Institute of Formal and Applied Linguistics
Charles University, Czech Republic
Faculty of Mathematics and Physics
MMIC
Description
MMIC is a set of command line tools implementing Mercer's maximum mutual information-based clustering technique. Main clustering program comes with subsidiary tools for class-based text transformations and result visualization. Together these form useful gadget for language modeling, study of semantic classes, or even analysis of authors' specific associations. The package contains program computing classification tree (growing it in an eager way from leafs (that is words) to its root), program for cutting this tree at a given level so we could obtain predetermined number of word classes and finally there is a visualizer/transformer drawing trees (ASCII-art based) and using classes to transform input text into a text where each word would be annotated with its class for example (the output format is quite configurable).
Requirements
Linux based computer with gcc-2.95.3. Works on 32 bit as well as 64 bit machines. Note that 32bit machines may become short of memory on longer text, if you specify too many words to be classified. Developed on little endian computer, big endinas were not tested so far (problems are expected, but I plan to verify-and-fix the program for endianess soon).
Sources
Current version is 1.0. Sources, including documentation and some explanation of the theory are here mmi_clustering-1.0.tbz .
Acknowledgments
This work was supported by the Czech Grant Agency under Contract 201/05/H014 and from the Grant Agency of the Academy of Sciences project No. 1ET201120505, except for files inc.h, nothreads.h, osbase.cc and os.cc, which are my libraries for convenient work with unix/libc in C. These existed long before I started to work on MMI_clustering.
References
R.L. Mercer et al., ``Class-based n-gram Models of Natural Language'', Computational Linguistics, vol. 18, no.4 pp. 487--80, December 1992.
F. Jelínek, ``Statistical Methods for Speech Recognition'', The MIT Press 1997.
J. Hajič, ``Introduction to Natural Language Processing (600.465) -- Mutual Information and Word Classes'' -- online course
D. Klusáček, ``Maximum Mutual Information and Word Classes.'' In WDS'06 Proceedings of Contributed Papers. MFF UK, Trója, Prague: Matfyzpress, Charles University, 2006, pp. 185-190.
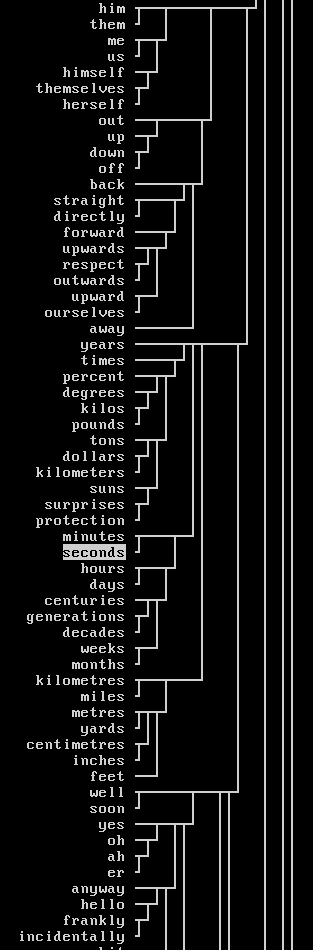
Gallery
The following screenshots show parts of visualized tree made from A.C.Clarke novels. The text was about 1M words long and was made by concatenating of all the Space Odysseys, Rama's Gardens, and several other stories. It had about 26K words in its vocabulary and 270K unique bigrams. 3780 most common words were subject to clustering. Processing took less than 6 minutes on 5 year-old 1.5GHz Athlon with 1GB RAM (clustering actually only required 50MB of it).