


The Czech Academic Corpus 2.0 is a morphologically and syntactically annotated corpus of 650,000 words.
The Czech Academic Corpus (CAC) was created by a team from the Institute of the Czech Language, of the ASCR, led by Marie Těšitelová [11] from 1971 till 1985.[1]The original purpose of the corpus was to build a frequency dictionary of the Czech language and the original name of the corpus was “Korpus věcného stylu” (Practical corpus). The corpus has been morphologically and syntactically annotated manually. Independent from the CAC, an annotation of the Prague Dependency Treebank (PDT) was launched in 1996. The idea of transferring the internal format and annotation scheme of the CAC into the PDT emerged during the work on the PDT’s second version [16]. The main goal was to make the CAC and the PDT fully compatible and thus enable the integration of the CAC into the PDT. After converting the inner format and morphological annotation scheme, we have published the first version of the CAC (Vidová Hladká a kol., 2007). The second version presented here enriches the CAC 1.0 by adding the surface syntax annotation; in the terminology of the PDT we call this annotation an “analytical layer”.
While creating the CAC 1.0, the omitted words and numerical expressions were manually replaced by wildcard symbols (“#” and “?”) – these corrections and the reasons why those changes were deemed necessary are described in detail in the CAC 1.0 Guide (Vidová Hladká a kol., 2007). These wildcard symbols were not further processed during the phase of CAC 2.0’s creation.
The CAC 2.0 offers:
For linguists: Language material reflecting the real usage of the language,
For computational linguists: The tools and a considerable amount of data that could help amend applications working with natural language and are not feasible without morphological and syntactical text processing,
For TrEd annotation tool users: The possibility to use voice control for the tool,
For teachers and their students: An interesting didactic tool for practising Czech language morphology and syntax.
The CAC contains mostly unabridged articles taken from a wide range of media. These articles include newspapers, magazines, and transcripts of spoken language from radio and TV programs covering administration, journalism and scientific fields. The texts are taken from the 70s and 80s of the 20th century and thus, the selection of texts is influenced by the political and cultural climate of this time period. A complete list of resources can be found in Appendix A.
We cannot call a corpus “annotated” without specifying what kind of annotation the corpus contains. In other words, from the linguistic theory viewpoint, one must first characterise the so-called layers of annotation. The annotation of the CAC 2.0 covers two layers: morphological and analytical. To be absolutely accurate, we must add that we also operate on another layer: the layer of words. In fact, the word layer is not a layer for annotation as it consists of the original text divided into word tokens (words, numbers written in digits and punctuation). However, for the sake of convenience, we will refer to the word layer as an annotation layer. Henceforth, we will refer to the word, morphological and analytical layer as the w-layer, m-layer and a-layer, respectively.
A morphological layer of annotation provides the word tokens with further data (annotation), which characterises the morphological properties of the word tokens (as apparent in the lemma which is the canonical form of a lexeme), the part of speech, and morphological categories (case, number, tense, person, etc.). Formally, part of speech classes combine together with values of morphological categories to represent morphological tags (or, simply, tags). In the CAC 2.0, tags are designed according to the PDT as strings of definite length (15 positions) where each position corresponds to a single category. Appendix C contains the complete list of these morphological positional tags and their detailed description.
Example: The word form Prahu (a form of “Prague”) is analysed as an affirmative (11th position) noun (1st and 2nd position), feminine (3rd position), singular (4th position), and accusative (5th position). All of the other positions are correctly filled with the symbol “-” that represents the irrelevance of the morphological category towards the part of speech. For example, one does not determine a person and tense with nouns (8th and 9th position).
Table 2.1. Examples of lemmas and tags of particular word forms
| Word token | Lemma | Tag | Description |
|---|---|---|---|
| Prahu | Praha | NNFS4-----A---- | Noun, feminine, singular, accusative, affirmative |
| 123 | 123 | C=------------- | Digit token |
| ) | ) | Z:------------- | Punctuation mark (right parenthesis) |
An a-layer annotation assigns each word unit the corresponding data characterising the syntactical features of the unit and therefore its relation to the other sentence elements along with its sentence function. Formally, the sentence relations are represented by a dependency tree. The word unit functions in the sentence are represented by so-called analytic functions, which are listed and described in Appendix D.
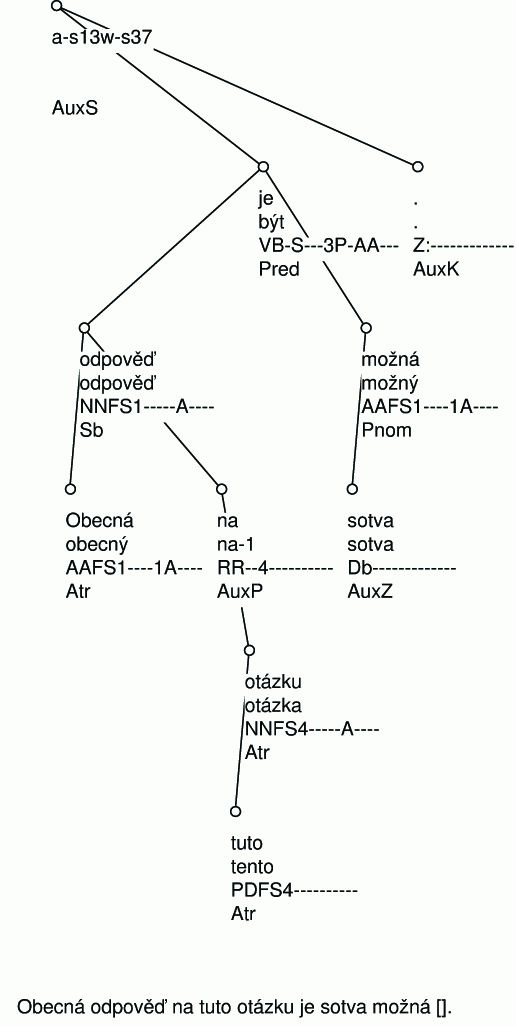
Example: Figure 2.1 shows the syntactical annotation of the sentence Obecná odpověď na tuto otázku je sotva možná.(Lit.: A general response to this question is hardly possible.) Each word unit (word, number, punctuation mark) is represented by a single node in the resulting tree. Note that due to technical reasons each tree is rooted by one extra node – the tree in our example therefore consists of 9 nodes. The annotation approach builds on the tradition of the Prague linguistic school, where the predicate (usually verb) is understood to be the centre of the sentence. Therefore the predicate is placed as a direct daughter of the root. The final punctuation is also placed as a daughter of the root node. Two constituents of the sentence are dependent on the predicate – odpověď (answer) and možná (possible). Please note that each node in the tree is annotated with the word form, lemma, morphological tag and analytic function. Looking at the node representing the word odpověď (answer), we can see its form is a feminine noun in nominative singular and that this unit stands in the role of subject of the sentence, which is expressed by the analytic function Subj.
The conception of the main internal format of the CAC 2.0 (in PML format – see Chapter 3.2.1) treats the annotation layers separately where each layer of annotation in the document corresponds to one file. (In the case of the CSTS format, all layers of annotation are contained in one file.) This relationship in the CAC 2.0 means that there are three instances (files) for every document, one for the w-layer, one for the m-layer and a third one for the a-layer. However, the distinction between layers does not restrict interconnection between groups for particular layers of annotation. In fact, the opposite is true as will be demonstrated later in this section.
The word layer does not reflect the segmentation of the text into sentences; this segmentation occurs on the m-layer. This means that unlike the w-layer, the m-layer contains final punctuation. Additionally, the number of word tokens in both layers may differ. The differences originate from the concatenation of the incorrectly split word into one word, or reversely, from the division of incorrectly connected words into more units. The correctly written text should be contained in the m-layer.
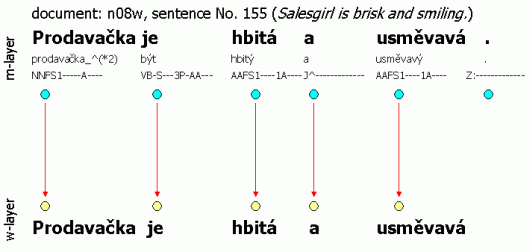
Example: The three following figures illustrate the w-layer and m-layer interconnection. Also the interconnection of the files in the sense of the number of word units is captured and denoted by arrows. All three examples were chosen from the CAC 2.0 deliberately so that the user can directly view the instances; the name of the document and number of the sentence is provided for every sentence. Figure 2.2 serves to illustrate the 1:1 ratio of the layers. The layers do not differ except for the final punctuation. Figure 2.3 exemplifies the situation where a word token is inserted into the text – the year information was clearly missing. Since it is almost impossible for the corrector to add the missing year, the symbol “#” is used as this symbol has no counterpart on the w-layer. In contrast, Figure 2.4 illustrates the situation where more m-layer units corresponds to the same w-layer unit – the word unit pedagogicko-psychologické (E: “psychological-pedagogical”) has been divided into three separate units.
Figure 2.2. Technical interconnection of the w-layer and m-layer: No changes other than the final-sentence punctuation
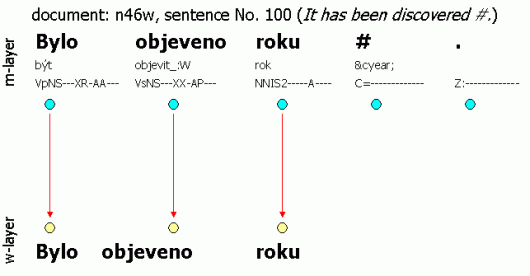
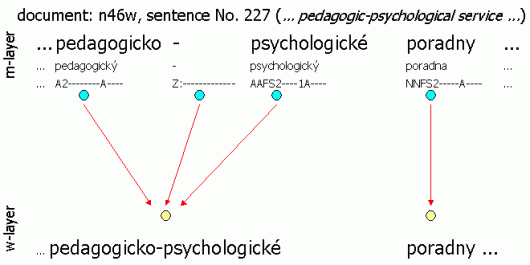
The interconnection between the a-layer and m-layer means that each m-layer word unit corresponds exactly to one node of the dependency tree on the a-layer, and vice versa. The only exception is the technical root, which has no counterpart on the m-layer. Figure 2.1 illustrates the interconnection described above.
The project of the Czech Academic Corpus comes down to us the centuries, as we have described in detail in the article (Hladká, Králík, 2006). We will not address the long journey of the CAC leading to its first version published here. The CAC 1.0 Guide (Vidová Hladká a kol., 2007) contains all of that information. Here, we would like to summarise the process of building up the layers of the second version of the CAC.
The data preparation of the CAC 2.0 involved further semi-automatic checks of the morphological annotation; extensive semi-automatic checks have been already run during the CAC 1.0 preparations. These checks have been motivated by the similar processes during the building of the Prague Dependency Treebank 2.0. Detailed descriptions can be found in the CAC 1.0 Guide.
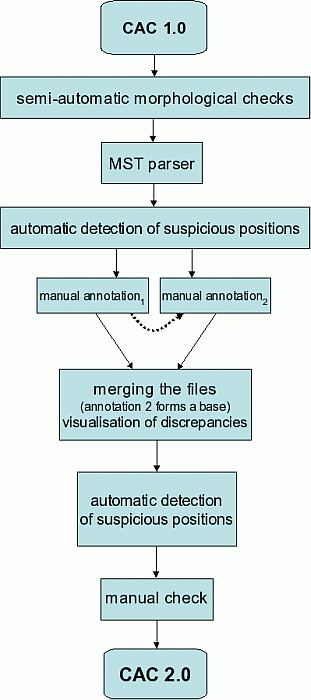
The automatic scripts verifying the data went through the corpus and marked suspicious positions; the annotators then checked the marked sentences and corrected them if needed. The main point of this work was to ensure that the morphological categories of the original tag in the CAC and of the positional morphological tag in the CAC 1.0 matched. For example, as for the noun’s case category, the scripts have marked 1,258 suspicious tags; the annotator found 332 of them to be wrong and corrected them. There have been 177 suspicious instances of adjective’s case and the annotator corrected 41 of them.
All of the verifications conformed to the rules of the PDT morphological annotation [17].
The analytical annotation of the corpus has raised the question of how to map the original annotation to the Prague Dependency Treebank style of annotations. Based on the experiences from the morphological annotation, we have split this question into three sub-questions: Automatically? Semi-automatically? Manually? The article by Ribarov, Bémová, Hladká, 2006 describes our search for the answers in detail. The authors have reached a possibly surprising conclusion: They have decided to ignore the original annotation completely and process the manually morphologically annotated texts of the CAC 1.0 by an automatic procedure (parser). This procedure assigns a dependency tree to each sentence and an analytical function to each node. These automatically assigned trees have been manually verified (annotated). The maximum spanning tree parser (MST parser) described below has been used. For details see 3.3.5.
Professional linguists conducted the analytic annotation of Prague Dependency Corpus. Two annotators from the PDT group became the main arbiter for our project. Among the other annotators were one Czech student of philology and three Slovak annotators experienced in annotating the Slovak National Corpus [21] under the leadership of Prague linguists trained in the PDT annotations. Therefore the CAC annotation had two phases: annotation, arbitration. In the beginning, each document was annotated by two annotators, the annotators worked in parallel. The two annotations were automatically compared and the result proceeded to the arbiter. As soon as the arbiter agreed that the work of the annotators was fluent enough, each document was annotated only once. During the second stage of annotations, the arbiter reviewed the complete documents, not only the differences in parallel annotations. The documents were then processed by the automatic scripts verifying the different phenomena between the annotation stages.
The automatic scripts verification was inspired by the scripts used in the PDT 2.0 preparations, similarly to the morphological annotations. The scripts marked suspicious positions in the data. The relations of the nodes on the analytical layer have been checked for their grammatical permissibility, and the possible combinations of the morphological tag and analytical function of each node has been checked. In the next stage the marked suspicious positions were highlighted and a brief description of the possible problem was displayed on the annotator’s screen. The problem could occur either in the morphological or in the analytical annotation.
All of the verifications conformed to the rules of PDT morphological annotation [18].
As an example of the analytically-morphological verifying script, we will describe the script as it checks the annotation of the word form se. The script checked the following condition for each node for the word form “se”: Each node for the word form se is either a reflexive pronoun with the analytical function AuxT or AuxR, or it is a vocalised preposition with the analytical function AuxP. Other scripts reviewed the agreement of morphological tag categories or the permissibility of the combination of the governing and dependent nodes’ analytical functions (e.g. the preposition and its dependent noun or the permissibility of the position of a node marked as subject Subj).
Figure 2.5 illustrates operations on the data since the CAC 1.0 release up until the CAC 2.0 release.
[1] This text contains both bibliographic references (e.g. Vidová Hladká a kol., 2007) and Internet references in the form of a number in brackets (e.g. [1]) referring to the list of internet URLs in Appendix E).