600.465 Introduction to NLP (Fall 2000)
Assignment #1
Due: Sep 27 2pm
Exploring Entropy and Language Modeling
TA: Gideon S. Mann
1. The Shannon Game
What is it about
In this experiment you will attempt to measure the entropy of English text (i.e. the number of bits per character needed to encode it) through a method designed by Claude E. Shannon. An application has been prepared to make this a bit of fun, too: this application will calculate the entropy of the sequence of numbers S generated as you try and guess the next letter given a sequence of N letters that come immediately before it in a chosen text. The i-th element of S is just the number of guesses it took you to correctly deduce the next letter on the ith turn. The number N is referred to as the history length.How to play:
Logon to hops.cs.jhu.edu or barley.cs.jhu.edu. Make sure you have the DISPLAY environment variable set correctly. Do
cd ~hajic/cs465
./Shannon.tcl
The application will allow you to choose a text from a list of preformatted ones. Set the history length to 2. Choose to have the computer play along. Start the game. There is documentation on using this application available through the help menu.
The computer makes his guesses in an analogous way to the Markov models with the order equal to the history length.
The Task
Run through at least 30 turns and record your entropy and that of the computer. Repeat this for history lengths of 3, 4 and 5 on the same text. Finally set the history length to 20, choose the computer NOT to play along (it would refuse anyway) and go through at least 30 turns and record your entropy. Graph and explain your results. How do you think the computer would fare at a history length of 20?
Here is an example of an acceptable fulfilment of the Task #1. There are also some hints what tools to use for generating such a presentation of your homework. You are even free to use it as a template, but the results must be yours of course :-). The other parts of this homework and of future homeworks should be presented in a similar way.
2. Entropy of a Text
In this experiment, you will determine the conditional entropy of the word distribution in a text given the previous word. To do this, you will first have to compute P(i,j), which is the probability that at any position in the text you will find the word i followed immediately by the word j, and P(j|i), which is the probability that if word i occurs in the text then word j will follow. Given these probabilities, the conditional entropy of the word distribution in a text given the previous word can then be computed as:
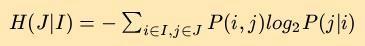
The perplexity is then computed simply as
Compute this conditional entropy and perplexity for
barley:~hajic/cs465/TEXTEN1.txt
This file has every word on a separate line. (Punctuation is considered a word, as in many other cases.) The i,j above will also span sentence boundaries, where i is the last word of one sentence and j is the first word of the following sentence (but obviously, there will be a fullstop at the end of most sentences).
Next, you will mess up the text and measure how this alters the conditional entropy. For every character in the text, mess it up with a likelihood of 10%. If a character is chosen to be messed up, map it into a randomly chosen character from the set of characters that appear in the text. Since there is some randomness to the outcome of the experiment, run the experiment 10 times, each time measuring the conditional entropy of the resulting text, and give the min, max, and average entropy from these experiments. Be sure to use srand to reset the random number generator seed each time you run it. Also, be sure each time you are messing up the original text, and not a previously messed up text. Do the same experiment for mess up likelihoods of 5%, 1%, .1%, .01%, and .001%.
Next, for every word in the text, mess it up with a likelihood of 10%. If a word is chosen to be messed up, map it into a randomly chosen word from the set of words that appear in the text. Again run the experiment 10 times, each time measuring the conditional entropy of the resulting text, and give the min, max, and average entropy from these experiments. Do the same experiment for mess up likelihoods of 5%, 1%, .1%, .01%, and .001%.
Now do exactly the same for the file
barley:~hajic/cs465/TEXTCZ1.txt
which contains a similar amount of text in an unknown language (just FYI, that's Czech*)
Tabulate, graph and explain your results. Also try to explain the differences between the two languages. To substantiate your explanations, you might want to tabulate also the basic characteristics of the two texts, such as the word count, number of characters (total, per word), the frequency of the most frequent words, the number of words with frequency 1, etc.
Attach your source code commented in such a way that it is sufficient to read the comments to understand what you have done and how you have done it.
Now assume two languages, L1 and L2 do not share any vocabulary items, and that the conditional entropy as described above of a text T1 in language L1 is E and that the conditional entropy of a text T2 in language L2 is also E. Now make a new text by appending T2 to the end of T1. Will the conditional entropy of this new text be greater than, equal to, or less than E? Explain. [This is a paper-and-pencil exercise of course!]
3. Cross-Entropy and Language Modeling
This task will show you the importance of smoothing for language modeling, and in certain detail it lets you feel its effects.
First, you will have to prepare data: take the same texts as in the previous task, i.e.
barley:~hajic/cs465/TEXTEN1.txt and barley:~hajic/cs465/TEXTCZ1.txt
Prepare 3 datasets out of each: strip off the last 20,000 words and call them the Test Data, then take off the last 40,000 words from what remains, and call them the Heldout Data, and call the remaining data the Training Data.
Here comes the coding: extract word counts from the training data so that you are ready to compute unigram-, bigram- and trigram-based probabilities from them; compute also the uniform probability based on the vocabulary size. Remember (T being the text size, and V the vocabulary size, i.e. the number of types - different word forms found in the training text):
p0(wi) = 1 / V
p1(wi) = c1(wi) / T
p2(wi|wi-1)
= c2(wi-1,wi) /
c1(wi-1)
p3(wi|wi-2,wi-1)
= c3(wi-2,wi-1,wi) /
c2(wi-2,wi-1)
Be careful; remember how to handle correctly the beginning and end of the training data with respect to bigram and trigram counts.
Now compute the four smoothing parameters (i.e. "coefficients", "weights", "lambdas", "interpolation parameters" or whatever, for the trigram, bigram, unigram and uniform distributions) from the heldout data using the EM algorithm. [Then do the same using the training data again: what smoothing coefficients have you got? After answering this question, throw them away!] Remember, the smoothed model has the following form:
ps(wi|wi-2,wi-1) = l0p0(wi) + l1p1(wi) + l2p2(wi|wi-1) + l3p3(wi|wi-2,wi-1),
where
l0 + l1 + l2 + l3 = 1.
And finally, compute the cross-entropy of the test data using your newly built, smoothed language model. Now tweak the smoothing parameters in the following way: add 10%, 20%, 30%, ..., 90%, 95% and 99% of the difference between the trigram smoothing parameter and 1.0 to its value, discounting at the same the remaining three parameters proportionally (remember, they have to sum up to 1.0!!). Then set the trigram smoothing parameter to 90%, 80%, 70%, ... 10%, 0% of its value, boosting proportionally the other three parameters, again to sum up to one. Compute the cross-entropy on the test data for all these 22 cases (original + 11 trigram parameter increase + 10 trigram smoothing parameter decrease). Tabulate, graph and explain what you have got. Also, try to explain the differences between the two languages based on similar statistics as in the Task No. 2, plus the "coverage" graph (defined as the percentage of words in the test data which have been seen in the training data).
Attach your source code commented in such a way that it is sufficient to read the comments to understand what you have done and how you have done it.
* If you want to see the accents correctly, select ISO Latin 2 coding (charset=iso-8859-2) for viewing, but your programs obviously will (should) work in any case (supposing they are 8-bit clean). For those linguistically minded & wishing to learn more about the language, look here. We will be using texts in this language often, albeit you will never be required to learn it.)