Examples. The manual contains a number of examples illustrating the phenomena in question. The examples have a fixed form. They do not provide the structure; they only present the values of the attributes of individual words present or absent in the surface structure of the example sentence.
The example sentences are artificial and usually presented without any context. The illustrated annotation corresponds to the most common context the sentence could be used in.
NB! The example sentences necessarily contain only the part that is to be illustrated (i.e. elided expressions - if present - do not have to be made visible if they are not the subject of the illustration).
Items represented by a single node in the sentence are underscored. The value of the relevant attribute is given in square brackets in the following form: the name of the attribute=the value of the attribute (if there are more possible values, they are all in the brackets, separated by a semicolon). If the example sentence is supposed to illustrate the values of just one node, the values are presented in square brackets after the example sentence. If there are more nodes the values of which are to be illustrated, the values follow (in square brackets) immediately after the last underscored word represented by the given node.
An exception to this are the functor values. If the functor values of individual nodes are to be illustrated, they always immediately follow the given word. Functors are not given in square brackets; they are separated from the word by a period.
Examples:
Upadl do nesnází.DIR3 na dlouhou dobu. [is_state=1] (=He got into difficulties for a long time)
Špičková cena.DENOM [is_member=1] a.CONJ špičkový výkon.DENOM [is_member=1] (=Top price and top performance)
The words that are not expressed at the surface level (and are represented by newly established nodes) are given in curly brackets. Curly brackets always contain the t-lemma of the newly established node, which may but need not be followed by the values of selected attributes.
Examples:
{#PersPron.ACT} Přijde. (=She will come)
{#PersPron.ACT [tfa=t]} Přijde. (=She will come)
If it is necessary to stress that certain words are not assigned a separate node in the tectogrammatical tree, they are given in angle brackets < >.
Example:
Přijde jen.RHEM <tehdy> , <když> mu ustoupíš.TWHEN (=He comes only in the case you give in to him)
Example tectogrammatical trees. For a number of the example sentences, example trees are included as well. Each example tree represents a complete analysis of the given sentence.
Tectogrammatical trees in PDT 2.0 make use of two different styles of representation (see Prague Dependency Treebank 2.0, CDROM, doc/tools/tred/PML_mak.html). The example trees in the manual make use of the following (representation) settings (PML_T_Full template).
Nodes. Under a tree node, the attribute values are displayed (if assigned) in the following order:
-
t_lemma.sentmod(t_lemmaof the co-referred node)tfa_functor.subfunctor.state_M_Pnodetypeorgram/semposgramperson_name
dsp_root.quot/type:
quot/type
The attribute values are usually presented directly, without giving the name of the attribute first. Names of the attributes are only provided if the values are not unambiguous. The value of the attribute quot/type is always in the form: name of the attribute:its value.
As for complex nodes (nodetype=complex), the value of the nodetype attribute is not specified; the value of the gram/sempos attribute is given directly instead.
The notation state is included in the list of the attribute values if the value of the is_state attribute is 1.
The notation _M is included if the value of the is_member attribute is 1.
The notation _P is included if the value of the is_parenthesis attribute is 1.
The notation person_name is included if the value of the is_person_name attribute is 1.
The notation dsp_root is included if the value of the is_dsp_root attribute is 1.
Nodes representing words present at the surface level are represented as little circles; newly established nodes (is_generated=1) are represented as little squares.
(The color of the nodes carries certain information as well: yellow means the node has the f value in the tfa attribute, green means c in the tfa attribute , white means t in the tfa attribute. Nodes with no value assigned in the tfa attribute are grey.)
Edges. Edges are the connecting lines between nodes.
The edge between the technical root node of the tectogrammatical tree and the root node of the represented sentence and the edges between nodes with the PAR, PARTL, VOCAT, RHEM, CM, FPHR and PREC functors and their mother nodes (i.e. edges not representing dependencies; see Section 1.2, "Non-dependency edges") are represented as thin dotted lines.
The upper half of the edge between a paratactic structure root node and a terminal member of the paratactic structure is represented as a thin grey line; the lower half is represented as a thick grey line. The upper half of the edge between a paratactic structure root node (that is not a member of another paratactic structure) and its mother node is represented as a thick grey line; the lower half is represented as a thin grey line. The edge between a paratactic structure root node and the root of a shared modifier is represented as a thin (blue) line. The edge between a paratactic structure root node and a direct member of this structure that is a paratactic structure root node itself (in case of embedded paratactic structures) is represented as a thin grey line. (For more on paratactic structures, see Section 6.1, "Representing parataxis in a tectogrammatical tree".)
References. Attributes of the type reference, marking especially co-referential relations, are represented as arrows going from one node to another. Grammatical coreference is represented by an orange dotted arrow pointing to the co-referred node (starting at the co-referring node). Textual coreference is represented by a blue dotted arrow pointing to the co-referred node (starting at the co-referring node). If the co-referred node is not in the same tree as the co-referring node, the arrow is short and points either to the left or to the right of the node, depending on whether the co-referred node is in the preceding or following tree; next to the co-referring node, the t-lemma of the co-referred node is specified.
NB! Textual coreference relations crossing the boundaries of a single tectogrammatical tree are not represented in the example trees at all.
Reference to a segment (coref_special=segm) is represented as a short red arrow pointing to the left of the node. Exophoric reference (coref_special=exoph) is represented as a short blue arrow pointing upwards.
The second dependency with predicative complements is represented by a green mixed (dash - period) arrow going from the node with the COMPL functor to the node representing the governing noun.
NB! In the example tectogrammatical trees (just like in the PDT trees; see Section 2.4, "Representing valency in the tectogrammatical trees"), the valency of nouns is not represented properly - with the exception of verbal nouns!
Figure 1.1. Example tectogrammatical tree
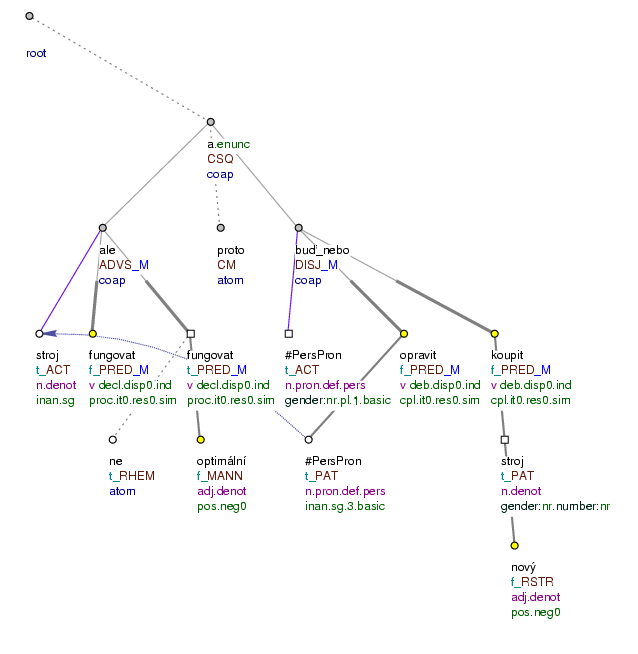
Stroj funguje, ale ne optimálně, a proto ho musíme buď opravit, nebo koupit nový. (=lit. Machine is_working, but not optimally, and therefore (we) it have_to either repair, or buy new)
Figure 1.2. Example tectogrammatical tree
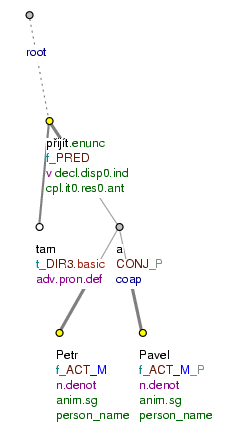
Přišel tam Petr (a Pavel). (=lit. Came there Petr (and Pavel))
Figure 1.3. Example tectogrammatical tree
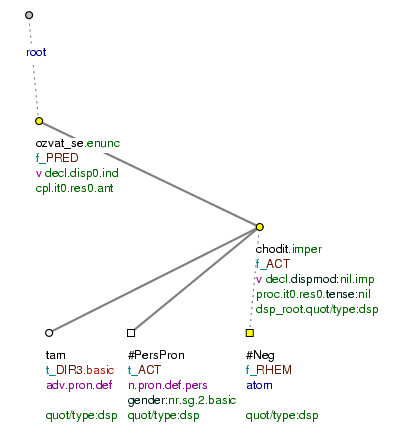
Ozvalo se: "Nechoď tam!" (=lit. Sounded REFL: Don't_go there!)
Other typographical conventions. Minor titles at the beginning of the paragraphs are marked by boldface. Italics are used for highlighting the terms that are used for the first time (i.e. when they are defined); italics are also used in examples.
Three exclamation marks !!! at the beginning of a paragraph are used for marking the paragraphs containing notes on the differences between the rules and the actual analysis of the data. If no such paragraph is included in a given section, it is assumed that the data conform to the rules as described.