CzEngVallex - Czech and English verbal valency
Czech and English verbal valency - a comparison
GP13-03351P - Srovnání české a anglické valence sloves na základě korpusového materiálu (teorie a praxe)
PI: Zdeňka Urešová
Quick links to:
- CzEngVallex browser in LINDAT/CLARIN
- Publications on CzEngVallex
- Project information in the government information system
The aim of the project is a cross-linguistic comparison of valency behavior of Czech and English verbs. Not only theoretical comparative studies particularly focused on differences in Czech and English verbal valency structure, but also hands-on experience of work with corpus data are expected. The theoretical aspects include both a description of verbal valency in both languages and a description of interlinking of translational verbal equivalents with drawing a follow-up comparison between the achieved results.
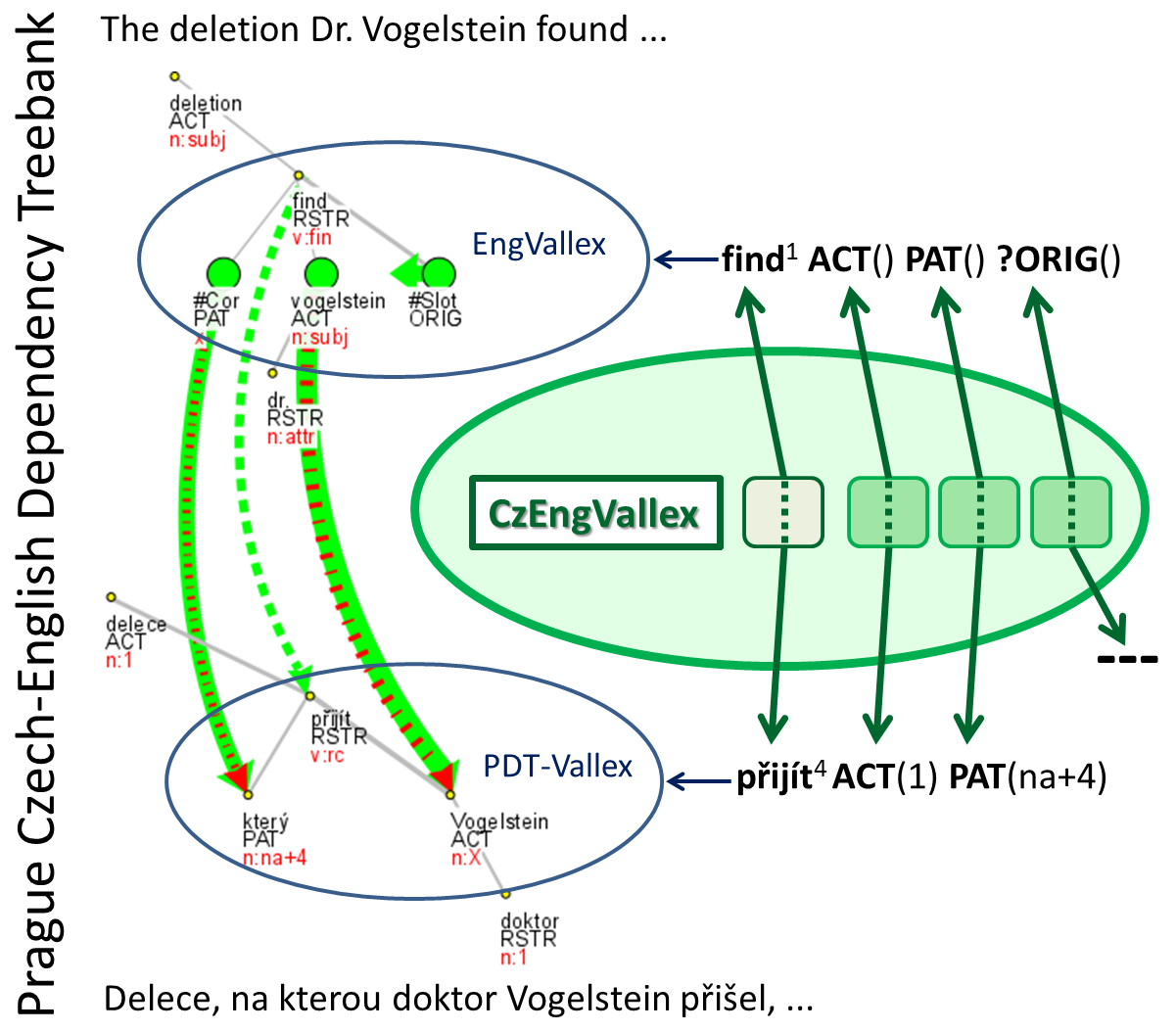
Fig. 1 Scheme of CzEngVallex and its linking to PDT-Vallex, EngVallex and the PCEDT corpus
The project is based on the valency theory of the Functional Generative Description and on its application to a corpus, namely to the Prague Czech-English Dependency Treebank (PCEDT; http://hdl.handle.net/11858/00-097C-0000-0015-8DAF-4). This theoretical approach allows a proposed specification of relations of verbal valency frames in both languages, relating to semantic and morphosyntactic level. The work with data includes the creation of a parallel bilingual Czech-English valency lexicon called CzEngVallex. The CzEngVallex (http://lindat.mff.cuni.cz/services/CzEngVallex; to download: http://hdl.handle.net/11234/1-1512) connects 20835 aligned valency frame pairs (verb senses) which are translations of each other, aligning their arguments as well. CzEngVallex' verb and argument pairings refer to two underlying valency lexicons used in PCEDT annotation, PDT-Vallex (http://lindat.mff.cuni.cz/services/PDT-Vallex) and EngVallex (http://lindat.mff.cuni.cz/services/EngVallex). The CzEngVallex serves as a powerful, real-text-based database of frame-to-frame and subsequently argument-to-argument pairs and can be used for example for machine translation applications.
How to search the CzEngVallex and the PCEDT corpus
The search tool enables to search either the CzEngVallex lexicon, or the associated parallel Czech-English corpus, the Prague Czech-English Dependency Treebank (PCEDT 2.0), or both at the same time, allowing for complex search conditions to use for various linguistic problems.
Search Interface Layout
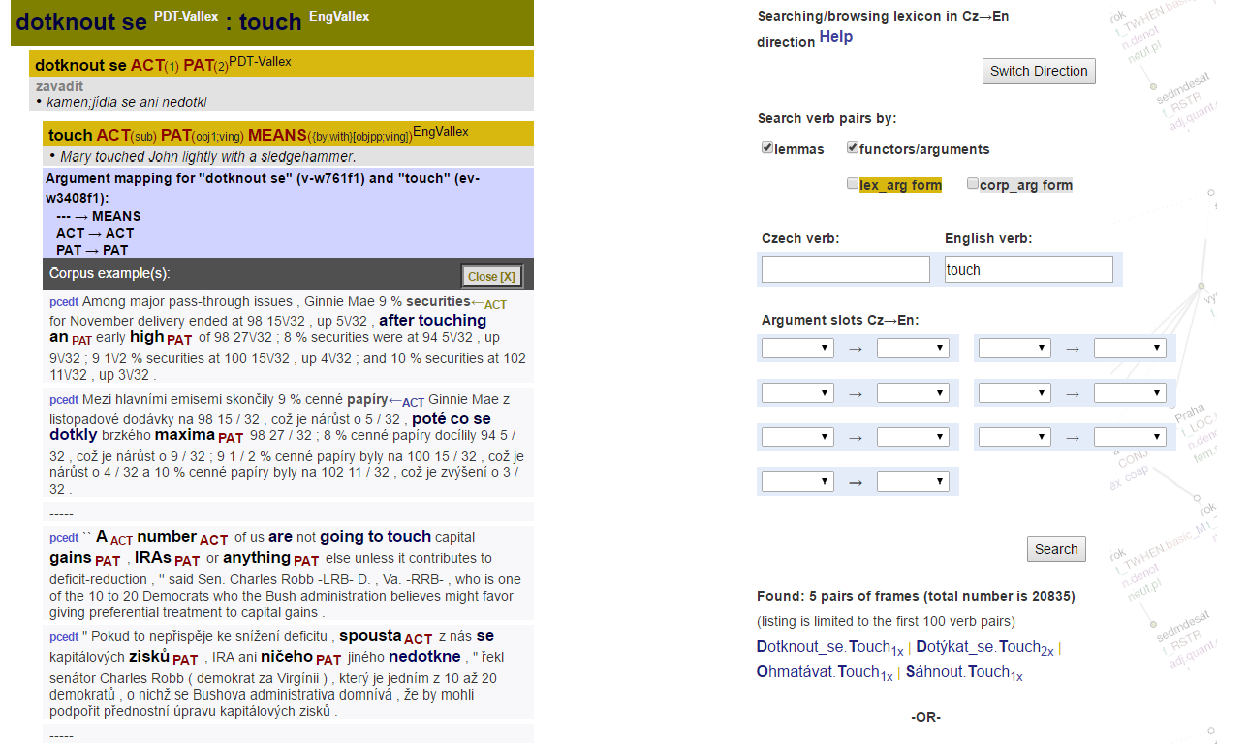
The search interface is divided into two parts: on the left, the query results (lexicon entries and the linked corpus sentences) appear after a query is executed. The query area is on the right, and it contains several fields to fill in or select to formulate the query (Fig. 2).
Search Direction
The Czech or English direction of search can be chosen by clicking the  toggle button near the direction specification, which shows the current direction (Searching/browsing lexicon in Cz→En direction). The search direction is only for convenience, since it only affects the layout (order) of the search fields below in the query area; the same results will be obtained by either direction by cross-filling in the query appropriately.
toggle button near the direction specification, which shows the current direction (Searching/browsing lexicon in Cz→En direction). The search direction is only for convenience, since it only affects the layout (order) of the search fields below in the query area; the same results will be obtained by either direction by cross-filling in the query appropriately.
Browsing the lexicon
As the simplest possible way of displaying CzEngVallex entries and the associated corpus sentences in which the verbs appear, the lexicon can be browsed by using the alphabet list in the Select verb area (lower part of the right-hand side of the query area) of the search interface (below the query entry area proper). After clicking on a letter, a list of verb pairs associated with the verbs starting by the selected letter on the source side appears. A particular pair can be then selected, and it appears in the query results area on the left.
Searching by verb lemma
The verb pairs can be searched by lemmas (checking the lemmas box) in both areas, in the lexicon and in the corpus, writing down the Czech or English lemma. One or both lemmas can be entered; if no lemma is filled in on either side, then some other part of the query has to be specified (see below).
Example: search for all pairs of verbs with “touch” on the English side:

Example: search for all pairs for verbs with “dotknout se” on the Czech side:

Example: search only for the pair “koupit-acquire” (if any):

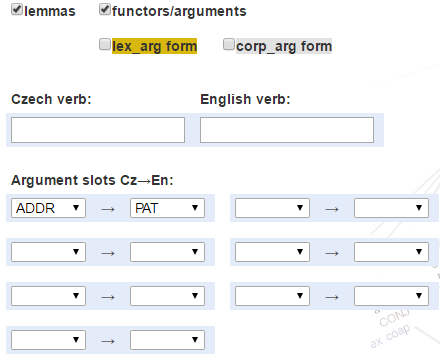
Search by argument functor(s) (argument label(s))
The search tool enables to search also according to the verb argument (functor) label by checking the functors/argument box. There are maximum seven arguments associated with any given verb; for simplicity, all of the seven possible functor search windows appear once the checkbox is on. The labels used are taken from the valency lexicons and corpus annotation (for a full specification, see the Functors chapter in the PDT Tectogrammatical manual).
Example: to search for all verb pairs where PATient (deep object) in English corresponds to ADDRessee argument in Czech:
(In this case, the user gets over 300 pairs of verbs from which it is necessary to select one pair to show the resulting CzEngVallex entry and the corresponding corpus examples.)
It is also possible to combine the search for a particular verb or verb pair with conditions on argument pairing.
Lexicon argument form (surface realization) search, step-by-step
In addition to searching by lemma and functors (arguments), a specific form realization can also be specified to further limit the search results. Then, for each possible argument, additional search window with yellow background appears that can be filled by the required form specification. For example, one can search for accusatives only as the surface realization of a particular argument, or for a prepositional case, subordinate clause etc., either together with filling in the functor and verb lemma, or independently in order to get, for example, all verb pairs where English PATient corresponds to Czech PATient expressed by the preposition “na” with locative case.
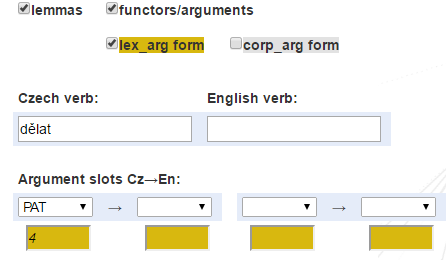
Example: search by lemma for functor PAT(ient) and for accusatives form realization:
Example: search without a lemma for functor PAT(ient) and for a prepositional case “o+6“:

Example: search without a lemma for functor PAT(ient) and for a subordinate clause introduced by the “aby” conjunction:

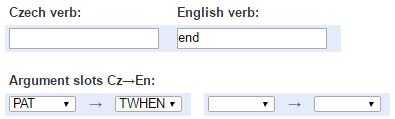
Example: search all verb pairs where English PAT(ient) corresponds to Czech PAT(ient) expressed by the preposition “na” with locative case:

Example: search all verb pairs where Czech PAT(ient) corresponds to English EFF(ect) while Czech PAT is expressed by the preposition “na” with locative case and where at the same time Czech ADDR corresponds to English Zero argument:

Lexical argument form specification
insert argument form specification to be looked for in the lexicon
for exact string describing the form specification in the lexicon: "=string" (=4), for regexp: “regexp" (^.*\+[46]); this applies to all cases below
for lemma: “=string”/“string” (=step)
for case (in Czech): “number” (6)
for prepositional case (in Czech): “string+number” (na+6)
for prepositions, subcategorization (English) and subordinate conjunctions: “string”, e.g. (to, objco, aby)
for content sentences (in Czech): “c”
for infinitives (in Czech): “f”
for direct speech (in Czech): "=.s"
for negation: use "~" as the first symbol (e.g. lemma is not hide: "~=step")
for special tags (mainly within DPHRs in Czech): use the string or regexp description, ex. \$1
combinations are possible - you can use "," as "AND" and ";" as "OR", where "AND" has lower priority (parentheses are allowed for grouping)
for description of tags, regular expressions and more examples, follow the “Search help” link
Corpus argument form specification
insert argument form specification to be looked for in the corpus
for exact lemma: "=l:string" or just “string” (=l:hide or =hide), for regexp: "l:regexp" (l:^un.*ing or ^un.*ing)
for exact form: "=f:string" (=f:hid), for regexp: "f:regexp" (f:toes$)
for tag: "=t:string" (NNMP7-----A----), for regexp: "t:regexp" (^NN..7)
for searching aux/lemma (or aux/form or aux/tag) use “x:” as prefix (i.e., "=x:f:string" or “x:t:^R...3” etc.); use “x:” for searching prepositions and subordinate conjunctions
for negation: use "~" as the first symbol (e.g. "lemma is not hide": "~=l:hide")
combinations are possible - you can use "," as "AND" and ";" as "OR", where "AND" has lower priority (parentheses are allowed for grouping)
some complex but common queries can be entered as simple macros (e.g. 4 for accusative case, na+6 for locative “na”, etc.); for macros, description of tags, regular expressions and more examples, follow the “Search help” link
Publications about CzEngVallex
Fučíková Eva, Hajič Jan, Urešová Zdeňka: Joint search in a bilingual valency lexicon and an annotated corpus. In: Proceedings of Coling 2016 (Demo papers), Copyright © ICCL, Sheffiled, GB, pp. 1-4, 2016 bibtex pdf
Fučíková Eva, Hajič Jan, Urešová Zdeňka: Enriching a Valency Lexicon by Deverbative Nouns. In: Proceedings of the Workshop Grammar and lexicon: Interactions and Interfaces, Copyright © International Committee for Computational Linguistics, Ōsaka, Japan, ISBN 978-4-87974-706-8, pp. 71-80, 2016 bibtex pdf
How to cite
If you use CzEngVallex for any purpose, cite always the following paper (and possibly one of those in the "Publications" section for specialized citations):
Urešová Zdeňka, Fučíková Eva, Šindlerová Jana: CzEngVallex: a bilingual Czech-English valency lexicon. In: The Prague Bulletin of Mathematical Linguistics, Vol. 105, Copyright © Univerzita Karlova v Praze, Prague, Czech rep., ISSN 0032-6585, pp. 17-50, 2016
@article{ biblio:UrFuCzEngVallexa2016,
journal = {The Prague Bulletin of Mathematical Linguistics},
title = {CzEngVallex: a bilingual Czech-English valency lexicon},
author = {Zde{\v{n}}ka Ure{\v{s}}ov{\'{a}} and Eva Fu{\v{c}}{\'{i}}kov{\'{a}} and Jana {\v{S}}indlerov{\'{a}}},
year = {2016},
address = {Prague, Czech rep.},
volume = {105},
pages = {17--50},
issn = {0032-6585},
}