Universal Derivations
Universal Derivations
Universal Derivations (UDer) is a collection of harmonized lexical networks capturing word-formation, especially derivation, in a cross-linguistically consistent annotation scheme for many languages. The annotation scheme is based on a rooted tree data structure (as used in the DeriNet 2.0 database), in which nodes correspond to lexemes while edges represent derivational relations or compounding.
Online tools
Each individual resource in the UDer collection can be searched online using two versions of DeriNet Search. DeriSearch v2 shows all pieces of information stored in the data. The data can be processed using DeriNet 2.0 API. We provide three Jupyter Notebooks as manuals with documentation of the API, tutorial to API modules, and a simple example of using the API. Relevant scripts for harmonising the original resources and releasing the UDer collections are available in the GitHub repository.
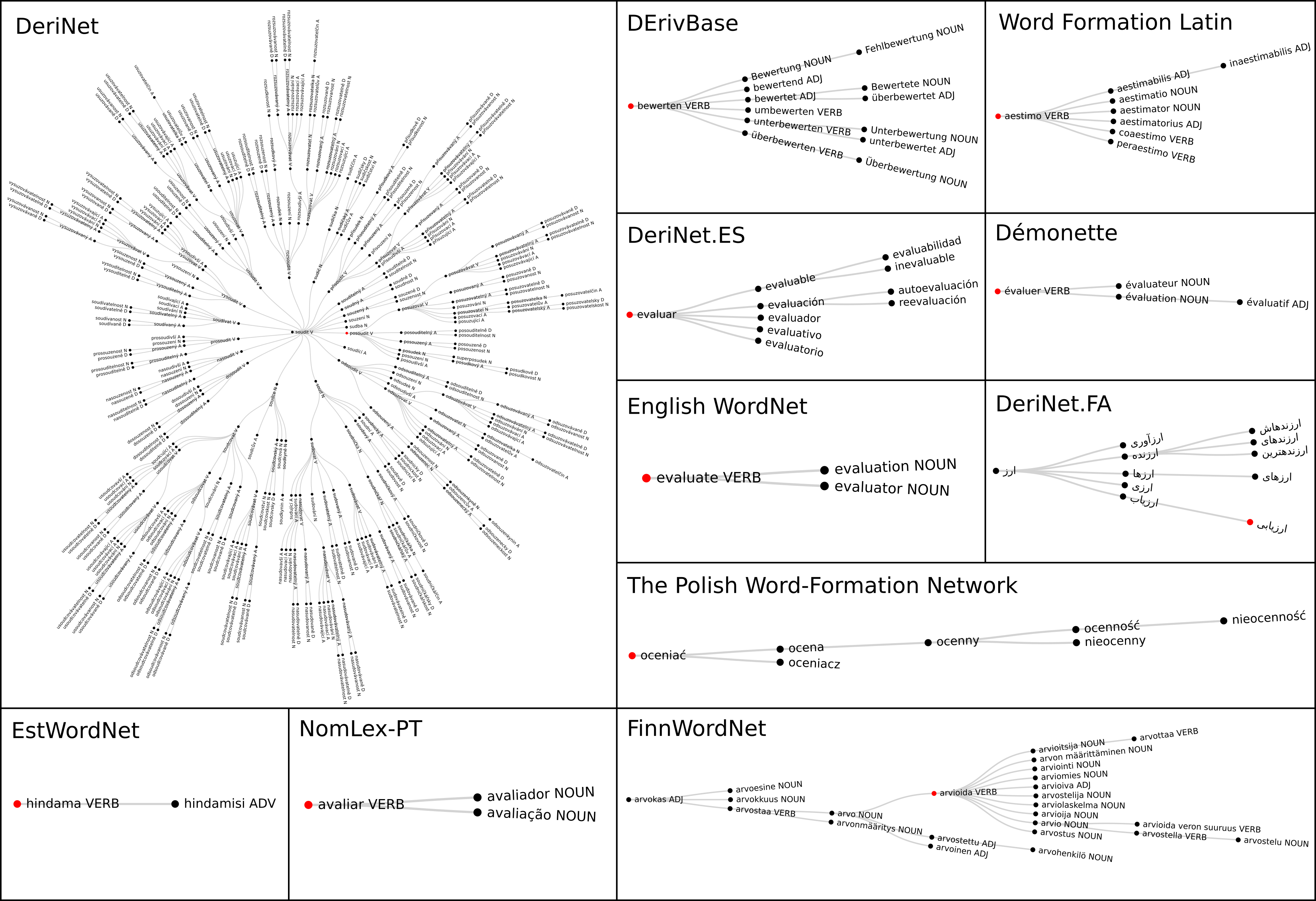
The current version
The current version of the collection is UDer 1.1. It contains 31 harmonized resources covering 21 languages (listed in the table below). UDer 1.1 is available in the LINDAT/CLARIAH CZ digital library (item: http://hdl.handle.net/11234/1-3247). The license for each of the harmonized resources included in the collection is specified in the appropriate language/resource directory.
| Resource | Language | Lexemes | Relations | Families | License |
|---|---|---|---|---|---|
| CatVar | English | 82,675 | 24,628 | 58,047 | OSL-1.1 |
| CroDeriV | Croatian | 5,093 | 4,948 | 145 | CC BY-NC-SA 3.0 |
| D-CELEX | Dutch | 125,611 | 11,150 | 114,461 | GPL-3.0 (for scripts) |
| Démonette | French | 22,060 | 13,808 | 8,252 | CC BY-NC-SA 3.0 |
| DeriNet | Czech | 1,039,012 | 835,738 | 203,274 | CC BY-NC-SA 3.0 |
| DeriNet.ES | Spanish | 151,173 | 42,825 | 108,348 | CC BY-NC-SA 3.0 |
| DeriNet.FA | Persian | 43,357 | 35,745 | 7,612 | CC BY-NC-SA 4.0 |
| DeriNet.RU | Russian | 337,632 | 164,725 | 172,907 | CC BY-NC-SA 4.0 |
| DerIvaTario | Italian | 8,267 | 1,783 | 6,484 | CC BY-SA 4.0 |
| DErivBase | German | 280,775 | 43,367 | 237,408 | CC BY-SA 3.0 |
| DerivBase.Hr | Croatian | 99,606 | 34,639 | 64,967 | CC BY-SA 3.0 |
| DerivBase.Ru | Russian | 270,473 | 136,449 | 136,449 | Apache 2.0 |
| E-CELEX | English | 52,447 | 9,319 | 43,128 | GPL-3.0 (for scripts) |
| EstWordNet | Estonian | 988 | 507 | 481 | CC BY-SA 3.0 |
| EtymWordNet-cat | Catalan | 7,496 | 4,568 | 2,928 | CC BY-SA 3.0 |
| EtymWordNet-ces | Czech | 7,633 | 5,237 | 2,396 | CC BY-SA 3.0 |
| EtymWordNet-gla | Gaelic | 7,524 | 5,013 | 2,511 | CC BY-SA 3.0 |
| EtymWordNet-pol | Polish | 27,797 | 24,876 | 2,921 | CC BY-SA 3.0 |
| EtymWordNet-por | Portuguese | 2,797 | 1,610 | 1,187 | CC BY-SA 3.0 |
| EtymWordNet-rus | Russian | 4,005 | 3,227 | 778 | CC BY-SA 3.0 |
| EtymWordNet-hbs | Serbo-Croatian | 8,033 | 6,303 | 1,730 | CC BY-SA 3.0 |
| EtymWordNet-swe | Swedish | 7,333 | 4,423 | 2,910 | CC BY-SA 3.0 |
| EtymWordNet-tur | Turkish | 7,774 | 5,837 | 1,937 | CC BY-SA 3.0 |
| FinnWordNet | Finnish | 20,035 | 11,890 | 8,145 | CC BY-SA 4.0 |
| G-CELEX | German | 51,728 | 13,301 | 38,427 | GPL-3.0 (for scripts) |
| GoldenCompoundAnalyses | Russian | 4,931 | 1,639 | 3,292 | CC BY-NC 4.0 |
| Nomlex-PT | Portuguese | 7,020 | 4,201 | 2,819 | CC BY-SA 4.0 |
| Sloleks | Slovenian | 48,054 | 29,121 | 18,933 | CC BY-NC-SA 4.0 |
| The Morpho-Semantic Database | English | 13,813 | 7,855 | 5,958 | CC BY-NC-SA 3.0 |
| The Polish WFN | Polish | 262,887 | 189,217 | 73,670 | CC BY-NC-SA 3.0 |
| Word Formation Latin | Latin | 36,258 | 32,625 | 3,633 | CC BY-NC-SA 4.0 |
Related publications
- Lukáš Kyjánek, et al. Constructing a Lexical Resource of Russian Derivational Morphology. In: Proceedings of the 13th Conference on Language Resources and Evaluation Conference (LREC). Marseille, 2022, pp. 2788-2797.
- Lukáš Kyjánek, Zdeněk Žabokrtský, Magda Ševčíková, Jonáš Vidra. 2020. Universal Derivations 1.0, A Growing Collection of Harmonised Word-Formation Resources. The Prague Bulletin of Mathematical Linguistics, 115:2, pp. 5-30. ISSN: 0032-6585.
- Lukáš Kyjánek. 2020. Harmonisation of Language Resources for Word-Formation of Multiple Languages. Master’s thesis, Charles University, Faculty of Mathematics and Physics. Unpublished thesis.
- Lukáš Kyjánek, Zdeněk Žabokrtský, Magda Ševčíková, Jonáš Vidra. 2019. Universal Derivations Kickoff: A Collection of Eleven Harmonized Derivational Resources for Eleven Languages. In Proceedings of the 2nd Workshop on Resources and Tools for Derivational Morphology. Prague: Charles University. ISBN: 978-80-88132-08-0.
- Jonáš Vidra, Zdeněk Žabokrtský, Magda Ševčíková, Lukáš Kyjánek. 2019. DeriNet 2.0: Towards an All-in-One Word-Formation Resource. In Proceedings of the 2nd Workshop on Resources and Tools for Derivational Morphology. Prague: Charles University. ISBN: 978-80-88132-08-0.
- Lukáš Kyjánek. 2018. Morphological Resources of Derivational Word-Formation Relations. Technical Report TR-2018-61. Prague: Faculty of Mathematics and Physics, Charles University.