Institute of Formal and Applied Linguistics
Charles University, Czech Republic
Faculty of Mathematics and Physics
OmniOMR
An applied research project of the 2023-2030 NAKI III programme, supported by the Ministry of Culture of the Czech Republic (DH23P03OVV008).
Music, preserved through music notation, is undoubtedly a major component of Czech national identity and heritage, and while the digitization of these materials is ongoing, music notation is not processed in any way other than bibliographically in Czech libraries. The Moravian Library is the first Czech library to start transcribing the incipits (first few bars or notes) during catalogization of musical manuscripts and early prints, but existing library information systems do not support any further processing of musical information, and the musical incipit is insufficient for making the body of digitized music notation searchable. During the digitalization of music notation, only the scanned image is stored (at most, text on the page is processed with OCR). If there is music notation in a book or other unit that is not marked as a musical item, such music is not identified at all. Thus, at present, there is no way to search the music in the collections, in the manner enabled by OCR in text documents. Furthermore, there is no way to search for music (notation) in mixed media, such as periodicals.
The goal of the project is to automatically document, index, and make accessible musical cultural heritage recorded by means of music notation in Czech digital library collections. This goal requires implementing two interconnected functionalities for Czech digital library systems:
1) Search for musical notation,
2) Search in musical notation, and using musical notation.
This functionality requires automatically:
- detecting regions containing music notation in digitized documents, and classify them according to notation type;
- from the detected regions, extracting musical semantics (pitches, durations and onsets of encoded tones);
- indexing the results in a database and implementing user-friendly flexible search in notation data;
and that these capabilities are deployed and made accessible in user interfaces, which are the technological goals of the project.
News
2025-11-18. The Makarius software, which provides a user interface to the content-based music document retrieval capabilities we are developing, has finished implementing the retrieval techniques and all its major features (such as a way of using it directly from the Kramerius interface -- or from any other digital library UI). It is now ready for "live" data. This is some great work from the Moravian Library team and their amazing contractors from Trinera, s.r.o.
Before we can really show you what Makarius can do, however, we need to focus on improving the actual recognition systems that feed data to it. That will be the main focus of our work for 2026.
2025-11-11. We have achieved a major technological milestone: our detector of music notation has achieved (and surpassed) target performance indicators. We thus have the technical capability to achieve the first overall goal of the project: music discovery in very large collections.
There were 4.000.000 input pages that we experimented with, out of which approx. 1.500 in fact contain music. We ran the experiment in two stages: a small pre-filter (an EfficientNet fine-tuned on a small older graphic detection dataset that fortunately had music notation as a class) that classified approx. 100.000 pages out of this as positive, and then a second, YOLOv11 fine-tuned stage trained on binary manual annotations of these 100.000 pages, which achieved a false positive rate of 0.57 %. Because these models are in fact used in series (the pre-filter on the Moravian Library servers, the more accurate but GPU-based YOLO classifier on the Matfyz side), we turn a ratio of music to not-music from 1:2500 in the Moravian Library collection to almost 3:1 in the positively classified results. (The false negative rate of the combined pipeline is estimated to be 4.6 %: estimated 2.5 % on the pre-filter via random re-training, <2 % on the "clean" downstream classifier.)
Based on these experiments, we believe there are approx. 25.000 pages in the collections of the Moravian Library that contain music but are not marked as such. A considerable chunk of musical life is in fact documented without anyone being aware of it -- but of course we have to actually process the 70.000.000+ pages in the digital collections of the Moravian Library to discover all this music.
(On top of this, we have a 96,8 % accuracy in then classifying what kind of music notation we are dealing with.)
This is thanks to the work of the entire team: not just the machine learning researchers, but also the data annotation team and their technical support. However, we feel we should highlight the contributions of Filip Jebavý, who made the pre-filter and experiments on the Moravian Library side happen, and then especially the excellent work of Vojtěch Dvořák, from the Matfyz part of the team, who tirelessly experimented with data cleaning, preprocessing, and under/oversampling to achieve the necessary performances on this extremely imbalanced input.

Vojtěch Dvořák presenting the detection results at the PMCG Research Meeting, 2025-11-14.
2025-08-18. And a joint paper with the OMR team from CVC UAB (Barcelona) got accepted to the CMMR conference in London. Congratulations!
2025-06-25. Two OMR-related papers accepted to the DLfM conference in Seoul, Korea! Congratulations above all to Jiří Mayer. (The papers are not really OmniOMR
2024-31-12. As the new year rolls in, we have released the SMASHCIMA tool on LINDAT! Check out also the demo.
![]()
2024-11-11. We have hit the 100-page mark in the OmniOMR dataset and surpassed MUSCIMA++ in symbol count. Currently the OmniOMR dataset has 101117 labels and 112942 relationships. Looking forward to continued collaboration with the team of Alicia Fornés of CVC UAB on making our datasets compatible.
2024-11-08. The SMASHCIMA tool for synthesizing handwritten music notation is close to release. This is what its outputs look like now, with only a MusicXML file as input:

2024-11-03. A paper on the development of the notation detector DEMUN has been accepted to the 6th WoRMS (this time online). Congratulations to Vojtěch Dvořák, a PMCG student who made very significant contributions to this work.
2024-10-19. First experimental results on the 2024 part of the OmniOMR dataset reached 0.98 f-score with IoU threshold 0.5. This is what an example notehead detection result looks like:

2024-10-01. And congratulations to Jiří Mayer again, this time for starting a 2-month research stay at the PRAIG group of the University of Alicante, under the mentorship of Jorge Calvo-Zaragoza. Here he is randomly photographed talking to Juan Carlos Martínez Sevilla, a colleague who traveled from Alicante to visit us in Prague in April.

2024-09-06. Congratulations to Jiří Mayer on presenting the work he led on end-to-end pianoform OMR directly with MusicXML at the ICDAR conference in Athens, Greece!
2024-06-20. Our annotation team has completed the annotation of over 70 pages with Music Notation Graphs (MuNG), amounting to over 60000 symbols. We're on track to surpass MUSCIMA++ this year, even though the going is slower than we would like. Here is an example of what MuNG annotations look like:
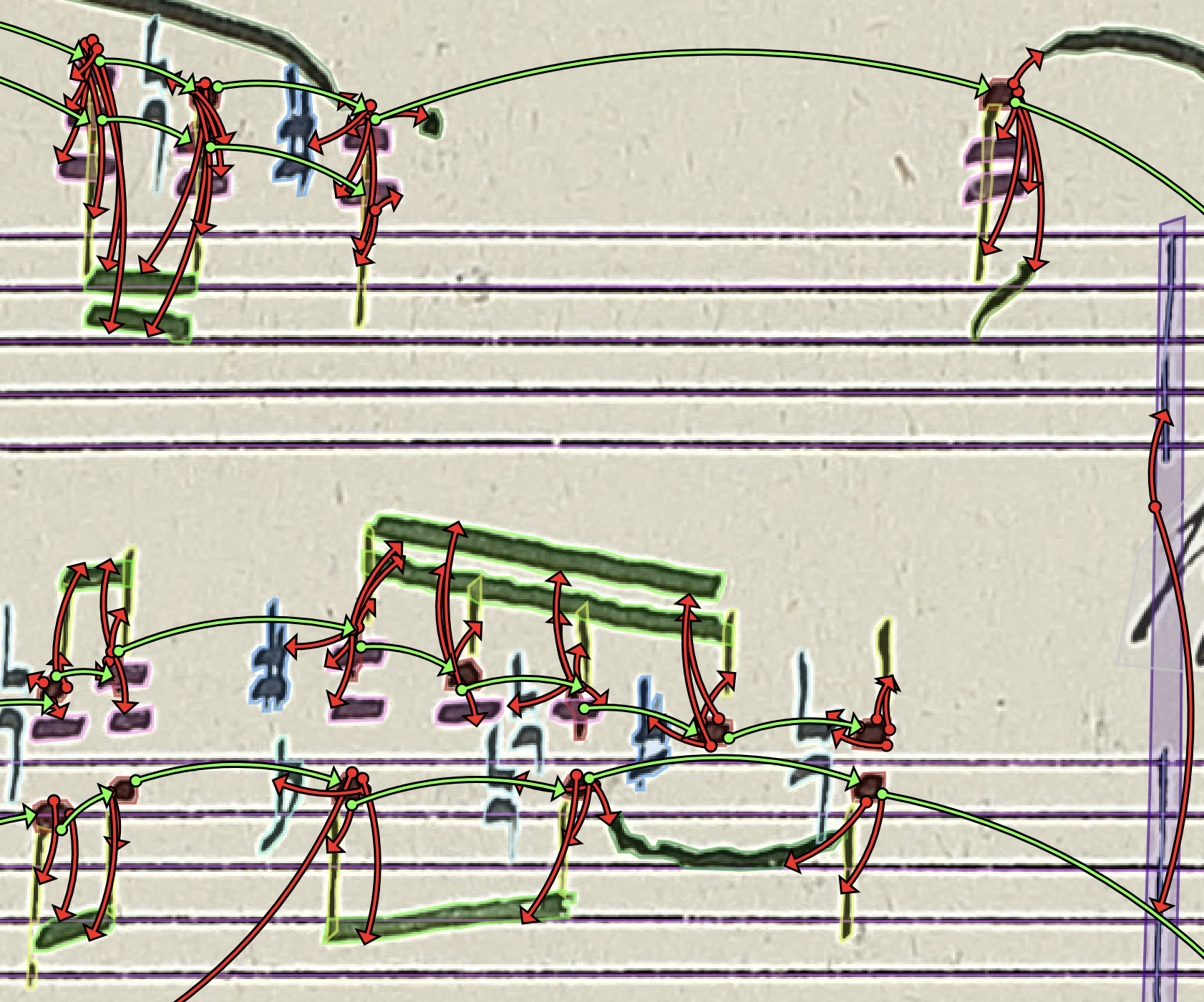
2024-04-22. The work led by our PhD student Jiří Mayer on end-to-end recognition of pianoform notation with linearized MusicXML, with some extra deep deep learning expertise brought by Milan Straka, has been accepted to ICDAR 2024 conference! Congratulations! We now have -- for the time being, at least -- state-of-the-art results on end-to-end recognition of pianofom notation.
2024-04-19. We had some visitors: Jorge Calvo-Zaragoza, Antonio Ríos Vila, and Juan Carlos Martínez Sevilla from the PRAIG group of the University of Alicante. We talked about collaborations, especially with respect to synthetic data. Antonio and Juan Carlos also presented their work at the first PMCG Day, as well as our PhD students Jiří Mayer and Adam Štefunko.

2023-11-15. The first Interim report has been submitted! While we didn't hit our stretch goals in data acquisition because we had to re-think our annotation infrastructure, the project is on track. Thankfully, we didn't have to make any changes to the project.
2023-11-04. Two extended abstract from OmniOMR presented at the 5th WoRMS in Milan! Congratulations especially to our student Jonáš Havelka, whose work on autoencoders for music notation symbol generation, under the supervision of Jiří Mayer, made an impression. Thanks to our presence at WoRMS, we found potential international partners for collaboration i.a. on thesis supervision and data acquisition.
2023-06-11 The OmniOMR demo API is available at https://quest.ms.mff.cuni.cz/mashcima/omniomr/api/.
2023-05-29 We are running a user study to determine UX priorities for the music search interface. If you are interested, contact Martina Dvořáková from the Moravian State Library (Martina.Dvorakova@mzk.cz).