Čapek
Sentence diagramming editor
Introduction
We have been developing Čapek, an annotation editor tailored to schoolchildren. It allows them to practice morphology and syntax in a similar way as they normally do at (a Czech) school with a paper and pencil. The editor is designed to be language independent and it presents an extension of the STYX system, an electronic exercisebook of Czech morphology and syntax.
More details
- Tokenization: A process of tokenization of the sentence is quite a complex task. In school practicing, schoolchildren split sentences into tokens without hesitation more or less intuitively. That is possible mainly due to the fact that the sentences they work with are usually quite simple. Thus we decided not to force users to tokenize sentences manually. Instead, the system automatically runs tokenization.
- Practicing morphology: After tokenization, the sentence is considered to be a sequence of tokens. The user does the morphological analysis of tokens using a set of combo boxes or context menus. The set of part of speech classes and morphological categories is configurable for any language simply by providing a configuration file corresponding to the given annotation scheme.
-
Practicing syntax: By default, the editor is designed to enable practicing dependency-based syntax. However, it's possible to add a module for practicing phrase-based syntax. Čapek enables to manipulate the nodes via the operations accomplished using the drag and drop techniques:
- making a node dependent on another node
- labeling a node with a syntactic function (as in the case of the morphological analysis, a set of syntactic functions is configurable for any language simply by providing a configuration file corresponding to the given annotation scheme),
- joining the nodes
- splitting a node.
- The editor is named after Czech writer Karel Čapek.
Prototype version download
- Web-based prototype can be found here/.
-
Standalone application
- Unpack the archive.
- Run capek\bin\capek.exe on MS Windows; run capek/bin/capek on Linux.
View sentences analyzed by teachers
We selected a sample of 100 sentences from Czech textbooks to serve as a workbench. They were analyzed by two teachers. We present analyses of 31 sentences analyzed by one of the two teachers -- start here.
What are we interested in
In the Czech Republic, children (both at the elementary school level and high school level) -- as a very important part of their Czech language education curriculum -- are required to parse sentences into dependencies structured as trees (see the analysis of "Yellow kingcups blossemed out near by stream." below).
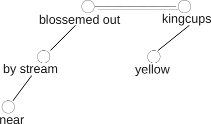
We would like to see whether there are similar requirements on children in your country, that is, eventually, whether we could broaden our perspective to other languages as well or whether we have to limit ourselves to Czech. Could you please help us with the following questions?
Geoff Dean and Dick Hudson address the same issue here.
A case study
We use the editor to explore a new way to get more morphologically and syntactically annotated data by transforming their annotation into a more linguistically appropriate schema. We have been testing it for the Czech language and the Prague Dependency Treebank annotation schema.
Acknowledgement
This project was partially supported by the GAUK grant No. 1568314.