
PEDT 1.0
Tectogrammatical Representation, Tectogrammatical Annotation
Functional Generative Description
The tectogrammatical annotation is based on Tectogrammatical Representation, which is one level of the formal language description proposed by the Functional Generative Description (FGD). FGD is based on the structuralist tradition, developed since the 1960s. It is implemented in a family of syntactico-semantically annotated treebanks. The treebanks are typically annotated at three layers:
- morphological layer (m-layer)
- analytical layer (a-layer)
- tectogrammatical layer (t-layer).
At the m-layer the text is still a sequence of strings with added tokenization, POS tagging, and lemmatization. Each token has its unique ID. The a-layer displays the sentences as dependency trees in which each token is represented by a node. The nodes are labeled with coarse syntactic labels.
The topmost layer so far is the tectogrammatical layer (t-layer), which is based on the tectogrammatical representation (TR) proposed by FGD. Conceived as an underlying syntactic representation, the TR captures the linguistic meaning of the sentence. By linguistic meaning we understand "what has been said and can be perceived without any special knowledge of the situation" but with the common understanding of basic conversational implicatures, as well as with tolerance for redundance and vagueness. E.g. unlike a strictly logical representation, the tectogrammatical representation would not deal with the question whether in the sentence John heard a cry there must have been a cry for John to hear, or whether John might have mistakenly interpreted a sound he had heard as a cry. On the other hand, the tectogrammatical representation would indicate that something unexpressed on the surface is likely to be understood from the context or from the situation, or that something has been deliberately left underspecified; e.g. in the sentence I told you last night the tectogrammatical representation of the verb to tell would indicate that something (EFF), possibly about a mentioned matter (PAT) was told to somebody (ADDR), and it would indicate whether these entities could be retrieved from the verbal context or not. (While the missing EFF argument of tell is in this case likely to be retrievable from the context, some ellipses systematically express generalizations; e.g., Peter can eat [something, anything] alone.)
Tectogrammatical Annotation
The tectogrammatical annotation is to be held apart from the theoretical construct of tectogrammatical representation, as many annotation resolutions still have still been introduced for technical and consistency reasons rather than being conditioned by the theory. The treebanks of the PDT family are however being continuously refined, with the ambition of adequately reflecting the FGD as a linguistic description. That is done by a step-by-step uncovering and consistent tectogrammatical representation of lexical and structural patterns.
The basic description unit of the tectogrammatical annotation is the sentence. Each sentence is represented as a projective dependency tree with nodes and edges (henceforth tectogrammatical tree structure or TGTS). Only content words are represented by nodes. Each node has a semantic label ("functor"), which renders the semantic relation of the given node to its parent node. Function words are represented as attribute values in the internal structure of the respective nodes. The attribute values contain references to the analytical (surface-syntax) annotation layer instead of the forms of the function words themselves. A more detailed specification of the annotation conventions is given in the annotation manual .
Tectogrammatical annotation, which draws on TR, captures the following aspects of text:
- syntactic and semantic dependencies
- argument structure (data interlinked with a lexicon)
- information structure (topic-focus articulation, so far Czech only)
- grammatical and textual coreference (only grammatical coreference and only partially in English data)
- ellipsis restoration
- information on lexical and syntactic derivation (so far Czech only)
- semantically determined grammatical categories (grammatemes) (just a tentative automatic insertion in English at the moment, not in this data)
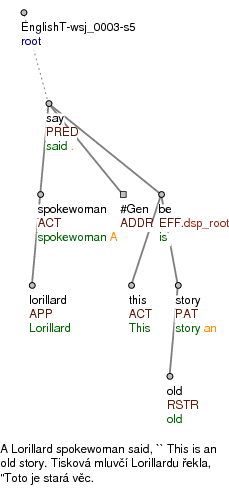 The figure shows the tectogrammatical tree structure (TGTS) of the sentence A Lorillard spokewoman said: "This is an old story."
The figure shows the tectogrammatical tree structure (TGTS) of the sentence A Lorillard spokewoman said: "This is an old story."
The green strings in the figure represent the targets of the content-word references. The orange strings represent the targets of the auxiliary-word references.
The predicate say has three obligatory participants: the Actor, the Addressee and the Effect (what is being said). The Addressee is underspecified, which is why a generated node with the t-lemma substitute #Gen (generalized) was inserted. In general, each occurrence of a word with argument structure (so far only verbs and verbal nouns in the English annotation) is interlinked with an instance (a valency frame) in the valency lexicon. When assigned to a lexicon frame, the occurrence of the given word must have the complete pattern of obligatory arguments (inner participants) determined by the valency lexicon. Generated nodes with t-lemma substitutes are inserted to complete the valency frame.
The figure shows a few common semantic labels (functors) used in TGTS. The functors ACT, PAT, ADDR (in the figure), ORIG and EFF are labels for complementations which cannot repeat in the same predicate. About 70 functors in total are used in the annotation. It is partly functors for adjuncts, partly functors for semantic relations between conjuncts in coordinations, and a few functors which help organize cognitively specific syntactic structures such as comparisons. A complete list of functors along with the list of t-lemma substitutes is to be found in the annotation manual. The functors indicate the semantic relation of a given node to its parent node. The node that modifies another node is governed by that node (except in shared modifiers in conjuncts). For instance, Lorillard modifies spokewoman, and the semantic relation between Lorillard and spokewoman is labelled as APP ("appurtenance"; i.e. association in a broader sense than ownership). The effective root of a direct speech subtree is marked with the note dsp_root.