subroutines, called hooks, that have
pre-defined names and are executed on certain occasions (see Section
14.9. Hooks: automatically executed macros in the TrEd User's Manual for detailed
information).
For instance, file_opened_hook() hook is executed
for each file before starting the iterations over its content.
If the user (re)defines some of these hooks, his/her new code
is invoked on the given occasion.
Example: the following macro file prints five most frequent functors for each of the processed files:
#!btred -TNe count()
my %cnt;
sub file_opened_hook { %cnt=() }
sub file_close_hook {
my @sorted = sort{$cnt{$b}<=>$cnt{$a}} keys %cnt;
my $filename=FileName();
$filename=~s/.*\///;
print "Five most frequent functors in ",$filename,
": ",join(" ",@sorted[0..4]),"\n";
}
sub count{ $cnt{$this->{functor}}++ unless $this eq $root}
Sample from the output:
Five most frequent functors in sample0.t.gz: RSTR PAT ACT PRED APP Five most frequent functors in sample1.t.gz: RSTR ACT PAT PRED APP Five most frequent functors in sample2.t.gz: RSTR ACT PAT PRED APP Five most frequent functors in sample3.t.gz: RSTR ACT PAT PRED CONJ Five most frequent functors in sample4.t.gz: RSTR ACT PAT PRED LOC
Note that if you need to perform a certain action only once (for instance, loading an external file with a list of searched words), you do not have to use hooks, as it suffices to put this initiation code simply outside the subroutines.
Executing a btred macro on a large amount of data may take a very long
time (even tens of minutes for the whole PDT 2.0). There is a simple
solution how this time can be significantly reduced: change the
format of the data files from PML to
Perl Storable Format (pls.gz).
You can convert the data files in the following way (see the
section about format conversions in the PDT Guide):
$ btred -Y -m pml2pls.btred -g '*.t' '*.a'
or (if you already use ntred described in the next section):
$ ntred -i -Y -g '*.t' '*.a' $ ntred -m pml2pls.btred $ ntred --save-files
And how can the sole change of data format cause a significant acceleration?
When working with PML, which is the XML-based primary format of PDT 2.0,
btred always has to build its internal data representation from the
original XML. Because Perl hashes are massively used in the internal
representation, the transformation is time-consuming . This transformation
is completely avoided when working with pls.gz because
btred stores (and reads) directly its internal data representation
into (from) the data file.
The users of the CD PDT 2.0 are already provided with the full data
from data/full/amw and
data/full/tamw
converted into the pls.gz format. The converted
files are located in the directories
data/binary/amw
and data/binary/tamw on the CD. Both of these directories
are further structured in the same way as those
in data/full, but note that for each file the three annotations
originally distributed in separate files representing the w-layer,
m-layer, and a-layer of annotation are now knit into a single *.a.pls.gz file.
Even if you use pls.gz data format as suggested above,
most of the time needed for running your macro is not spent on
performing your code, but by opening and parsing the data files.
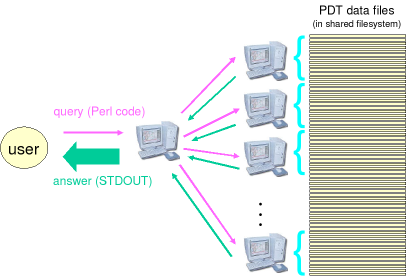
In such a situation, you can use ntred ("networked btred", see
ntred manual page for details) which offers you
a big speed-up, because it (1) processes the data in parallel and
thus can utilize computing power of
more machines, (2) reads the files only once and keeps them in
memory. As a result, it may shorten the time
needed for processing the whole PDT 2.0 to just a few seconds.
Even if you have only a single machine, you can reach a speed-up in
the order of magnitude due to (2). The client-server architecture
of the ntred system is sketched in Figure 3, “Parallel processing of the PDT 2.0 data in the ntred system.”.
The hostnames of the machines (and port numbers) which you want to employ should be listed in
.ntred_serverlist file in you home directory.
You may choose any port number above 1024, but you should try to avoid
collisions with other services running on the remote machines
(including ntreds of other users: all users potentially working on the same machines should have
mutually disjoint sets of hostname-port pairs in their .ntred_serverlist).
You may specify one hostname several times (using different ports!), which is is particularly useful to
utilize the whole power of multi-processor systems.
Example:
# two remote single-processor machines: computer1:2500 computer2:2500 # one remote dual-processor machine: computer3:2500 computer3:2501
Empty lines in .ntred_serverlist are ignored, and lines starting with a hash sign # are treated as comments.
The machines must have shared filesystem (as a minimum, they should
share your home directory and a directory containing your data).
You need to have password-free access to them, e.g. using Kerberos,
.rhosts files or ssh2
authorization keys together with a ssh-agent2.
If the above requirements are fulfilled, you can initiate the ntred system with files you want to process, e.g.:
$ ntred -i -l half-train-a.fl
You can see the ntred hub (usually running on your local computer) distributing your data among the ntred servers (in fact btred instances running on the remote computers). As soon as all data files are distributed and the system is ready, the following message is printed:
NTRED-HUB: Waiting for a new client request.
Now you can start (preferably in a new terminal) running your macro in parallel using the ntred client. The way it is executed from the command line is very similar to that of btred (of course, with the difference that you do not have to specify the files to be processed, as they have been already loaded on the servers). Example:
$ ntred -I helloworld.btred
The hub merges STDOUT (and also STDERR) outputs of the individual ntred servers and prints the result on the STDOUT (resp. STDERR); note that the STDOUT outputs are only joined, not mixed.
Usually you can use your btred macros also for ntred without changing the code. However, remeber that each server processes its own data without communicating with the others: if your macro for instance prints some overall statistics, you get as many results as there are servers, and have to post-process them in order to obtain the global result.
When your work with ntred servers is finished, you can close the
session by running ntred --quit.
If the servers hang (e.g. because of an accidental infinite loop in
your macro), you usually don't have to restart the session: instead, you
can try to "revive" the session by calling
ntred --break. When debugging
your code, it may sometimes be useful to peek into ntred server log
files, located in
/tmp/ntred-server-.
As a last resort, e.g when the ntred hub crashes, you may remove the
surviving relicts of the last session with host-port.logntred
--kill.
Supposing ntred is running in your system, you can comfortably search through the treebank by printing the treebank positions for which your query conditions hold, e.g.:
$ ntred -TNe 'NPosition($this) if $this->{functor}=~/^T(SIN|TIL)/' \
> positions.lst
and browse the detected positions in tred (as depicted in Figure 4, “Browsing the query result in tred.”):
$ tred -l positions.lst
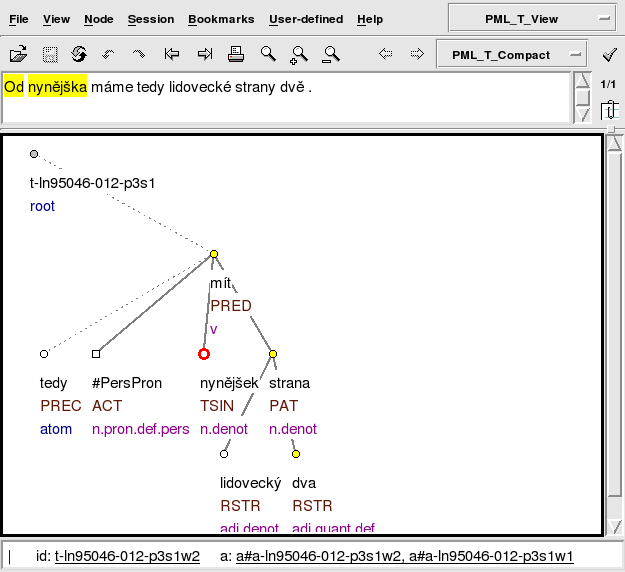
When browsing the list of positions in tred, the nodes corresponding to
the detected positions are focused (i.e., visually
distinguished from the other nodes in the tree). The list of positions can be passed through
using the left pair of arrow buttons
or keyboard shortcuts (Shift+F11, Shift+F12, Alt+Shift+g).
The file positions.lst used in the above example
now contains the list of ntred node addresses (saying which node, in which,
tree in which file matches the query) in a url-like format, e.g.:
ntred:///net/projects/pdt/work/TR/pml2pls/ln94207_135.t.pls.gz@6##1.8 ntred:///net/projects/pdt/work/TR/pml2pls/ln94206_141.t.pls.gz@7##1.17 ntred:///net/projects/pdt/work/TR/pml2pls/cmpr9413_041.t.pls.gz@2##1.16
Again, more complicated queries can be stored in a macro file.
The following macro file (coord_rc.btred)
searches relative pronouns which are "shared" by at least three
coordinated relative clauses in tectogrammatical trees:
#!btred -TN -e coord_rel_clauses()
use strict;
use vars qw($this $root);
sub coord_rel_clauses {
if ($this->attr('gram/sempos') eq 'n.pron.indef' and
$this->attr('gram/indeftype') eq 'relat') {
my @eparents = PML_T::GetEParents($this);
my @clauseheads;
while (@eparents) { # iterative climbing "up" to the clause heads
@eparents = map {PML_T::GetEParents($_)}
grep {$_ ne $root and not ($_->attr('gram/tense')=~/(ant|sim|post)/ and
do{push @clauseheads,$_})} @eparents
}
NPosition() if @clauseheads>2
}
}
Now you can print the list of positions into a file, or you can feed tred directly with the output of your query:
$ ntred -I coord_rc.btred | tred -l -
In this way, tred receives from ntred only the trees containing
the detected positions, but not e.g. the trees of the neighbouring
sentences. If you need to have an access to the sentential context
too, use FPosition() instead of
NPosition() to print a file list instead
of a list of ntred URLs. When opening the file list in tred,
always the whole file is loaded and not just one tree (but still,
the detected node is focused). Sample of
FPosition() addresses:
/net/projects/pdt/work/TR/pml2pls/ln94207_135.t.pls.gz##6.8 /net/projects/pdt/work/TR/pml2pls/ln94206_141.t.pls.gz##7.17 /net/projects/pdt/work/TR/pml2pls/cmpr9413_041.t.pls.gz##2.16