


Český akademický korpus verze 2.0 je morfologicky a syntakticky ručně anotovaným korpusem češtiny o objemu 650 tisíc slov.
Český akademický korpus (ČAK) vznikl v letech 1971 až 1985 v Ústavu pro jazyk český AV ČR pod vedením dr. Marie Těšitelové [11][1] jako podklad pro sestavení frekvenčního slovníku češtiny té doby – původně nesl zcela „věcný“ název Korpus věcného stylu. Korpus byl ručně morfologicky a syntakticky anotován Nezávisle na korpusu ČAK byla v roce 1996 zahájena anotace Pražského závislostního korpusu (PZK). Při práci na jeho již druhé verzi [15] se objevila myšlenka převést vnitřní formát a anotační schémata korpusu ČAK tak, aby byl zcela kompatibilní s PZK, tedy aby se dal do PZK přímo začlenit. Konverze vnitřního formátu a morfologického anotačního schématu vyústila v publikování první verze ČAK (Vidová Hladká a kol., 2007). Představovaná druhá verze obohacuje ČAK 1.0 v tom smyslu, že obsahuje navíc povrchově syntaktickou anotaci (v terminologii PZK, anotaci na tzv. analytické rovině).
Během práce na ČAK 1.0 byly do textu ručně vkládány zástupné symboly („#“ a „?“) za chybějící slova a ciferné výrazy – tyto korektury a skutečnosti, které k nim vedly, jsou podrobně popsány v Průvodci ČAK 1.0 (Vidová Hladká a kol., 2007). Během práce na ČAK 2.0 nebyly tyto zástupné symboly dále zpracovávány. Upozorňujeme zde na tuto skutečnost, aby uživatel korpusu nebyl zástupnými symboly zaskočen.
ČAK 2.0 nabízí
jazykovědcům jazykový materiál, který reflektuje reálné použití jazyka,
počítačovým lingvistům nástroje a další data nezanedbatelného objemu, která by měla přispět ke zlepšení aplikací, které pracující s přirozeným jazykem a bez morfologického a syntaktického zpracování textů se neobejdou,
uživatelům anotačního nástroje TrEd možnost ovládat tento nástroj hlasem,
pedagogům, jejich žákům a studentům zajímavou pomůcku do hodin češtiny, při kterých se procvičuje tvarosloví a syntax češtiny.
Dokumenty v ČAK jsou nezkrácené články z širokého spektra novin a časopisů a nezkrácené přepisy mluvené řeči z řady rozhlasových a televizních pořadů, a to z oblasti novinářské, vědecké a administrativní. Texty pocházejí ze 70. a 80. let 20. století. Úplný výčet použitých zdrojů je uveden v příloze A.
O korpusu se nedá hovořit jako o anotovaném, aniž by se specifikovalo, čeho se anotace týkají. Jinými slovy – z pohledu jazykovědné teorie – se musí specifikovat tzv. rovina anotace. Anotace ČAK 2.0 pokrývají dvě roviny – morfologickou a analytickou. Abychom byli úplně korektní, musíme doplnit, že operujeme ještě s jednou rovinou, a to s rovinou slovní. Slovní rovina je ve skutečnosti rovinou neanotační (pro pohodlí ale o ní budeme nadále hovořit jako o rovině anotační), obsahuje pouze původní text rozdělený na slovní jednotky (slova, čísla zapsaná číslicemi, interpunkce). Nadále budeme slovní rovinu zkráceně označovat jako w-rovinu (z anglického word), morfologickou rovinu jako m-rovinu a analytickou rovinu jako a-rovinu.
Anotace na m-rovině znamená, že slovním jednotkám textu jsou přiřazovány údaje (anotace), které charakterizují jejich morfologické vlastnosti, tedy lemma (základní tvar slova), slovní druh a morfologické kategorie (pád, číslo, čas, osoba, ...). Formálně jsou slovní druhy společně s hodnotami morfologických kategorií reprezentovány jako znakové řetězce, tzv. morfologické značky nebo také tagy. V ČAK 2.0 jsou použity značky navržené pro PZK jako řetězce pevné délky, a to délky 15 znaků, kde každá pozice jednoznačně odpovídá právě jedné kategorii – hovoříme o tzv. pozičních značkách; jejich popis je k nahlédnutí v příloze C.
Příklad: Slovní forma Prahu se analyzuje jako substantivum (1. a 2. pozice) ženského rodu (3. pozice) ve tvaru akuzativu (5. pozice) singuláru (4. pozice), které není negováno (11. pozice). Na všech ostatních pozicích je správně symbol „-“, který signalizuje nerelevantnost příslušné morfologické kategorie danému slovnímu druhu. Například u substantiv se neurčuje osoba ani čas (8. a 9. pozice).
Tabulka 2.1. Příklady lemmat a značek
| slovní jednotka | lemma | značka | popis |
|---|---|---|---|
| Prahu | Praha | NNFS4-----A---- | substantivum, femininum, singulár, akuzativ, afirmativum |
| 123 | 123 | C=------------- | číslo zapsané číslicemi |
| ) | ) | Z:------------- | interpunkční znaménko (pravá kulatá závorka) |
Anotace na a-rovině znamená, že slovním jednotkám jsou přiřazeny údaje, které charakterizují jejich syntaktické vlastnosti, tedy jejich vztah k ostatním členům věty a jejich funkci ve větě. Formálně jsou vztahy ve větě reprezentovány závislostním stromem. Funkce slovních jednotek ve větě jsou vyjádřeny tzv. analytickými funkcemi, jejichž seznam je uveden v příloze D.
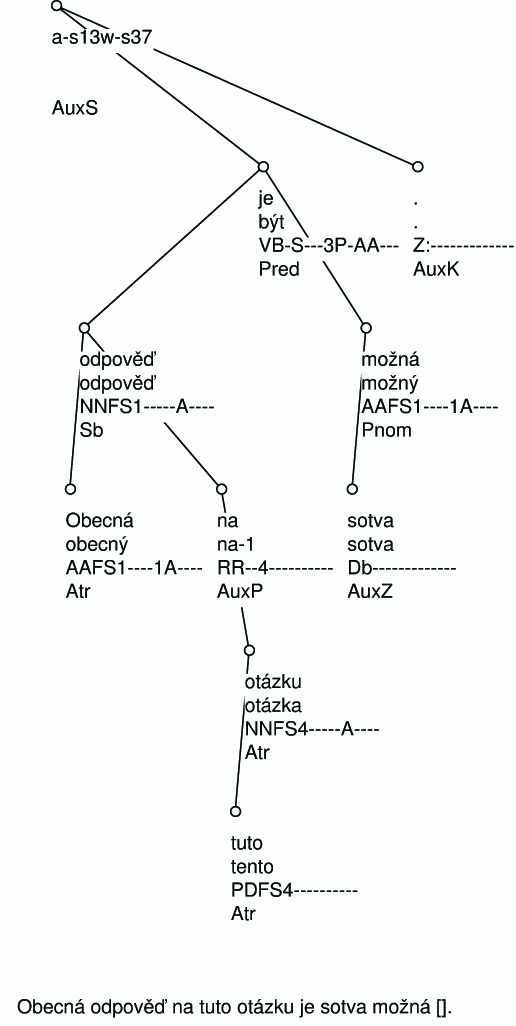
Příklad: V obrázku 2.1 je uvedena syntaktická anotace věty Obecná odpověď na tuto otázku je sotva možná. Ve výsledném stromě je každá slovní jednotka (slovo, číslo, interpunkční znaménko) reprezentována uzlem. Musíme dodat, že z technických důvodů obsahuje každý strom navíc ještě jeden uzel, který je kořenem stromu – v našem příkladu je tedy devět uzlů. Koncepce anotace vychází z tradice Pražské lingvistické školy, která chápe predikát (přísudek; nejčastěji sloveso) jako hlavní člen věty. Proto predikát je je zavěšen na kořeni. Na kořeni je rovněž zavěšena koncová interpunkce. Na predikátu je jsou závislé dva větné členy – odpověď a možná. Všimněte si, že u každého uzlu stromu na obrázku je zobrazena slovní forma, lemma, morfologická značka a analytická funkce. Zastavíme-li se u uzlu reprezentujícího slovo odpověď, vidíme, že se jedná o podstatné jméno rodu ženského v prvním pádě jednotného čísla a že tato jednotka je podmětem věty (subjektem - což je vyjádřeno analytickou funkcí Subj) .
Koncepce hlavního vnitřního formátu ČAK 2.0 (jedná se o formát PML – viz oddíl 3.2.1) zachází s anotacemi na jednotlivých rovinách odděleně, tj. každé rovině anotace dokumentu odpovídá jeden soubor (v případě formátu CSTS jsou všechny roviny anotace uchovány v jednom souboru). Vztaženo na ČAK 2.0 to znamená, že pro každý dokument existují tři soubory, jeden pro w-rovinu, druhý pro m-rovinu a třetí pro a-rovinu. Nicméně zmíněné oddělení neznamená, že ty soubory pro jednotlivé roviny anotace nebyly propojeny. Jak vzápětí ukážeme, je tomu právě naopak.
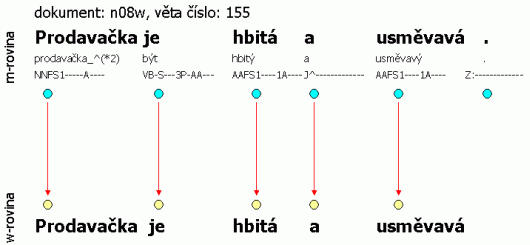
Slovní rovina neobsahuje segmentaci textu na věty; ta je až na m-rovině. To znamená, že m-rovina obsahuje navíc oproti w-rovině koncovou (větnou) interpunkci. Kromě toho se může lišit i počet slovních jednotek na obou rovinách, což může být způsobeno buď spojením nesprávně rozdělených slov do jednoho, nebo naopak rozdělením slov, která byla spojena do více jednotek. Na m-rovině už by měl být text napsán správně text.
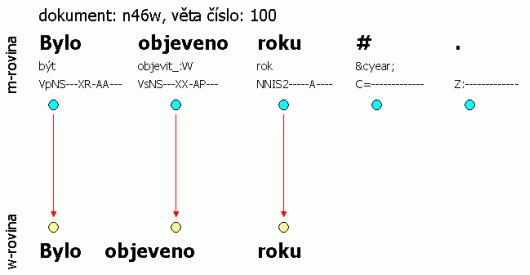
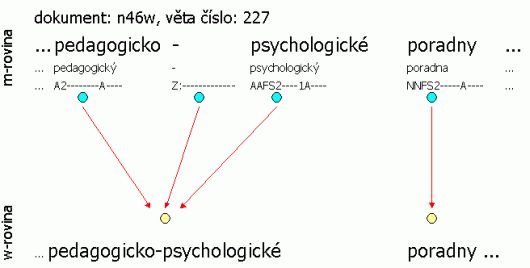
Příklad: Následující tři obrázky dokládají propojení w-roviny a m-roviny – tedy i souborů – ve smyslu počtu slovních jednotek (propojení naznačeno šipkami). Všechny tři příklady jsou úmyslně vybrány z ČAK 2.0, aby mohl uživatel přímo nahlédnout do souborů (pro každou větu je uveden název dokumentu a číslo věty). Obrázek 2.2 ilustruje poměr 1:1 – až na koncovou interpunkci se roviny neliší. Obrázek 2.3 ilustruje situaci, kdy byla do textu vložena slovní jednotka – zde evidentně v textu chybělo určení roku. Pro korektora bylo téměř nemožné doplnit konkrétní rok, proto je uveden znak „#“, který nemá svůj protějšek na w-rovině. Naopak obrázek 2.4 ilustruje situaci, kdy více jednotek m-roviny má stejný protějšek na w-rovině – slovní jednotka pedagogicko-psychologické je rozdělena na tři samostatné jednotky.
Propojení mezi a-rovinou a m-rovinou znamená, že každé slovní jednotce m-roviny odpovídá právě jeden uzel závislostního stromu na a-rovině. a naopak – až na jednu výjimku, a tou je technický kořen, který na m-rovině svůj protějšek nemá. Popisované propojení je ilustrováno obrázkem 2.1.
Projekt Českého akademického korpusu prochází staletími, jak je podrobně popsáno v příspěvku (Hladká, Králík, 2006). Cestě, která vyústila ve vydání první verze akademického korpusu, se zde věnovat nebudeme. Je jí věnován Průvodce ČAK 1.0 (Vidová Hladká a kol., 2007). Zde zrekapitulujeme cestu k druhé verzi, a to pro každou anotační rovinu zvlášť.
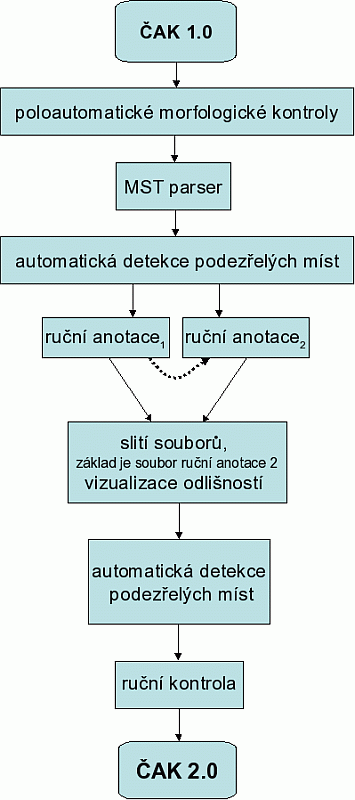
Při přípravě dat pro ČAK 2.0 byly provedeny další poloautomatické kontroly morfologické anotace. Rozsáhlé poloautomatické kontroly byly navrženy již při přípravě ČAK 1.0. Kontroly byly motivovány obdobnými kontrolami, které probíhaly při tvorbě Pražského závislostního korpusu 2.0. Jejich podrobný popis byl podán v průvodci ČAK 1.0.
Automatické kontrolní skripty procházely data a označovaly podezřelá místa; ta pak ručně prošel, zkontroloval a případně opravil anotátor. Jednalo se především o kontrolu shody jednotlivých morfologických kategorií mezi původní morfologickou značkou ČAK a poziční morfologickou značkou ČAK 1.0. Například pokud jde o pád u podstatných jmen, našly skripty 1258 podezřelých značek, ze kterých anotátor prohlásil 332 za chybné a následně je opravil. V pádě přídavných jmen našly skripty 177 podezřelých značek, anotátor z nich opravil 41.
Všechny kontroly byly prováděny v souladu s pokyny pro morfologickou anotaci PZK [16].
V případě analytických anotací jsme stáli před otázkou, jakým způsobem mapovat původní anotace do anotací koncipovaných v projektu Pražského závislostního korpusu. Tuto otázku jsme dle zkušeností s morfologickými anotacemi převedli na tři podotázky, a sice Automaticky? Poloautomaticky? Ručně? Hledání odpovědí je podrobně popsáno v příspěvku (Ribarov, Bémová, Hladká, 2006). Autoři příspěvku došli k závěru, který možná mnohé čtenáře překvapí: zcela odhlédnout od původních anotací, ČAK 1.0 (tedy ručně morfologicky anotované texty) zpracovat automatickou procedurou (tzv. parserem), která každé větě přiřadí závislostní strom s určenými větnými členy, a následně stromy s určenými větnými členy ručně zkontrolovat (i nadále říkáme anotovat). Použili jsme maximum spanning tree parser (MST parser), o kterém informujeme podrobněji dále (viz 3.3.5).
Na analytických anotacích Pražského závislostního korpusu pracovali přímo jazykovědci. Z této skupiny byly pro náš projekt k dispozici dvě anotátorky, které se staly hlavními arbitry. Dále byli k dispozici studenti filologických oborů – jedna česka anotátorka a tři slovenští anotátoři, kteří měli za sebou zkušenost s anotováním Slovenského národního korpusu [20] pod vedením pražských jazykovědců „natrénovaných“ na PZK. Anotace ČAK tedy byla dvoustupňová: anotátor, arbitr. Z počátku pracovali anotátoři paralelně, tj. jeden dokument byl anotován dvěma anotátory. Jejich anotace byly automaticky porovnány a postoupeny arbitrovi. Jakmile se anotátoři uspokojivě (dle arbitra) zacvičili, anotovali každý dokument právě jednou. Při druhém stupni kontroly arbitr procházel celý dokument větu po větě, tj. v případě paralelních anotací se nesoustředil pouze na odlišnosti. Mezi jednotlivými stupni anotací byly dokumenty zpracovány automatickými kontrolními skripty.
Stejně jako u morfologických anotací byly automatické skripty inspirovány obdobnými kontrolami prováděnými při přípravě PZK 2.0. Skripty procházely data a označovaly podezřelá místa. Kontrolovala se jednak přípustnost vztahů mezi uzly na analytické rovině, jednak přípustnost kombinace morfologické značky a analytické značky jednotlivých uzlů. Podezřelá místa byla označena a anotátoři je při práci se stromy viděli zvýrazněné, spolu se stručným popisem nesrovnalosti. Chyba pak mohla být jak na analytické rovině, tak někdy i na rovině morfologické.
Všechny kontroly byly prováděny v souladu s pokyny pro analytickou anotaci PZK [17].
Příkladem analyticko-morfologické kontroly může být jeden ze skriptů, který ověřoval anotaci slovní formy se. Skript ověřil u každého takového uzlu podmínku: Každý uzel se slovní formou se je buď zvratné zájmeno s analytickou funkcí AuxT nebo AuxR, nebo je to vokalizovaná předložka s analytickou funkcí AuxP. Další skripty ověřovaly shodu morfologických kategorií nebo přípustnost kombinace analytických funkcí dvou uzlů, řídícího a závislého (jako např. vazbu předložky a pádu podstatného jména, které na ní visí, nebo možné umístění uzlu označeného jako subjekt (Subj)).
Obrázek 2.5 souhrnně ukazuje, jaké operace probíhaly na datech od vydání ČAK 1.0 až do vydání ČAK 2.0.
[1] Vedle bibliografických citací (např. Vidová Hladká a kol., 2007) uvádíme v textu i citace internetové, a to jako číslo v hranaté závorce, které odkazuje do seznamu internetových adres vyjmenovaných v příloze E.