PDT-C
Prague Dependency Treebank – Consolidated
Prague Dependency Treebank - Consolidated
A manually annotated and genre-diversified language resource with rich linguistic information from morphology and syntax to semantics, The Prague Dependency Treebank – Consolidated 2.0 (PDT-C in the sequel) is a consolidated release of the existing PDT-corpora of Czech data, uniformly annotated using the standard PDT scheme.
PDT-corpora included in PDT-C:
- Prague Dependency Treebank (written texts); latest published version 3.5
- Czech part of Prague Czech-English Dependency Treebank (translated data), latest published version 2.0 and 2.0Coref
- Prague Dependency Treebank of Spoken Czech (spoken data); latest published version 2.0
- PDT-Faust (“user-generated“ texts), published version 0.5
The difference from the separately published original treebanks can be briefly described as follows:
- it is published in one package, to allow easier data handling for all the datasets;
- the data is enhanced with a further manual linguistic annotation;
- morphological dictionary MorfFlex is enclosed (full compatibility with PDT-C morphological annotation);
- a common valency lexicon PDT-Vallex for all four original parts is enclosed.
In the previous PDT-C 1.0 version, the data was enhanced with a manual linguistic annotation at the morphological layer. For the PDT-C 2.0 version, manual annotation at the analytical layer is performed in those parts of the corpus that were previously annotated only by automatic tools. The goal of the annotation work is also to consolidate the manual annotation across all layers. This resulted in many modifications and corrections to the original annotation. Manual annotation of discourse relations is also now provided for all PDT-C 2.0 data (see also PDiT 4.0). In the PDT-C 2.0 release, there is now a manual annotation at the all annotation layers (morphological, surface syntactic (analytical), deep syntactic layer (tectogrammatical)) in all four datasets. Additional semantic features in the PDT dataset are also manually annotated.
Layers of annotations. The PDT-annotation scheme has a multi-layer architecture:
- morphological layer (m-layer): all tokens of the sentence get a lemma and morphological tag,
- surface syntax layer (analytical, a-layer): a dependency tree capturing surface syntactic relations such as subject, object, adverbial, etc.,
- deep syntax layer (tectogrammatical, t-layer): capturing the deep syntactic relations, ellipses, valency, topic-focus articulation, and coreference. In the process of the further development of the PDT-scenario, additional semantic annotations (bridging relation, discourse, genre specification, multi-word expressions, etc.) are being added to the original annotation scheme.
In addition to the above-mentioned three (main) annotation layers in the PDT-scenario, there is also the raw text layer (w-layer), where the text is segmented into documents and paragraphs and individual tokens are assigned unique identifiers. There is additional audio and speech recognition layer (z-layer) in the spoken data. In the spoken data part (as opposed to the written corpora), the w-layer is in fact also an “annotated” layer, namely the manually provided transcription of the audio signal.
In order not to lose any piece of the original information, tokens (nodes) at a lower layer are explicitly referenced from the corresponding closest (immediately higher) layer. These links allow for tracing every unit of annotation all the way down to the original text, or to the transcript and audio (in the spoken data).
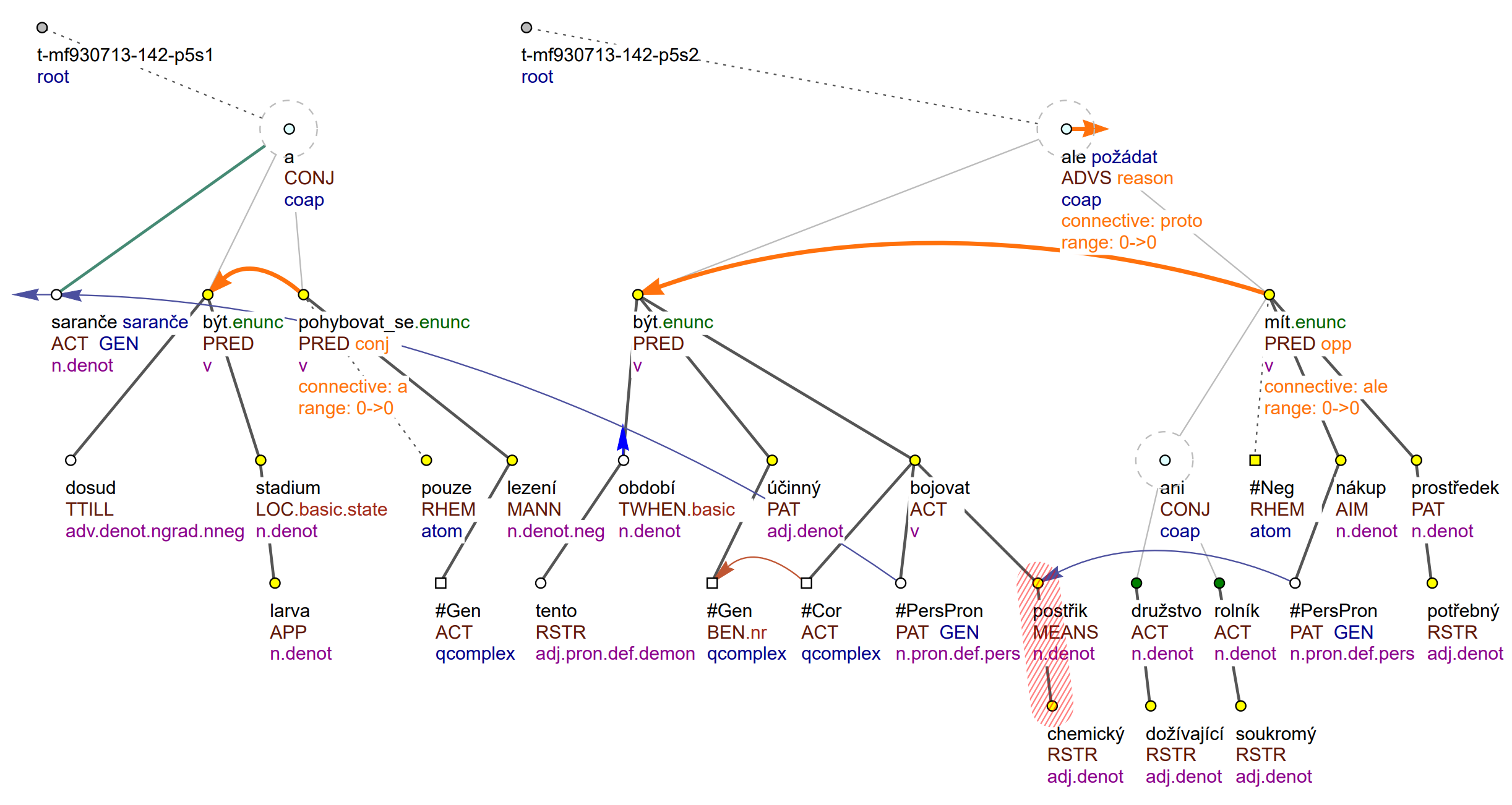
Sarančata jsou doposud ve stadiu larev a pohybují se pouze lezením. V tomto období je účinné bojovat proti nim chemickými postřiky, ale dožívající družstva ani soukromí rolníci nemají na jejich nákup potřebné prostředky.
Example sentences from PDT-C, with tectogrammatical annotation including coreference links (blue and brown arrows), MWEs (red stripes) and discourse annotation (orange arrows and attributes/lables). Lit.: Grasshoppers are still in the larvae stadium, crawling only. At this time of the year, it is efficient to fight them using chemicals, but neither the ailing cooperatives nor private farmers can afford them.
|
Dataset / Type of annotation |
PDT Written |
PCEDT (Czech) Translated |
PDTSC Spoken |
PDT-Faust User-generated |
|
Audio |
non-applicable |
non-applicable |
provided |
non-applicable |
|
ASR Transcription |
non-applicable |
non-applicable |
provided |
non-applicable |
|
Transcript |
non-applicable |
non-applicable |
manually |
non-applicable |
|
Translation |
non-applicable |
manually |
non-applicable |
manually |
|
Morphological layer |
||||
|
Speech reconstruction |
non-applicable |
non-applicable |
manually |
non-applicable |
|
Lemmatization |
manually |
manually |
manually |
manually |
|
Tagging |
manually |
manually |
manually |
manually |
|
Surface syntactic layer |
||||
|
Dependency structure |
manually |
manually |
manually |
manually |
|
Syntactic function |
manually |
manually |
manually |
manually |
|
Clause segmentation |
automatically |
not annotated |
not annotated |
not annotated |
|
Deep syntactic layer |
||||
|
Deep syntactic structure |
manually |
manually |
manually |
manually |
|
Deep syntactic function |
manually |
manually |
manually |
manually |
|
Verbal valency |
manually |
manually |
manually |
manually |
|
Nominal valency |
manually |
not annotated |
not annotated |
not annotated |
|
Grammatemes |
manually |
not annotated |
not annotated |
not annotated |
|
Coreference grammatical |
manually |
manually |
manually |
manually |
|
Coreference textual |
manually |
manually |
manually |
manually |
|
Bridging relation |
manually |
not annotated |
not annotated |
not annotated |
|
Topic-focus articulation |
manually |
not annotated |
not annotated |
not annotated |
|
Discourse |
manually |
manually |
manually |
manually |
|
Genre specification |
manually |
not annotated |
not annotated |
not annotated |
|
Quotation |
manually |
not annotated |
not annotated |
not annotated |
|
Multiword expressions |
manually |
not annotated |
not annotated |
not annotated |
Table 1: Overview of various types of annotation and their realization in the datasets
Volume of the data
The data volume is given in Table 2. Altogether, the consolidated treebank contains 3,885,591 tokens with manual morphological annotation and 2,245,945 t-nodes with manual deep syntactic annotation (manual annotation of the surface syntactic layer is contained only in the dataset of written texts and it consists of 1,503,741 a-nodes).
|
|
PDT Written |
PCEDT (Czech) Translated |
PDTSC Spoken |
PDT-Faust User-generated |
Total |
|
Morphological layer (number of m-forms) |
1,957,150 |
1,152,289 |
742,316 |
33,836 |
3,885,591 |
|
Surface syntactic layer (number of a-nodes) |
1,503,637 |
1,152,289 |
742,316 |
33,836 |
3,432,078 |
|
Deep syntactic layer (number of t-nodes) |
675,099 |
931,211 |
607,906 |
30,072 |
2,244,288 |
Table 2. Volume of the datasets (number of tokens on the respective layers)
How to cite the Prague Dependency Treebank - Consolidated 2.0 (PDT-C 2.0):
If you use the data in your research or need to cite it for any reason, please cite:
For LREC papers (separate language resources references):
@languageresource{lrPDT-C20,
title={{P}rague {D}ependency {T}reebank - {C}onsolidated 2.0 ({PDT-C} 2.0)},
author={Haji\v{c}, Jan and Bej\v{c}ek, Eduard and B\'{e}mov\'{a}, Alevtina
and Bur\'{a}\v{n}ov\'{a}, Eva and Fu\v{c}\'{i}kov\'{a}, Eva and Haji\v{c}ov\'{a}, Eva and Havelka, Ji\v{r}\'{\i}
and Hlav\'{a}\v{c}ov\'{a}, Jaroslava and Homola, Petr and Ircing, Pavel and K\'{a}rn\'{\i}k, Ji\v{r}\'{\i} and Kettnerov\'{a}, V\'{a}clava
and Klyueva, Natalia and Kol\'{a}\v{r}ov\'{a}, Veronika and Ku\v{c}ov\'{a}, Lucie and Lopatkov\'{a}, Mark\'{e}ta
and Mare\v{c}ek, David and Mikulov\'{a}, Marie and M\'{\i}rovsk\'{y}, Ji\v{r}\'{\i} and Nedoluzhko, Anna and Nov\'{a}k, Michal
and Pajas, Petr and Panevov\'{a}, Jarmila and Peterek, Nino and Pol\'{a}kov\'{a}, Lucie and Popel, Martin and Popelka, Jan
and Rompoltl, Jan and Rysov\'{a}, Magdal\'{e}na and Semeck\'{y}, Ji\v{r}\'{i} and Sgall, Petr and Spoustov\'{a}, Johanka
and Straka, Milan and Stra\v{n}\'{a}k, Pavel and Synkov\'{a}, Pavl\'{\i}na
and {\v{S}}ev\v{c}\'{\i}kov\'{a}, Magda and {\v{S}}indlerov\'{a}, Jana and {\v{S}}t\v{e}p\'{a}nek, Jan
and {\v{S}}t\v{e}p\'{a}nkov\'{a}, Barbora and Toman, Josef and Ure\v{s}ov\'{a}, Zde\v{n}ka and Vidov\'{a} Hladk\'{a}, Barbora
and Zeman, Daniel and Zik\'{a}nov\'{a}, {\v{S}}\'{a}rka and {\v{Z}}abokrtsk\'{y}, Zden\v{e}k},
url = {http://hdl.handle.net/11234/1-3185},
publisher={Institute of Formal and Applied Linguistics, LINDAT/CLARIAH-CZ, Charles University},
address={Prague, Czech Republic},
lindat={http://hdl.handle.net/11234/1-5813},
year={2024} }
For general papers and citations:
@misc{pdtc20,title={{P}rague {D}ependency {T}reebank - {C}onsolidated 2.0 ({PDT-C} 2.0)}, author={Haji\v{c}, Jan and Bej\v{c}ek, Eduard and B\'{e}mov\'{a}, Alevtinaand Bur\'{a}\v{n}ov\'{a}, Eva and Fu\v{c}\'{i}kov\'{a}, Eva and Haji\v{c}ov\'{a}, Eva and Havelka, Ji\v{r}\'{\i} and Hlav\'{a}\v{c}ov\'{a}, Jaroslava and Homola, Petr and Ircing, Pavel and K\'{a}rn\'{\i}k, Ji\v{r}\'{\i} and Kettnerov\'{a}, V\'{a}clava and Klyueva, Natalia and Kol\'{a}\v{r}ov\'{a}, Veronika and Ku\v{c}ov\'{a}, Lucie and Lopatkov\'{a}, Mark\'{e}ta and Mare\v{c}ek, David and Mikulov\'{a}, Marie and M\'{\i}rovsk\'{y}, Ji\v{r}\'{\i} and Nedoluzhko, Anna and Nov\'{a}k, Michal and Pajas, Petr and Panevov\'{a}, Jarmila and Peterek, Nino and Pol\'{a}kov\'{a}, Lucie and Popel, Martin and Popelka, Jan and Rompoltl, Jan and Rysov\'{a}, Magdal\'{e}na and Semeck\'{y}, Ji\v{r}\'{i} and Sgall, Petr and Spoustov\'{a}, Johanka and Straka, Milan and Stra\v{n}\'{a}k, Pavel and Synkov\'{a}, Pavl\'{\i}na and {\v{S}}ev\v{c}\'{\i}kov\'{a}, Magda and {\v{S}}indlerov\'{a}, Jana and {\v{S}}t\v{e}p\'{a}nek, Jan and {\v{S}}t\v{e}p\'{a}nkov\'{a}, Barbora and Toman, Josef and Ure\v{s}ov\'{a}, Zde\v{n}ka and Vidov\'{a} Hladk\'{a}, Barbora and Zeman, Daniel and Zik\'{a}nov\'{a}, {\v{S}}\'{a}rka and {\v{Z}}abokrtsk\'{y}, Zden\v{e}k}, url = {http://hdl.handle.net/11234/1-5813},
note = {{LINDAT}/{CLARIAH-CZ} digital library, Institute of Formal and Applied Linguistics ({{\'U}FAL}),
Faculty of Mathematics and Physics, Charles University},
copyright={Creative Commons - Attribution-{NonCommercial}-{ShareAlike} 4.0 International ({CC} {BY}-{NC}-{SA} 4.0)},
year={2024} }
For "plaintext" reference:
(Hajič et al., 2024)
Jan Hajič, Eduard Bejček, Alevtina Bémová, Eva Buráňová, Eva Fučíková, Eva Hajičová, Jiří Havelka, Jaroslava Hlaváčová, Petr Homola, Pavel Ircing, Jiří Kárník, Václava Kettnerová, Natalia Klyueva, Veronika Kolářová, Lucie Kučová, Markéta Lopatková, David Mareček, Marie Mikulová, Jiří Mírovský, Anna Nedoluzhko, Michal Novák, Petr Pajas, Jarmila Panevová, Nino Peterek, Lucie Poláková, Martin Popel, Jan Popelka, Jan Romportl, Magdaléna Rysová, Jiří Semecký, Petr Sgall, Johanka Spoustová, Milan Straka, Pavel Straňák, Pavlína Synková, Magda Ševčíková, Jana Šindlerová, Jan Štěpánek, Barbora Štěpánková, Josef Toman, Zdeňka Urešová, Barbora Vidová Hladká, Daniel Zeman, Šárka Zikánová, Zdeněk Žabokrtský: Prague Dependency Treebank - Consolidated 2.0 (PDT-C 2.0). Data/software, LINDAT-CLARIAH-CZ, URL: http://hdl.handle.net/11234/1-5813, 2024.
For footnote references, the following is sufficient in LaTeX papers:
\url{http://hdl.handle.net/11234/1-5813}