


V této části nabízíme popis adresářové struktury CD, a to až do druhé, příp. třetí úrovně zanoření, viz 3.1. Pokud v textu
odkazujeme na obsah CD, který je zanořen hlouběji, explicitně na to upozorňujeme uvedením úplné cesty.
Podrobněji jsou popsány obsahy adresářů s daty (data/), s nástroji
(tools/) a s bonusovým materiálem (bonus-tracks/).
Tabulka 3.1. Adresářová struktura CD-ROM ČAK 1.0
index.html |
# průvodce ČAK 1.0 česky (html formát) | |||
index-en.html |
# průvodce ČAK 1.0 anglicky (html formát) | |||
Install-on-Linux.pl |
# instalační skript pro Linux (anglicky) | |||
Install-on-Windows.exe |
# instalační program pro MS Windows (anglicky) | |||
Instaluj-na-Linuxu.pl |
# instalační skript pro Linux (česky) | |||
Instaluj-na-Windows.exe |
# instalační program pro MS Windows (česky) | |||
bonus-tracks/ |
# bonusový materiál | |||
|
# elektronická cvičebnice češtiny | |||
data/ |
||||
|
# ČAK 1.0 (soubory [ans][0-9][0-9][sw].[mw]) |
|||
|
# PML schémata | |||
doc |
||||
|
# průvodce ČAK 1.0 česky a anglicky (pdf formát) | |||
tools/ |
# nástroje | |||
|
# korpusový manažer | |||
|
# anotační morfologický editor | |||
|
# morfologické zpracování českých textů | |||
|
# skript pro spouštění morf. analýzy a/nebo tagování | |||
|
Organizace ČAK 1.0 do souborů, jejichž jména podléhají jisté konvenci, a samotná vnitřní reprezentace souborů jsou předmětem následující sekce.
Vnitřním formátem ČAK 1.0 je formát nazvaný Prague Markup Language (PML), založený na XML a navržený pro bohatou reprezentaci lingvistické anotace textů. Každé zvolené rovině anotace odpovídá jeden samostatný soubor. Návrh PML probíhal souběžně s tektogramatickou anotací PZK 2.0. Následující text obsahuje stručný přehled hlavních vlastností PML, zatímco podrobné informace jsou publikovány v technické zprávě (Pajas, Štěpánek, 2005)
V PML se mohou jednotlivé oddělené roviny anotace překrývat a mohou být konzistentně propojeny
jak mezi sebou, tak i s dalšími zdroji dat.
Každá rovina anotace je popsána v souboru
PML schéma, který je jakousi formalizací abstraktního
anotačního schématu pro tu kterou rovinu anotace.
PML schéma popisuje, které elementy se na dané rovině vyskytují,
jak jsou spojovány, vnořovány a strukturovány, hodnoty jakého typu se v nich
mohou vyskytovat a jakou roli hrají v anotačním schématu
(tato informace o tzv. PML-roli
může být využívána i aplikacemi ke správnému určení způsobu zobrazení PML dat uživateli).
Z PML schématu mohou být automaticky generována další schémata, jako je
Relax NG, díky čemuž může být konzistence dat ověřena pomocí běžných nástrojů pro XML.
Obě verze schémat jsou k dispozici v adresáři data/schemas/.
Pro ilustraci uvádíme v tabulce 3.2 část PML schématu w-roviny dat
ČAK (data/schemas/wdata_schema.xml), která specifikuje, že
odstavec (typ para,
v případě ČAK 1.0 vždy celý dokument) sestává z posloupnosti elementů typu w-node.type;
tento typ je níže definován jako struktura obsahující mimo jiné dva povinné elementy: id (jednoznačný identifikátor
s rolí #ID) a token (slovní jednotku):
Tabulka 3.2. PML schéma w-roviny ČAK 1.0
|
<type name="w-para.type"> <sequence> <... <element name="w" type="w-node.type"/> </sequence> </type> <type name="w-node.type"> <structure name="w-node"> <member as_attribute="1" name="id" role="#ID" required="1"> <cdata format="ID"/></member> <member name="token" required="1"><cdata format="any"/> </member> <member name="no_space_after" type="bool.type"/> </structure> </type> ... |
Každý PML soubor začíná hlavičkou odkazující na PML schéma souboru.
V hlavičce jsou uvedeny všechny externí zdroje, na které je z tohoto souboru odkazováno,
spolu s několika dalšími informacemi, potřebnými pro správné vyhodnocení odkazů.
Zbytek souboru obsahuje vlastní anotaci. Část hlavičky souboru m-roviny (a01w.m), kde se odkazuje
na PML-schéma tohoto souboru (mdata_schema.xml) a na příslušný soubor
w-roviny (a01w.w), uvádíme jako příklad v tabulce 3.3:
Tabulka 3.3. Část hlavičky souboru a01w.m
| <head>
<schema href="mdata_schema.xml" /> <references> <reffile id="w" href="a01w.w" name="wdata" /> </references> </head> ... |
Anotace je vyjádřena pomocí XML elementů a atributů, pojmenovaných
a použitých v souladu s příslušným PML schématem. Pro ilustraci uvádíme v tabulce 3.4 příklad anotace
začátku věty a prvního slova věty na m-rovině souboru a01w.m. Otvírací značka elementu
s obsahuje
identifikátor celé věty, stejně tak otvírací značka elementu m
obsahuje identifikátor dané anotace odpovídající slovní jednotky w-roviny, na kterou se odkazuje z elementu w.rf.
Další elementy obsahují formu (form), morfologickou značku (tag)
a lemma (lemma) a element src.rf udává
zdroj anotace, v tomto případě ruční:
Tabulka 3.4. Ukázka anotace souboru a01w.m
| <s id="m-a01w-s1">
<m id="m-a01w-s1W1"> <w.rf>w#w-a01w-s1W1</w.rf> <form>Federální</form> <tag> <lemma>federální</lemma> <src.rf>manual</src.rf> </m> ... |
XML elementy všech souborů patří do vyhrazeného jmenného prostoru
http://ufal.mff.cuni.cz/pdt/pml/ (pouze název jmenného prostoru, nejedná se o smysluplný odkaz).
Formát PML poskytuje jednotnou reprezentaci většiny běžných anotačních konstrukcí,
jako jsou struktury atribut-hodnota, seznam alternativních hodnot určitého typu
(atomického nebo dále strukturovaného), odkazy v rámci PML souboru, odkazy mezi různými PML soubory
(v ČAK 1.0 použité k odkazům mezi rovinami) nebo do dalších externích zdrojů typu XML.
Každý datový soubor ČAK 1.0 odpovídá jednomu dokumentu anotovanému na jedné rovině anotace. První znak jména souboru indikuje
styl textu: n označuje novinové články (publicistiku),
s označuje vědecké texty (odborný styl), a označuje texty administrativní. Následuje
dvoumístné pořadové číslo dokumentu v rámci skupiny dokumentů jednoho stylu; písmeno za číslem udává, zda jde o původně psaný text
(písmeno w) nebo o přepis mluvené řeči, tzv. mluvený text (písmeno s). Jména souborů jsou také
součástí identifikátorů vět a prvků vět, obsažených v těchto souborech, např. <m id="m-a01w-s1W1">
v tabulce 3.4. V příloze A jsou uvedena jména souborů pro jednotlivé dokumenty.
Příklad: Soubory se jménem podle šablony a[0-9][0-9]s* obsahují přepisy mluvené
řeči s administrativním obsahem.
Přípona souboru vyjadřuje rovinu anotace dokumentu (.w označuje w-rovinu a .m označuje m-rovinu).
Mluvíme potom o w-souborech a m-souborech. Ke každému m-souboru existuje právě jeden w-soubor. Z každého m-souboru vedou odkazy
do příslušného w-souboru (viz výše). Z tohoto důvodu by soubory neměly být přejmenovány. Z w-souboru do m-souboru odkazy nevedou.
Příklad: s17w.m označuje soubor obsahující anotace na m-rovině
odborného psaného dokumentu. Ze souboru vedou odkazy do souboru s17w.w.
ČAK 1.0 sestává ze 180 ručně anotovaných textových dokumentů, obsahujících celkem 31 707 vět s 652 132 slovními jednotkami (tyto údaje jako i všechny ostatní jsou počítány z m-souborů). Slovních jednotek bez interpunkce je 570 761. Slovních jednotek bez interpunkce a bez čísel zapsaných číslicemi je 565 928. V tabulce 3.5 jsou uvedeny velikosti jednotlivých částí dat rozdělených podle stylu a podle formy.
Tabulka 3.5. Velikost jednotlivých částí ČAK 1.0 podle stylu a formy
| styl | forma | počet souborů | počet vět | počet slovních jednotek | počet slovních jednotek bez interpunkce | počet slovních jednotek bez interpunkce a bez čísel zapsaných číslicemi |
|---|---|---|---|---|---|---|
| publicistický | psaná | 52 | 10 234 | 189 435 | 165 469 | 163 700 |
| publicistický | mluvená | 8 | 1 433 | 28 737 | 24 864 | 24 859 |
| odborný | psaná | 68 | 11 113 | 245 175 | 216 281 | 214 132 |
| odborný | mluvená | 32 | 4 576 | 115 853 | 100 281 | 100 272 |
| administrativní | psaná | 16 | 3 362 | 58 697 | 51 431 | 50 530 |
| administrativní | mluvená | 4 | 989 | 14 235 | 12 435 | 12 435 |
| celkem | psaná | 136 | 24 709 | 493 307 | 433 181 | 428 362 |
| celkem | mluvená | 44 | 6 998 | 158 825 | 137 580 | 137 566 |
| celkem | psaná a mluvená | 180 | 31 707 | 652 132 | 570 761 | 565 928 |
Pro úplnost dodáváme, že každý zveřejněný experiment provedený na datech ČAK 1.0 by měl obsahovat informaci o tom, jaká část dat byla pro jaký účel v experimentu použita.
Souhrnně konstatujeme, že anotace ČAK 1.0 je rozdělena do dvou rovin,
a to do roviny slovní (w-rovina) a morfologické (m-rovina). Každá z těchto rovin má vlastní PML schéma
(v adresáři data/schemas/
soubory wdata_schema.xml, mdata_schema.xml). Adresář data/pml/
obsahuje celkem 360 souborů, a to 180 w-souborů a 180 m-souborů.
Grafický nástroj Bonito ulehčuje uživatelům práci s jazykovými korpusy, zejména při vyhledávání a při základních statistických
výpočtech nad vyhledanými daty. Bonito je nadstavbou korpusového manažeru Manatee, který provádí nejrůznější operace nad korpusovými
daty. Podrobná dokumentace k nástroji Bonito je součástí nástroje samotného a vyvolá se z hlavního
menu Nápověda.
Hlavní obrazovku Bonito ilustruje obrázek 3.1. Základní ovládání nástroje ukážeme na konkrétních příkladech.
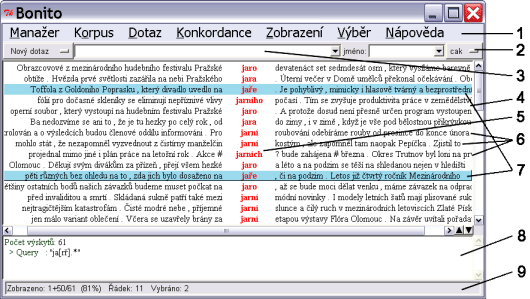
Vysvětlivky k obrázku 3.1
1 Hlavní menu
2 Tlačítko pro výběr korpusu
3 Dotazovací řádek
4 Hlavní okno pro zobrazení výsledků dotazu
5 Sloupec s výskyty odpovídajícími dotazu
6 Konkordanční řádky
7 Vybrané konkordanční řádky
8 Vedlejší okno pro zobrazení historie dotazu a širšího kontextu
9 Stavový řádek
Uživatele často zajímá, v jakých kontextech se slova v korpusu vyskytují. Například ho může
zajímat, v jakých kontextech se vyskytuje slovo jaro. Zadáním tohoto slova do
okénka "3" (dotazovacího řádku) a stiskem klávesy Enter se odešle dotaz a vzápětí se odpověď
zobrazí v hlavním okně "4" ve formě tzv. konkordancí, tedy výskytů zadaného slova v
kontextech tak, jak se nachází v celém korpusu. Zobrazeným řádkům říkáme konkordance nebo také konkordanční řádky ("6").
Jako dotaz může sloužit i jednoduchý regulární výraz. Například všechny tvary slova jaro lze získat zadáním
regulárního výrazu ja[rř].* (viz obrázek 3.1). Uvedený dotaz sice
vyhledá všechny tvary, které
požadujeme, ale může se stát a v tomto případě se stane, že vyhledá i něco nežádoucího. Třeba tvary přídavného
jména jarní nebo i podstatného jména jarmark. Není-li výsledek příliš rozsáhlý a je-li nežádoucích konkordancí málo, můžeme je vybrat kliknutím levého tlačítka myši a poté vymazat pomocí příkazu Smazání vybraných z menu Konkordance (Konkordance | Smazání vybraných). Také lze napřed výběr invertovat, tj. zaměnit vybrané řádky za nevybrané a naopak (Výběr | Inverze), a teprve potom invertovaný výběr smazat.
Lepší je ale buď upravit regulární výraz tak, aby výsledkem byly jenom tvary, které uživatel chce (např. ja(ro|ra|ře|ru|rem|r|rech|ry)), což může být zbytečně složité, nebo výsledek zúžit pomocí volby
P filtr (pozitivní filtr) či N filtr (negativní filtr). Filtry zvolíme kliknutím na tlačítko Nový dotaz a výběrem příslušného filtru. Jestliže se např. do negativního filtru zapíše dotaz jarn.+, odstraní se
z vyhledaných konkordančních řádků všechny výskyty odpovídající uvedenému regulárnímu výrazu, tedy v našem případě tvary
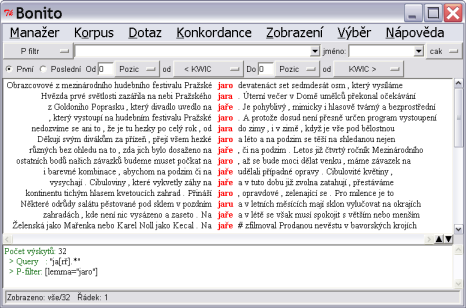
slova jarní. Lepším řešením je P filtr, do kterého zapíšeme dotaz
lemma=“jaro“. Tímto způsobem omezíme vyhledaný výsledek jen na ty výskyty, u nichž se atribut lemma rovná řetězci "jaro" - viz obrázek 3.2. Na stejném obrázku si všimněte historie dotazu, která se zapisuje do spodního okna "8".
Samozřejmě jsme mohli dotaz lemma=“jaro“ zadat hned na začátku. Výsledek by se ale od právě popsaného postupu lišil. Dosud jsme totiž vyhledávali jen tvary lemmatu jaro začínající malým písmenem. Dotaz na lemma vyhledá všechny možné zápisy tvarů lemmatu, včetně těch, které obsahují velké písmeno, např. na začátku věty.
Jak je zřejmé z dosud uvedených příkladů, je možné formulovat i složité dotazy a kombinovat hodnoty všech atributů, které jsou v korpusu definovány. O které atributy se jedná, zjistíme výběrem položky Souhrnné informace v menu Korpus (viz
obrázek 3.3).

V případě korpusu ČAK 1.0 jsou to následující tři atributy: slovo, lemma a morfologická značka neboli tag.
Implicitním atributem, který si však může
uživatel sám změnit, je atribut slovo. Proto stačilo v případě dosavadních příkladů zapsat do dotazovacího řádku pouze slovo jaro, aniž by se specifikovalo, o který atribut se jedná.
K vyhledání je možné použít i kombinaci atributů. Následující dotaz [lemma=”jaro” & tag=”NNN.6.+“ & word=“j.+“] najde
všechny výskyty lemmatu jaro, které se vyskytují v 6. pádě (jednotného nebo i množného čísla, protože ve značce je na pozici čísla tečka) a začínají malým písmenem - dotaz na lemma totiž vyhledá i výskyty daného lemmatu na začátku věty, což se nám původním dotazem, kdy jsme hledali slovo, ne lemma, nepodařilo.
Dotazy je třeba vytvářet velmi pečlivě. Vynechání hranatých závorek, uvozovek, přidání mezer, to vše může způsobit, že nenajdete to, co hledáte.
Pro názornější a bezchybné vytváření dotazů slouží grafický editor dotazů, který vyvoláme pomocí Dotaz | Grafické vytváření. Rychlejší je ale zadávání dotazu přímo do dotazovacího řádku.
Vyhledávat lze i více slov najednou. Stačí je zapsat jako nový dotaz. Jednotlivá slova je třeba v dotazu oddělit mezerami (viz obrázek 3.4). Pozor při
vyhledávání nealfanumerických znaků, které mají svůj význam pro regulární výrazy. Jedná se především o otazník a tečku. Chcete-li nalézt skutečně znak ?, který v korpusu ČAK 1.0 zastupuje vynechané slovo, je třeba zapsat do dotazovacího řádku \?. Podobně pro tečku \..
Zadáním samotné tečky by se vyhledaly všechny pozice korpusu, na nichž je jediný znak (tečky mezi nimi budou také).
Dvojitým kliknutím na konkordanční řádek se ve spodním okně zobrazí širší kontext (viz obrázek 3.4). Zde je možné kontext rozšiřovat směrem vpřed či vzad pomocí šipky nahoru nebo dolů (napřed je třeba do spodního okna kliknout levým tlačítkem myši).
obrázek 3.3.
Výběr atributů se provede pomocí Zobrazení | Atributy. Navíc lze u každé řádky zobrazit název zdrojového textu, ze
kterého konkordance pochází (Zobrazení | Reference).
Pomocí Zobrazení | Kontext lze nastavit velikost kontextu – tzn. kolik slov, znaků či vět má být zobrazeno okolo každého nalezeného výskytu. Položka Zobrazení | Rozsah zase umožňuje automatický výběr jen
určitého počtu řádků. To je užitečné zejména pro výsledky obsahující mnoho řádků, které je náročné projít ručně. Nejčastěji se asi použije zvolení
náhodného vzorku dat.
Konkordance je možné také třídit, a to jednak podle samotného nalezeného slovního tvaru, jednak podle slov vyskytujících se v levém či pravém
kontextu (Konkordance | Jednoduché třídění). Třídění může být i poměrně složité podle více kritérií
(Konkordance | Obecné třídění). Po zvolení uvedených funkcí se objeví okna, do nichž je třeba vyplnit
příslušné parametry pro třídění.
Výsledek jakkoli upraveného, promazaného a setříděného dotazu v hlavním okně je možné uložit do souboru pro pozdější použití (Konkordance | Uložení).
Nakonec se zmíníme o užitečných statistických funkcích, které jsou přístupné přes menu Konkordance | Statistiky.
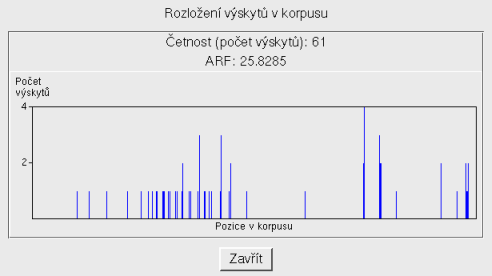
Položka Rozložení zobrazí nové okno s obrázkem znázorňujícím rozložení vyhledaných konkordancí v rámci celého
korpusu (viz obrázek 3.5). Z obrázku je na první pohled vidět, zda jsou výskyty rozloženy rovnoměrně či nikoliv. V okně se zobrazí i číslo vyjadřující
průměrnou redukovanou četnost (Savický, Hlaváčová, 2002), což je objektivnější vyjádření (ne)rovnoměrnosti rozložení výskytů.
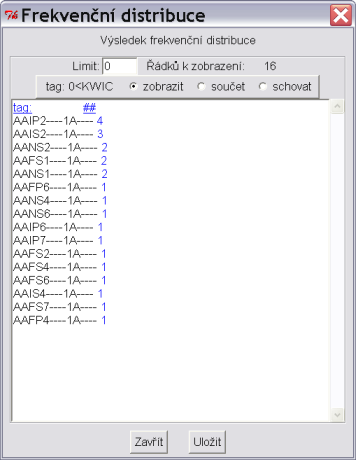
Frekvenční distribuce zobrazí vybrané atributy nalezených hodnot spolu s četnostmi. Na obrázku 3.6 je vidět frekvenční rozložení morfologických značek pro lemma jarní.
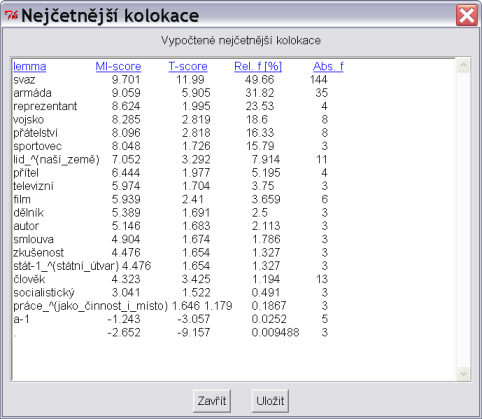
Poslední významnou statistickou funkcí jsou Kolokace. Pomocí této funkce lze zobrazit slova (nebo lemmata nebo značky), která
se vyskytují v zadaném okolí nalezených výskytů (viz obrázek 3.8). Výsledkem je tabulka udávající pro každé slovo
ze zadaného okolí jeho frekvenci v rámci nalezených konkordancí, relativní frekvenci, MI-score a T-score. Kliknutím na kategorii v záhlaví tabulky
se změní řazení řádků podle vybrané kategorie, přičemž nejvýznamnější kolokace jsou vždy nahoře. Obrázek 3.7 obsahuje
kolokace k lemmatu sovětský.
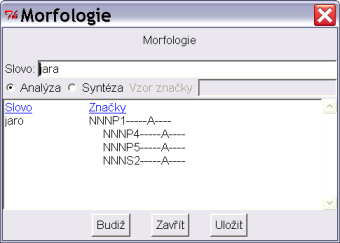
Z korpusového nástroje Bonito je možné vyvolat morfologickou analýzu, a to z menu
Manažer – Morfologie. Nové okno, které tak otevřete, si můžete nechat připravené po celou dobu práce s korpusovým nástrojem. Můžete z něj spouštět morfologickou analýzu, nebo syntézu (generování). Morfologická analýza zadaného slova vypíše všechna možná lemmata a jim příslušné značky. Při zaškrtnutí syntézy zase dostanete všechny možné slovní tvary, které lze ze zadaného lemmatu vytvořit, spolu s jejich morfologickými značkami. Viz obr. 3.9.
Přepínání mezi anglickým a českým pracovním prostředím je možné z menu volbou Manažer – Změna jazyka (Manager – Change language).
LAW (Lexical Annotation Workbench) je integrované prostředí pro morfologické anotování. Podporuje přímou morfologickou anotaci (tj. přiřazování lemmatu a značky danému slovu), porovnání anotací jednoho textu (kupříkladu více anotátory), vyhledávání slov, značek atd. Editor pracuje na všech operačních systémech, které podporují Javu, včetně systémů Windows a Linux. LAW je otevřeným systémem rozšiřitelným prostřednictvím externích modulů – např. pro různá zobrazení dat, import/export souborů a nápovědy. LAW podporuje formáty PML [10], csts [9] a TNT [23]. Zároveň je možné importovat a exportovat data ve formátu csts [9] a TNT [23].
Pracuje se na rozšíření LAW o statistické funkce a podporu volání externích nástrojů (např. tagger, parser, atd.).
LAW pracuje s tzv. rovinami anotace. Jednotlivé morfologické roviny (m-roviny) obsahují výsledky různých nastrojů nebo procesů. Např. výsledek morfologického analyzátoru, taggeru, nebo ruční anotace. Ve formátu PML je každá rovina ve zvláštním souboru.
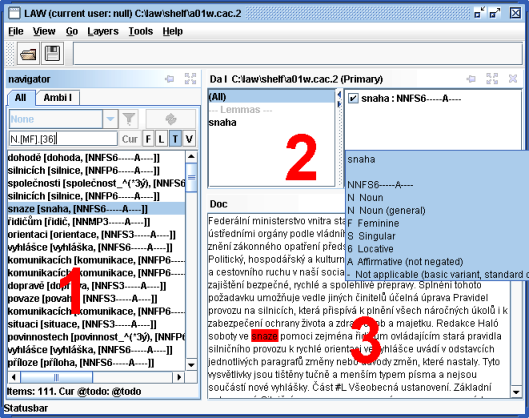
Navigator – zobrazuje seznamy slov dokumentu filtrované podle různých kritérií a umožňuje výběr určitého slova pro disambiguaci.
Da Panely – zobrazují morfologickou informaci o slovu a umožňují její disambiguaci, tzn. výběr správného lemmatu a značky. Panel se skládá ze dvou oken – seznamu skupin a seznamu položek. Seznam položek zobrazuje všechna lemmata a značky přiřazené danému slovu (na dané m-rovině). Pomocí seznamu skupin lze položky omezit jen na určité lemma, slovní druh, podrobný slovní druh nebo rod. Jeden Da Panel je vždy hlavní (primary), určité akce se pak týkají jen tohoto panelu (např. Ctrl-T aktivuje seznam lemmat a značek v hlavním panelu).
Kontextová okna – kontextové informace, např. text dokumentu, syntaktické struktury, atd.
Otevřete m-soubor, který chcete anotovat:
File | Open(Ctrl-O). Odpovídající w-soubor se otevře automaticky.Přepněte se v Navigátoru do seznamu nejednoznačných slov (Ambi + jméno dané m-roviny), ve kterém se zobrazí nejednoznačná slova, tj. slova, pro která morfologická analýza nabízí více možností, a vyberte ze seznamu první slovo.
-
Zmáčkněte
Enter. Kurzor se přesune do hlavního Da Panelu. Vyberte správné lemma a značku a opět zmáčkněteEnter. Kurzor se přesune na další nejednoznačné slovo.Pokud uděláte chybu, přepněte se v Navigátoru do seznamu všech položek (All), nalezněte chybně anotované slovo a vyberte jej. Příslušná anotace se zobrazí v Da Panelu. Vyberte správné lemma a značku a přepněte se zpátky do seznamu nejednoznačných slov (Ambi X).
Uložte výsledek anotování:
File | Save(Ctrl-S).
Paralelně s prací nad daty jsou vyvíjeny aplikace pro morfologické zpracování českých textů. Dvě základní morfologické aplikace – morfologická analýza a tagování – jsou součástí CD.
Morfologická analýza zpracovává jednotlivé slovní formy a určuje pro ně lemmata (základní tvary, např. pro podstatná jména první pád jednotného čísla, pro slovesa infinitiv) a možné morfologické interpretace.
Základem morfologické analýzy je morfologický slovník, který obsahuje tvaroslovné informace o českých slovech a jejich odvozeninách. Každý slovní tvar má přiřazeno lemma a morfologickou značku (morfologický tag), která danému tvaru přísluší. V použitém morfologickém slovníku mají mnohá lemmata doplňující informace o stylu, sémantice nebo o způsobu odvození. V případě zkratek bývají lemmata opatřena komentářem s vysvětlujícím textem (viz příloha C).
Vzhledem k vysoké homonymii češtiny náleží většině slovních tvarů více morfologických značek, občas i více lemmat. Např. slovní tvar pekla má dvě různá lemmata – podstatné jméno peklo a sloveso péci. Obě lemmata dále mohou pro uvedený slovní tvar mít několik různých morfologických značek. Při morfologické analýze se probírají jednotlivé slovní formy z celého korpusu a porovnávají se se slovními formami obsaženými v morfologickém slovníku. V případě shody se danému slovnímu tvaru přiřadí příslušná lemmata a morfologické značky. Výsledkem morfologické analýzy pro konkrétní slovo je tedy množina dvojic lemma – morfologická značka.
Na morfologickou analýzu navazuje tagování (někdy také desambiguace nebo disambiguace). Během této fáze se vybere ze všech možných lemmat a morfologických značek, přiřazených v předchozí fázi, jediná dvojice, která by měla být v konkrétním kontextu správná. Vzhledem k obtížnosti úlohy není možné navrhnout takovou metodu tagování, která by pracovala se stoprocentní úspěšností.
Použitý tagger je založen na skrytých markovovských modelech
s využitím průměrovaného perceptronu (Collins, 2002).
Jedná se o metodu statistickou. Vstupem taggeru je text, který pro každé slovo obsahuje
množinu všech možných morfologických značek a lemmat (výstup z mofologické analýzy).
Na výstupu pak k těmto datům přidává jednoznačně vybranou značku a jí odpovídající lemma.
Tagger byl natrénován na datech z PZK 2.0 a jeho úspěšnost (procento správně určených morfologických značek)
na ČAK 1.0 je 91,8 %. Část chyb je ovšem způsobena rozdíly mezi PZK a ČAK, což
v důsledku vede k tomu, že morfologická analýza pro některá slova nenabízí správné značky. Systematicky se to stává pro číslovky zapsané číslovkami (v ČAK reprezentovány jako #) a neznámá slova (reprezentována znakem ?). Pokud tyto
systematické rozdíly nebereme v potaz, je výsledná úspěšnost značkování 93,1%.
Nástroje se spustí hlavním skriptem morph_chain, který dle přepínače zpracuje vstupní soubor
příslušným nástrojem. Použití skriptu je dokumentováno v Tabulce 3.6. Další podrobnosti jsou uvedeny v kapitole
5.
Tabulka 3.6. Skript morph_chain
| Parametr | Formát vstupního souboru |
Formát výstupního souboru |
Popis |
|---|---|---|---|
-A |
surový text, PML m-soubor | PML m-soubor | morfologická analýza |
-T |
PML m-soubor | PML m-soubor | tagování |
-AT |
surový text, PML m-soubor | PML m-soubor | tagování (před tagováním se vstupní text zpracuje morfologickou analýzou) |
Nástroje jsou implementovány v programovacích jazycích C/C++ a Perl a hlavní skript morph_chain v jazyku bash.
Vzhledem k autorským právům neposkytujeme zdrojové C/C++ kódy. Spustitelné programy jsou kompilovány pro operační systém Linux běžící
na architektuře i386.
Příklad: Ukážeme zpracování textu
Fantastickým finišem si však Neumannová doběhla pro vytoužené olympijské zlato.
Výsledky morfologické analýzy a tagování (konkrétně spuštěním morph_chain -AT) jsou souhrnně uvedeny v tabulce 3.7.
V případě více možných základních tvarů slovní
formy (např. slovní forma si je analyzována buď jako sloveso být, nebo jako zvratná částice
se) jsou tyto základní tvary odděleny symbolem svislého lomítka „|“. Abychom usnadnili čtenáři pátrání po chybách, kterých
se tagger dopustil, uvádíme chybně zjednoznačněné značky tučně. Za chybnou značkou je v závorce uvedena značka, která je správná vzhledem
k danému kontextu.
Tabulka 3.7. Ukázka textu zpracovaného morfologickou analýzou a tagováním
| Text | Morfologická analýza | Tagování |
|---|---|---|
Fantastickým |
fantastický AAFP3----1A---- AAIP3----1A---- AAIS6----1A---7 AAIS7----1A---- AAMP3----1A---- AAMS6----1A---7 AAMS7----1A---- AANP3----1A---- AANS6----1A---7 AANS7----1A---- |
fantastický AAIS7----1A---- |
finišem |
finiš NNIS7-----A---- |
finiš NNIS7-----A---- |
si |
být VB-S---2P-AA--7|se_ ^(zvr._zájmeno/částice) P7-X3---------- |
se_^(zvr._zájmeno/částice) P7-X3---------- |
však |
však J^------------- |
však J^------------- |
Neumannová |
Neumannová_;S NNFS1-----A---- NNFS5-----A---- |
Neumannová_;S NNFS1-----A---- |
doběhla |
doběhnout_:W VpQW---XR-AA--1 |
doběhnout_:W VpQW---XR-AA--1 |
pro |
pro-1 RR--4---------- |
pro-1 RR--4---------- |
vytoužené |
vytoužený_^(*3it) AAFP1----1A---- AAFP4----1A---- AAFP5----1A---- AAFS2----1A---- AAFS3----1A---- AAFS6----1A---- AAIP1----1A---- AAIP4----1A---- AAIP5----1A---- AAMP4----1A---- AANS1----1A---- AANS4----1A---- AANS5----1A---- |
vytoužený_^(*3it) AANS1----1A---- (AANS4----1A----) |
olympijské |
olympijský AAFP1----1A---- AAFP4----1A---- AAFP5----1A---- AAFS2----1A---- AAFS3----1A---- AAFS6----1A---- AAIP1----1A---- AAIP4----1A---- AAIP5----1A---- AAMP4----1A---- AANS1----1A---- AANS4----1A---- AANS5----1A---- |
olympijský AANS1----1A---- (AANS4----1A----) |
zlato |
zlato NNNS1-----A---- NNNS4-----A---- NNNS5-----A---- |
zlato NNNS1-----A---- (NNNS4-----A----) |
. |
. Z:------------- |
. Z:------------- |
Doporučujeme uživatelům, aby si vybrali libovolný český text a zpracovali jej skriptem morph_chain -A. Následně
výstup skriptu (soubor s příponou .m) otevřte v nástroji LAW a začněte zjednoznačňovat značky slov.