Lindat KonText
The PARSEME shared task data is a collection of corpora in 18 languages with annotation of verbal multiword expressions (VMWEs) in running texts. VMWEs include idioms (ID, let the cat out of the bag), light verb constructions (LVC, make a decision), verb-particle constructions (VPC, give up), and inherently reflexive verbs (IReflV, se suicider 'to suicide' in French; freuen sich `to be glad' in German), and other phenomena (OTH). For most languages, parts of speech, lemmas, morphological features and/or syntactic dependencies are also provided.
Parseme MWE 1.0 data is available from the Lindat repository, and can be searched through both KonText and NoSke. Detailed information about the annotations can be found at the project documentation page; on this page, we document the way the data has been converted for KonText/NoSke and some of the possibilities how it can be queried.
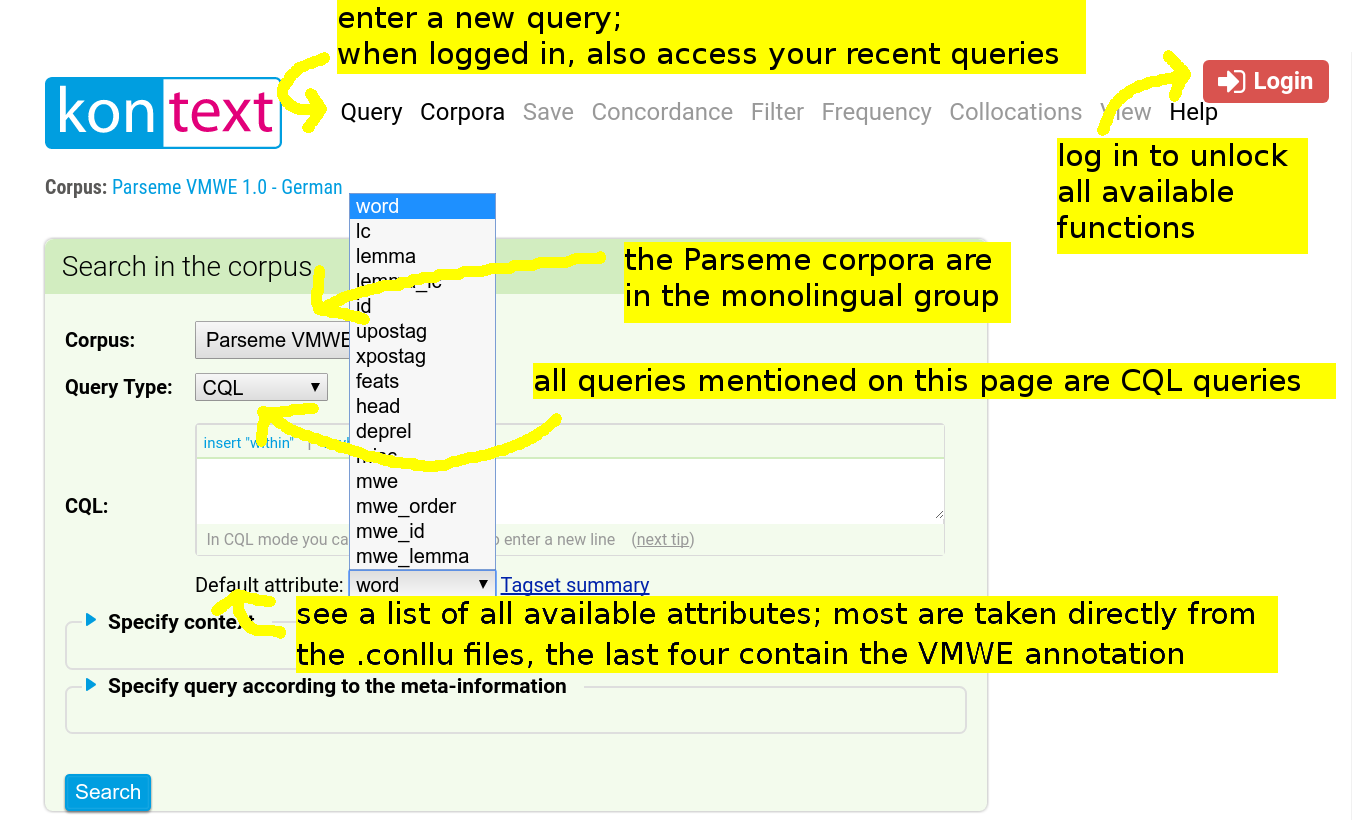
Attributes
The data contains the following attributes:
| word | the surface form of the token |
| lc | surface form, lowercased |
| lemma | the lemma |
| lemma_lc | lemma, lowercased |
| id | numerical id of the token, unique within sentence |
| upostag and xpostag | part of speech |
| feats | morphological features |
| head | id of the syntactic head of the token (possibly multivalue in case of a multi-word token) |
| deprel | the dependency relation binding the token to its syntactic head |
| misc | any other annotation |
| mwe | the type of MWE (ID,LVC,VPC,IReflV,ID, or OTH) or _ if the token is not part of an MWE |
| mwe_order | first for the first token in an MWE, cont for all remaining tokens |
| mwe_order_new | first for the first token in an MWE, last for the last token, cont for any MWE tokens in between |
| mwe_id | a numerical value identifying all tokens belonging to the same MWE, unique within a sentence |
| mwe_lemma | a concatenation of the lemmas of the tokens belonging to an MWE in the order in which they appear in the sentence |
Note that although the names of the attributes are the same as in the Universal Dependencies, some corpora do not use the UD tagsets. All of the attributes except for word and lc may take multiple values: feats is multi-value by design, lemma, id, upostag, xpostag, head and deprel take multiple values only in case of a multi-word token such as the Spanish del = de+el, and the MWE attributes take multiple values in case that the token is simultaneously part of multiple MWEs. Queries for overlapping MWEs demonstrate some possible uses of multivalue attributes.
Sample queries
Here we list a collection of queries that demonstrate some of the abilities of the CQL query type, which is the most expressive query type available in Kontext. We concentrate on the annotation of multiword expressions (MWEs). We link directly to ready-made queries in three common European languages, but the same queries are valid for all 15 languages that can be searched through KonText.
3 languages, Bulgarian, Hebrew and Lithuanian, were not included because the Parseme data does not contain any morpho-syntactic annotation; they may be added upon request.
| Simplest queries | |||
[mwe_order="first"] |
French | German | Spanish |
|
Search for the first word of each MWE annotated in the corpus. If the same word happens to be the first word of several MWEs, it will appear in the KWIC output only once. |
|||
[mwe="LVC"] |
French | German | Spanish |
|
Find tokens annotated as part of a light verb construction (LVC). |
|||
[lemma="faire" & mwe!="_"] |
French | German | Spanish |
|
Find a particular verb annotated with any category of VMWE. |
|||
[mwe_lemma="faire partie"] |
French | German | Spanish |
|
Search by a concatenation of the lemmas of words belonging to the MWE (in the order in which they appear in the text). |
|||
[mwe="LVC" & upostag="VERB"] |
French | German | Spanish |
|
Display LVC tokens that are verbs. |
|||
| Highlighting multiple words | |||
[mwe_order="first"][mwe_order="cont"]{1,} |
French | German | Spanish |
|
Display and highlight continuous MWEs (with no intermediate words between their tokens). The output may possibly contain a discontinuous MWE of three or more words such that the first two directly follow each other. Only the beginning continuous part will be highlighted. Also note than in case of a continuous MWE with three or more words, the KWIC contains multiple lines—one with the first two tokens highlighted, another one with three tokens highlighted. If you need to filter the output to contain only one instance in such cases (with the maximum possible number of words highlighted), please use the instance of the data running in NoSke and use the "Filter > Sub-hits" option. |
|||
1:[mwe_order_new="first"] [mwe_order_new="cont"]* 2:[mwe_order_new="last"] & 1.mwe_id=2.mwe_id within <s/> |
French | German | Spanish |
|
Matches whole continuous MWEs if they contain at least two words. |
|||
1:[mwe_order_new="first"] []* 2:[mwe_order_new="last"] & 1.mwe_id=2.mwe_id within <s/> |
French | German | Spanish |
|
Matches the first and last words of the MWE together with any words lying between them. |
|||
1:[mwe_order="first"] []* 2:[mwe_order="cont"] []* 3:[mwe_order="cont"] & 1.mwe_id=2.mwe_id & 1.mwe_id=3.mwe_id within <s/> |
French | German | Spanish |
|
Highlight three tokens in an MWE, including any discontinuities between them. |
|||
| Queries for overlapping MWEs | |||
[mwe=".*;.*"] |
French | German | Spanish |
|
Find tokens that are part of more than one MWE. |
|||
[mwe="(.*);\1"] |
French | German | |
|
Find tokens that are part of two or more MWEs of the same type; this could be a result of coordination such as in they were going in and out. The Spanish data does not contain any such nodes. |
|||
[mwe="ID" & mwe="LVC"] |
French | German | Spanish |
|
Find words which are simultaneously part of an idiom (ID) and a light-verb construction (LVC). Formulating the query as |
|||
| Various | |||
1:[mwe_order="first" & upostag="VERB" & mwe="LVC"] []* 2:[mwe_order="cont" & upostag="NOUN"] & 1.mwe_id=2.mwe_id within <s/> |
French | German | Spanish |
|
Find light verb constructions where the real syntactic head goes first. |
|||
| Queries that DO NOT WORK | |||
We apologize that we have previously suggested using the following two queries. Queries mixing the meet operator and global conditions with named tokens (those marked with 1:, 2: etc.) should in fact be avoided. The reason is that (meet 1:[] 2:[] min max) is evaluated first; for each token 1 such that the corresponding token 2 exists, only one such pair is propagated to the evaluation of the global condition (e.g. & 1.mwe_id=2.mwe_id) — if several pairs satisfying the conditions specified inside meet exist, there is no guarrantee that exactly the pair that additionally satisfies the global condition will be propagated and not some other pair (that is then pruned when the global condition is applied). A more detailed discussion of this issue and some examples of the unintuitive results it leads to can be found at #164. |
|||
(meet 1:[mwe_order="first"] 2:[mwe_order="cont"] 0 5) & 1.mwe_id=2.mwe_id within <s/> |
French | German | Spanish |
|
|
|||
(meet 1:[mwe_id="(.*;.*)"] 2:[] 1 5) & 1.mwe_id=2.mwe_id within <s/> |
French | German | Spanish |
|
|
|||
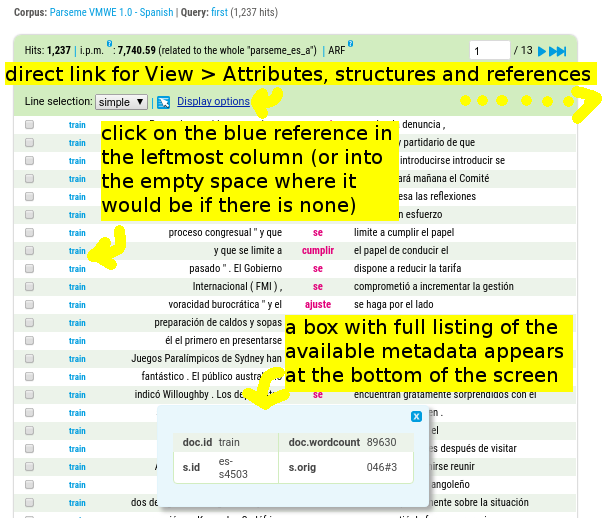
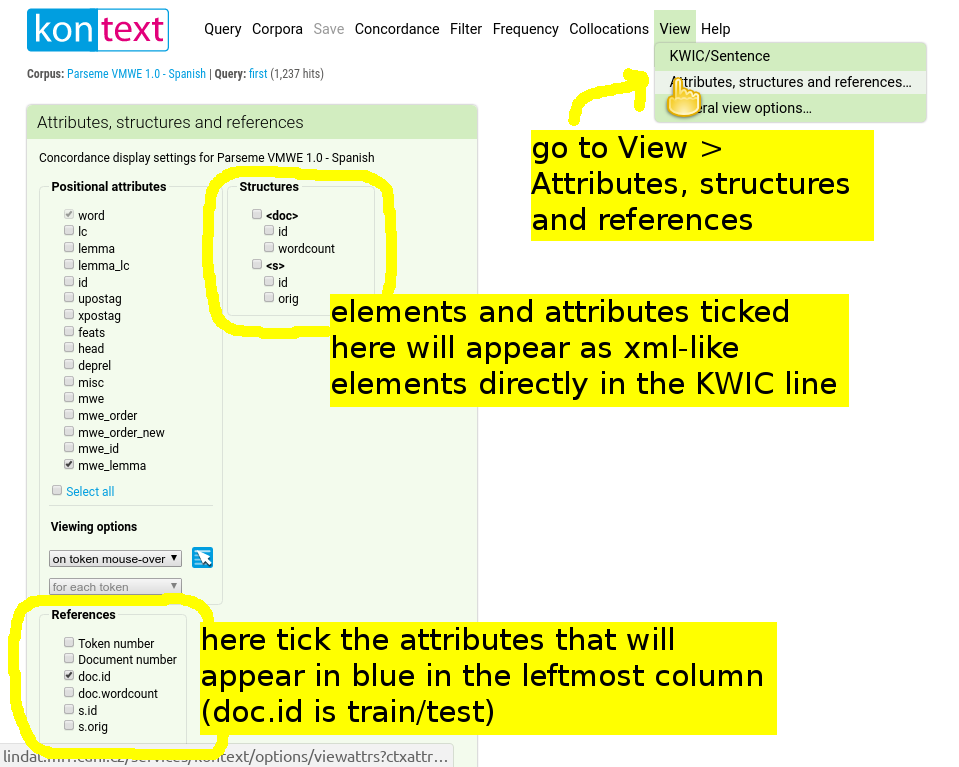
Metadata
The Spanish, French and Portuguese corpora contain metainformation in the form of sentence ids.
Besides that, portions of the data are marked as train or test data in the value of the attribute doc.id.
Metainformation can be viewed in several different ways:
Get involved
Post your own queries at the dedicated google group forum or report any issues or suggestions through the issue tracker.