



.")
.")



Dokumentace na této stránce se vztahuje pouze k novinkám v PDT 2.5 oproti PDT 2.0, jehož podrobnou dokumentaci naleznete zde. PDT 2.5 obsahuje tyto novinky:
Anotace víceslovných jednotek
Všechny víceslovné výrazy dané věty jsou uloženy v atributu mwes kořene jejího tektogramatického stromu. Atribut mwes je tvořen seznamem, jehož prvky reprezentují jednotlivé víceslovné výrazy v dané větě. Každý prvek seznamu mwes, tedy každá reprezentace víceslovné jednotky obsahuje ID, základní tvar výrazu v elementu basic_form, typ výrazu v elementu type a seznam ID t-uzlů, z nichž se víceslovný výraz skládá.
Anotované víceslovné výrazy jsou buďto víceslovné lexémy, nebo pojmenované entity, které nemusí mít charakter lexému, ale přesto uvnitř nich neplatí běžné syntaktické vztahy. U pojmenovaných entit určujme jejich druh. Typ víceslovné jednotky tedy může nabývat následujících hodnot:
- „lexeme“ – víceslovný lexém
- „person“ – jméno osoby nebo zvířete
- „institution“ – název instituce
- „location“ – zeměpisný název
- „object“ – název knihy, měrné jednotky, přírodovědné a chemické názvosloví
- „address“ – adresa
- „time“ – časový údaj či datum
- „biblio“ – bibliografický údaj
- „foreign“ – cizojazyčný výraz
- „number“ – číselný výraz, obvykle rozsah
Anotované víceslovné výrazy se v TrEdu zobrazují jako barevně šrafované množiny uzlů v tektogramatickém stromě (jehož topologie je až na případné opravy shodná s PDT 2.0), nebo jako jeden uzel. V tomto zkolabovaném zobrazení jsou děti t-uzlů, jež se staly prvky víceslovného výrazu, převěšeny přímo na tento nový uzel víceslovného výrazu. V „rozbaleném“ zobrazení jsou monžiny různých druhů víceslovných výrazů (viz výše) zobrazeny různými barvami.
Postup anotace
Byly anotovány všechny výskyty víceslovných výrazů (včetně pojmenovaných entit, viz níže) v části PDT, která obsahuje tektogramatickou rovinu. Značná část dat byla anotována paralelně. Tabulka udává, kolik dat bylo anotováno jedním anotátorem, dvěma či třemi anotátory paralelně, a jaký je poměr paralelních anotací ve vztahu k celé t-rovině. Čísla jsou uvedena v počtu souborů i v počtu tektogramatických uzlů v těchto souborech.
| Anotovaná data | |||||
|---|---|---|---|---|---|
| paralelní annotace | 1 | 2 | 3 | PDT | 2+3/PDT |
| t-sobory | 1 288 | 1 412 | 465 | 3 165 | 59% |
| t-uzly | 248 448 | 343 834 | 82 683 | 674 965 | 63% |
Soubory anotované jednotlivými anotátory nejsou součástí PDT 2.5, ale jsou dostupné pod licencí Creative Commons na stránce projektu. Pro vydání v PDT 2.5 byly všechny neshody anotátorů jednoznačně rozhodnuty a vznikla tak gold standard data: Pokud se anotátoři shodli, víceslovný výraz byl zachován. Případy, kdy se neshodli byly řešeny následovně:
- Pokud byl víceslovný výraz označen pouze jedním anotátorem, ponechali jsme anotaci, neboť se ukázalo, že mnohem spíše anotátor víceslovný výraz přehlédne, než by chybně označil něco navíc.
- Pokud jeden anotátor anotoval víceslovný výraz, který tvoří podmnožinu uzlů výrazu anotovaného druhým anotátorem, ponechali jsme výraz rozsáhlejší.
- Naopak jestliže jeden anotátor anotoval několik podmnožin výrazu druhého anotátora tak, že svou anotací plně pokryl daný rozsáhlejší výraz, zvolili jsme kratší výrazy.
- Případy průniku anotace dvou anotátorů byly individuálně rozhodnuty třetím anotátorem.
- Případy, kdy jeden anotátor anotoval podmnožiny výrazu anotovaného druhým anotátorem, ale nepokryl výraz celý (tedy se anotátoři neshodli, které t-uzly jsou součástí víceslovného výrazu) byly také rozhodnuty ručně třetím anotátorem.
Příklady
Prezident Havel by měl 15. července* na Pražském hradě** jmenovat třináct soudců Ústavního soudu***.
* – date, basic_form „15. červenec“
** – location, basic_form „Pražský hrad“
*** – institution, basic_form „Ústavní soud“
Funkce ústavního soudce* je neslučitelná s členstvím v politických stranách**.
* – lexeme, basic_form „ústavní soudce“
** – lexeme, basic_form „politická strana“
Souborovost
Hodnotami gramatému typgroup je reprezentována sémantická opozice souborového významu vs. významu jednotlivých entit (hodnoty group vs. single; třetí hodnota nr se užívá pro nerozhodnutelné případy). Česká substantiva jako ruce, boty nebo klíče odkazují svými tvary množného čísla k páru nebo k většímu typickému souboru častěji než k většímu množství jednotlivých entit; např. plurálový tvar ruce označuje pár nebo několik párů rukou častěji než prosté větší množství horních končetin, tvar boty obvykle vyjadřuje pár nebo několik párů bot, tvar klíče odkazuje ke svazku nebo několika svazkům klíčů. Protože souborový význam vyjadřuje většina českých konkrétních substantiv a tento význam má vliv na spojitelnost substantiv s číslovkami (při označování souborů se substantivum spojuje pouze se souborovými číslovkami, při vyjadřování jednotlivých entit s číslovkami základními; srov. dvoje boty vs. dvě boty), je souborový význam považován za gramatikalizovaný význam českých substantiv.
V češtině je souborový význam vyjadřován formálně nepříznakovými plurálovými tvary substantiv. Protože souborový význam lze od jiných významů plurálových substantiv odlišit díky přítomnosti číslovky (k souvýskytu substantiva se souborovou číslovkou ovšem v korpusových datech dochází zřídka) nebo na základě kontextu nebo znalosti světa, identifikace tohoto významu u většiny substantiv v korpusu by byla úkolem pro ruční anotaci. Nicméně, vzhledem k tomu, že na základě pilotního anotačního experimentu byla očekávána nízká frekvence souborového významu, ve snaze o co nejefektivnější anotaci byly ručně anotovány pouze plurálové tvary těch substantiv, pro která je souborový význam považován za prototypický. Souborový význam je jako prototypický očekáván pro následující skupiny substantiv:
- substantiva označující párové nebo souborové části těla (př. uši, prsty, vlasy)
- oblečení a doplňky určené pro tyto tělesné části (př. náušnice, rukavice)
- rodinní příslušníci tvořící páry nebo skupiny, jako rodiče, dvojčata
- předměty denní potřeby a potraviny prodávané nebo používané v typickém množství (př. klíče, sirky, sušenky)
Anotační procedura
V PDT 2.5 byl gramatém typgroup poloautomaticky anotován u všech pojmenovacích sémantických substantiv (uzly se sempos=n.denot|n.denot.neg). Nejprve byla provedena ruční anotace: výskyty pro ruční anotaci byly vybrány na základě seznamu tektogramatických lemmat (t-lemmat) prototypických souborových substantiv. Do tohoto seznamu byla zařazena substantiva, která byla v datech PDT 2.0 a SYN2005 doprovázena souborovou číslovkou, dále substantiva uváděná v mluvnických příručkách a odborných statích týkajících se kategorie čísla, seznam byl doplněn také na základě introspekce. Pro t-lemmata z výsledného seznamu bylo v datech PDT 2.5 nalezeno více než 600 výskytů plurálových forem (většina z nich náležela k těmto t-lemmatům: oko, rodič, ruka, bota).
Tyto výskyty byly anotovány paralelně dvěma anotátory, s mezianotátorskou shodou 75.1% (Cohenovo kappa 0.67). Po ukončení ruční anotace byly výskyty, na jejichž anotaci se anototáři neshodli, rozhodnuty třetím anotátorem. Tímto anotátorem byly zkontrolovány rovněž výskyty anotované oběma anotátory shodně – s cílem zkontrolovat správnost a konzistenci anotace.
Souborový význam je úzce spjat s gramatickou kategorií čísla substantiv; v češtině je kategorie čísla konstituována opozicí singuláru a plurálu. V souvislosti s ruční anotací souborového významu byly hodnoty gramatému čísla number (hodnoty sg, pl, a nr) změněny oproti původní anotaci (PDT 2.0) následujícím způsobem: pokud byla plurálová forma identifikována jako vyjádření jednoho souboru (typgroup=group), hodnota gramatému number byla změněna na sg; pokud plurálová forma označovala více souborů (typgroup=group), hodnota gramatému number se neměnila (zůstala pl); pokud anotátoři nebyli s to rozhodnout mezi významem jednoho souboru a významem více souborů (typgroup=group), v gramatému number byla vyplněna hodnota nr.
U pojmenovacích sémantických substantiv, která nebyla zahrnuta do ruční anotace, byl gramatém typgroup anotován automaticky. Automatická anotace postupovala podle jednoduchého „algoritmu“ sestávajícího ze dvou kroků: v prvním kroku byla u substantiv, která byla doprovázena souborovou číslovkou jedny (s výjimkou pluralií tantum), vyplněna v gramatému typgroup hodnota group, v této souvislosti byla hodnota gramatému number změněna na sg; u substantiva doprovázeného souborovou číslovkou vyšší hodnoty (dvoje, troje atd.) byla v gramatému typgroup vyplněna hodnota group, zatímco gramatém number zůstal nezměněn (tj. pl). Ve druhém kroku byla všem zbývajícím substantivům v gramatému typgroup přiřazena hodnota single, hodnota gramatému number v těchto případech zůstala stejná jako ve výchozí anotaci (PDT 2.0).
V datech PDT 2.5 se vyskytují následující kombinace hodnot gramatémů number a typgroup:
- sg.group – význam jednoho souboru, vyjadřován plurálovou formou substantiva
- pl.group – význam více souborů, vyjadřován plurálovou formou substantiva
- nr.group – případy, kdy plurálová forma substantiva označuje jeden nebo více souborů
- sg.single – význam jedné entity, vyjadřován singulárovou formou substantiva
- pl.single – význam více jednotlivých entit, vyjadřován plurálovou formou substantiva
- nr.single – u uzlů, u nichž nebyla rozpoznána hodnota čísla (number=nr), byla v gramatému typgroup defaultně vyplněna hodnota single
- nr.nr – tato kombinace je přiřazena víceznačným případům: u těchto případů nebylo možné vyloučit kombinaci sg.group ani pl.group ani pl.single (v kombinaci nr.nr ovšem není zahrnuta kombinace sg.single!)
Příklady
Pro každé pojmenovací sémantické substantivum jsou kurzivou uvedeny hodnoty gramatémů number a typgroup; substantiva, u kterých byla hodnota gramatému typgroup určena v rámci ruční anotace, jsou označena tučně:
- Navlékla bych si dvoje ponožky.pl.group a hrála bych naboso, dokud by mi někdo nesehnal nějaké boty.sg.group.
- Pro něho připravila firma.sg.single Lotto.sg.single speciální kopačky.nr.group.
- Sečíst pouhým okem.sg.single stranickou příslušnost.sg.single zvednutých rukou.pl.single bylo ve dvousetčlenné Poslanecké sněmovně.sg.single nemožné.
- ... je to také odpověď.sg.single na vzdělávací požadavky.pl.single rodičů.nr.nr, žáků.pl.single, ale i měnícího se trhu.sg.single práce.sg.single.
- Obsah PCB.nr.single ve vepřovém a drůbežím mase je již minimální.
Klauze
Analytické stromy v PDT 2.5 jsou obohaceny o anotaci klauzí. Klauze odpovídá jedné větě s jedním určitým slovesem. Klauze může být součástí souvětí. Anotaci klauzí lze použít pro trénovaní rozpoznávačů hranic vět, které mohou být užitečné v řadě dílčích úkolů při zpracování přirozeného jazyka, mj. při syntaktické analýze nebo strojovém překladu.
Očekávali jsme, že anotaci klauzí lze provést s vysokou úspěšností automaticky, máme-li už k dispozici ruční anotaci morfologie a závislostní syntaxe. Anotace klauzí v PDT 2.5 je tedy z větší části založena na aplikaci automatických pravidel. Ruční anotace byly provedeny pouze pro malou část dat, tato data byla použita pro vývoj procedury pro automatické značkování. F-skóre této procedury dosahovalo 97.51 %. Aby byla anotace klauzí v PDT konzistentní, tato procedura byla aplikována na všechna data v PDT a původní ruční anotace nejsou do PDT 2.5 zahrnuty.
Anotační schéma
Technicky jsou hranice klauzí reprezentovány novým atributem clause_number přiřazeným k analytickým uzlům. Jestliže dva analytické uzly ve stromě sdílení stejnou nenulovou hodnotu tohoto atributy, potom patří do stejné klauze. Nulová hodnota tohoto atributy je rezervovaná pro hraniční tokeny (tj. tokeny umístěné na hranicí dvou klauzí, které nemohou být jednoznačně přiřazeny ani k jedné z nich). Hraniční tokeny jsou typicky interpukční značky (značkované jako Z:) nebo koordinační spojky (J^). Podřadicí spojky (J,) jsou systematicky zařazovány do příslušné závislé klauze.
Vizualizace
Segmentaci klauzí lze pohodlně zobrazit v TrEdu (viz. Obrázek 1). Nové rozšíření TrEdu pro zobrazování dat PDT 2.5 nabízí dvě další makra spojená s anotací klauzí:
- Sbalování/rozbalování klauzí (f) – Pokud je sbalování klauzí zapnuto, všechny tokeny reprezentující stejnou klauzi jsou reprezentovány jediným uzlem. V takové zobrazení nejlépe vynikne struktura souvětí.
- Barvení klauzí (c) – Pokud je barvení klauzí zapnut, uzly, které patří do stejné klauze, jsou zobrazeny stejnou barvou.
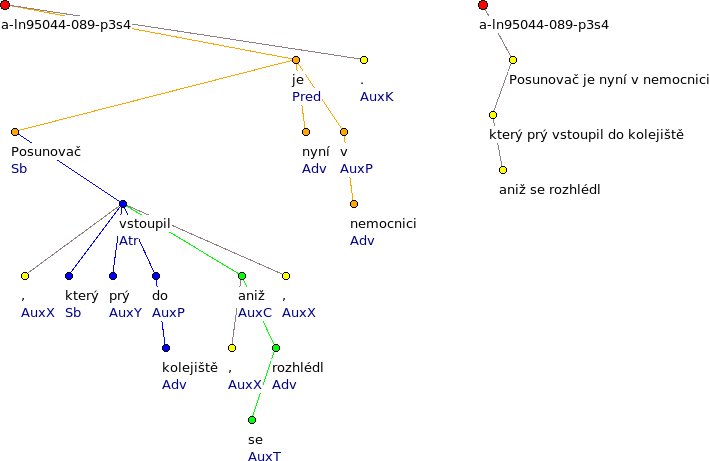
Obrázek 1: Věta 'Posunovač, který prý vstoupil do kolejiště, aniž se rozhlédl, je nyní v nemocnici.' reprezentovaná dvěma stromy: úplný strom na levé straně a strom s klauzemi zredukovanými do uzlů na pravé straně.
Příklady
U sochy básníka seděl vlasatý mladík a* hrál Vysockého písně.**
* – hranice klauzí, souřadná spojka spojuje
dvě klauze
** – interpunkce na konci věty, hranice věty
Pokud jde o kupní smlouvu a* všechny náležitosti s ní spojené,** musí si to zařídit a* zaplatit strany samy.
* – koordinační spojky spojující větné
členy uvnitř klauze
** – hranice klauzí, interpunkce
Lidé na nás tehdy chodili, aby* se odreagovali od přítomného režimu.
* – podřadicí spojka
Posunovač, který prý vstoupil do kolejiště, aniž se rozhlédl, je nyní v nemocnici*.
* – hlavní klauze rozdělená do dvou částí
závislou vztažnou klauzí (která je dále modifikována závislou klauzí)
Anotační procedura
Automatická procedur pro rozpoznávání klauzí pracuje následovně:
- Identifikujeme "jádra" klauzí. Každý výskyt určitého slovesa je označen jako nové jádro klauze.
- Jádra tvořící složenou slovesnou formu jsou spojena. Jádra s analytickou funkcí pomocného slovesa (AuxV) nemohou samy tvořit klauzi.
- Strom je rekurzivně procházen (v pořadí post-order) a každá hlava koordinace je dočasně připojena ke klauzi svého nejvíce vpravo umístěného členu.
- Dokončení klauzí. Strom je rekurzivně procházen (v pořadí pre-order) a každý uzel je zpracován se svými potomky. Uzly, které nepatří zatím do žádné klauze, jsou typicky přiřazeny ke klauzi rodiče. Speciální zpracování ovšem vyžadují koordinační struktury.
- Náležitost k příslušné klauzi je znovu přepočítána pro všechny potenciální hraniční uzly.
Souhrnné statistické údaje
Segmentace na jednotlivé klauze je v PDT 2.5 k dispozici pro 87 913 vět, které obsahují celkem 153,434 klauzí. Obrázek 2 zobrazuje rozložení počtu klauzí na větu, Obrázek 3 zobrazuje nejčastější typy struktury souvětí.
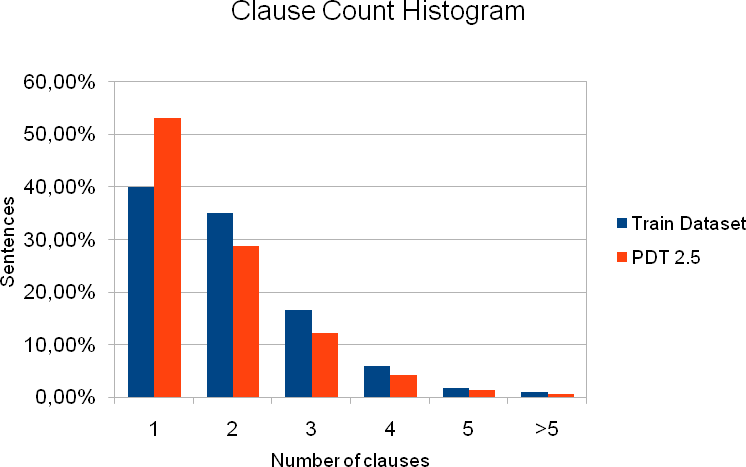
Obrázek 2
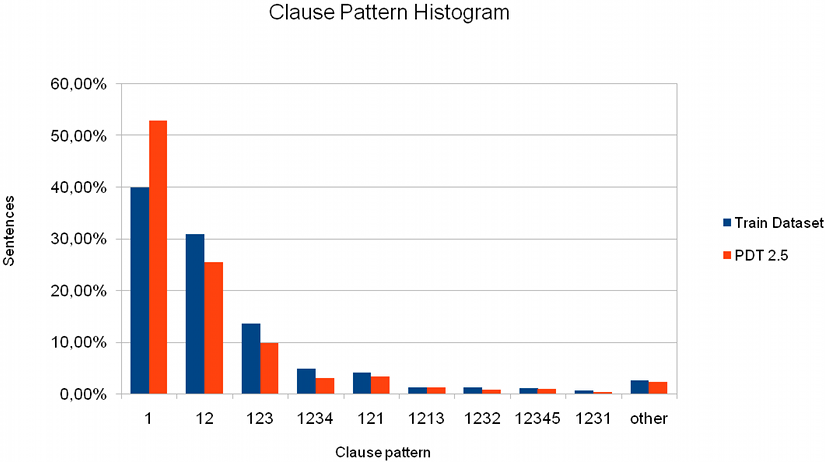
Obrázek 3: Pro jednoduchost jsou zde klauze označené číslicem. Vzorec "12" odpovídá souvětí tvořenému dvěma klauze, vzorec "121" odpovídá také souvětí se dvama klauzemi, přičem jedna z nich je vnořená uprostřed druhé
Opravy původních dat
V datech PDT 2.0 byly ručně provedeny následující změny:
w-rovina
- Opraveny mezery kolem levých závorek.
m-rovina
- Morfologické značky následujících slov byly opraveny tak, aby odpovídaly analytickým funkcím příslušných uzlů na a-rovině: až, co, dál, dále, daleko.
- Morfologická značka pro slovní formu
budoucnu
byla opravena. - Většina ženských křestních jmen v plurálu měla být označkována jinak.
- Některá příjmení homonymní s jinými slovy nebyla původní
morfologickou analýzou vůbec rozeznána:
Čermák
,Pešek
,Homolka
,Hromada
,Zeman
. - Dvě možné analýzy slova
druhý
byly sloučeny. -
ES
není formou slovaeso
, ale zkratkou proEuropean Unions
. - Byla sjednocena analýza slova
International
. - Byla opravena anotace zkratek jmen a krátkých částí jmen (např.
J.
neboO'
), včetně shody v rodě s příjmením. - Byly opraveny příznaky pro jméno a příjmení v lemmatu
(
_Ya_S). - Byla opravena anotace fráze
P. O. Box
. - Byly odstraněny chyby v kódování (
ˇ
namísto dvojitých uvozovek, pomlčky nebo§
). - Byla sjednocena anotace frází
s. r. o.
aa. s.
. - Byla opravena anotace části jmen měst
Králové
.
a-rovina
- Konstrukce používající
co
byly opraveny v souladu s m-rovinou.
t-rovina
- Všechny změny v lemmatech na m-rovině se promítly do t-roviny.
- Hodnota atributu
is_name_of_personbyla opravena tak, aby byla v souladu s morfologickou anotací. - Gramatémy křestních jmen a příjmení byly opraveny, aby se jména shodovala v rodě a čísle.
Plus nejrůznější jednotlivé opravy na všech rovinách.