Institute of Formal and Applied Linguistics
Charles University, Czech Republic
Faculty of Mathematics and Physics
VIADAT
Virtuální asistent pro zpřístupnění historických audiovizuálních dat
Projekt VIADAT je primárně zaměřen na vytváření metod (a souvisejících nástrojů, vesměs software) pro dokumentaci a prezentaci paměťové kultury národa, jak byla, je a bude zachycována na zvukových a audiovizuálních médiích. Projekt tedy spadá především do oblasti orální historie, vytvořené nástroje však budou umožňovat zpracování archivů audio- a videonahrávek pro následné zpřístupnění a využití jak ve vědeckém výzkumu, tak i ve vzdělávání.
Vzniklé nástroje budou tvořit softwarovou platformu („virtuálního asistenta“) pro zpracování, anotace či obohacení („enrichment“) a zpřístupnění audio a videonahrávek.
Partneři
Výsledky
| # | Název | Termín | Dokončeno | Typ a odkaz na výsledek ke stažení | Demo |
|---|---|---|---|---|---|
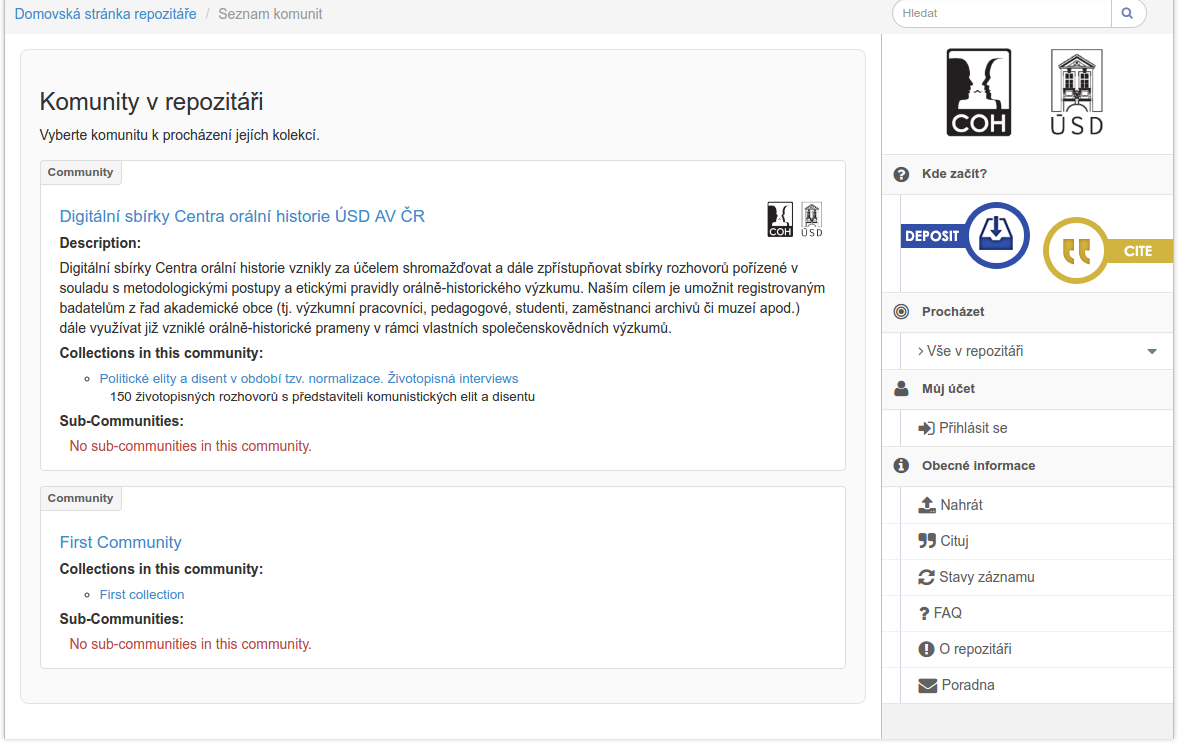
| 1 | VIADAT-REPO | 2016-12-31 | 2016-12-31 | software |
|
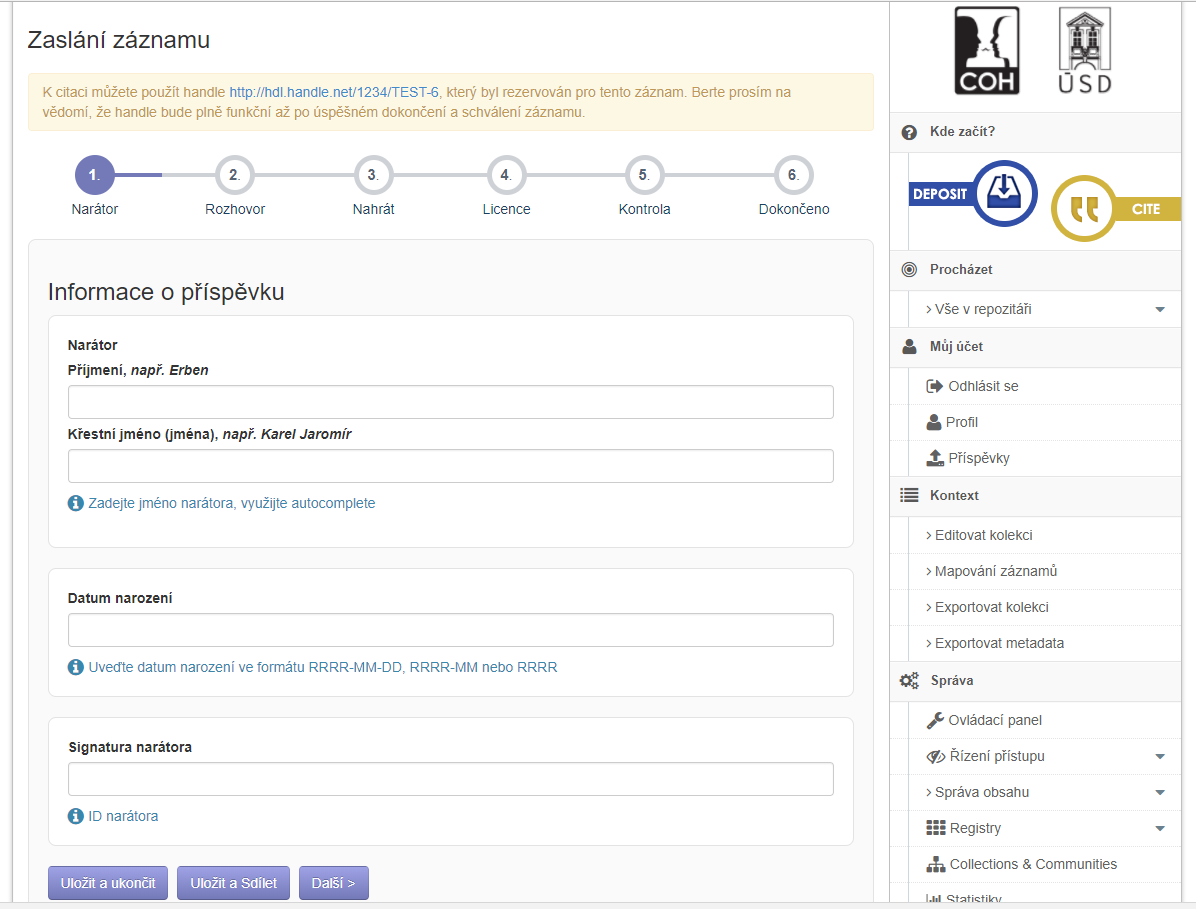
| 2 | VIADAT-DEPOSIT | 2017-12-31 | 2017-12-31 |
|
|
| 3 | VIADAT-SEARCH | 2018-11-13 |
|
||
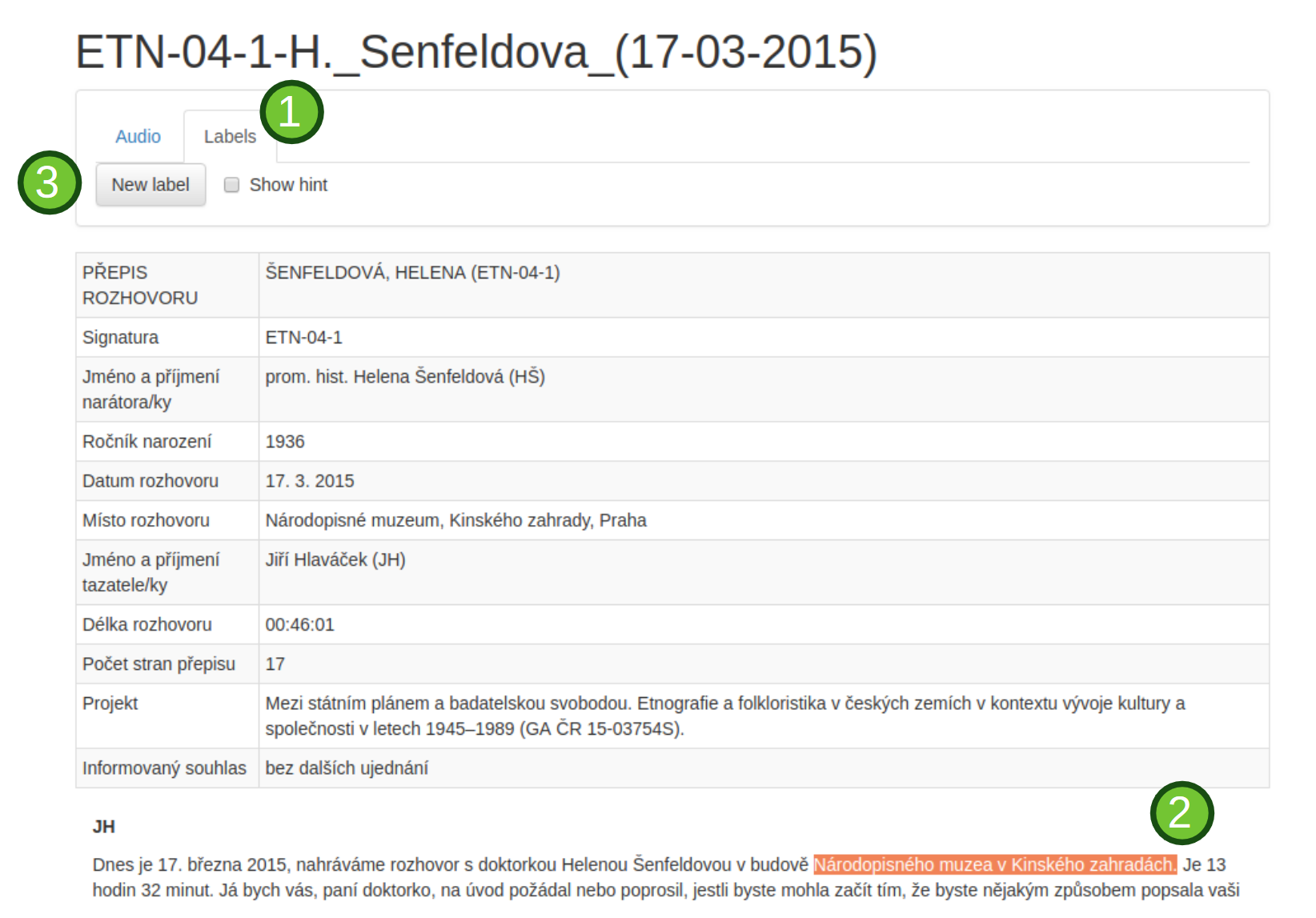
| 4 | VIADAT | 2019-12-31 |
|
||
| 5 | VIADAT-TEXT | 2019-11-14 | software | Demo viz výše (integrováno ve výsledku VIADAT) | |
| 6 | VIADAT-ANNOTATE | 2019-12-31 | software | Demo viz výše (integrováno ve výsledku VIADAT) | |
| 7 | VIADAT-ANALYZE | 2019-12-31 | software | Demo viz výše (integrováno ve výsledku VIADAT) | |
| 8 | VIADAT-STAT | 2019-12-31 | software | Demo viz výše (integrováno ve výsledku VIADAT) | |
| 9 | VIADAT-GIS | 2019-12-31 | software | Demo viz výše (integrováno ve výsledku VIADAT) |
Publications
Fučíková Eva, Hajič Jan, Urešová Zdeňka: Joint search in a bilingual valency lexicon and an annotated corpus. In: Proceedings of Coling 2016 (Demo papers), Coling 2016 conference, Osaka, Japan, Dec. 11-16, 2016. ICCL. pp. 40-44, 2016
Urešová Zdeňka, Fučíková Eva, Hajičová Eva, Hajič Jan: Syntactic-Semantic Classes of Context-Sensitive Synonyms Based on a Bilingual Corpus. In: Proceedings of 8th Language and Technology Conference, Fundacja Uniwersytetu im. Adama Mickiewicza w Poznaniu, Poznań, Poland, pp. 1-5, 2017 LTC_17.pdf
Náplava Jakub, Straka Milan, Straňák Pavel, Hajič Jan: Diacritics Restoration Using Neural Networks. In: Proceedings of the 11th International Conference on Language Resources and Evaluation (LREC 2018), European Language Resources Association, Paris, France, ISBN 979-10-95546-00-9, pp. 1-10, 2018, conference paper in PDF
Oepen Stephan, Abend Omri, Hajič Jan, Hershcovich Daniel, Kuhlmann Marco, Xue Nianwen, Chun Jayeol, Straka Milan, Urešová Zdeňka, O'Gorman Tim: MRP 2019: Cross-Framework Meaning Representation Parsing. In: Proceedings of the CoNLL 2019 Shared Task: Cross-Framework Meaning Representation Parsing Association for Computational Linguistics, Stroudsburg, PA, USA, ISBN 978-1-950737-60-4, pp. 1-27, 2019, conference paper in PDF
Straka Milan, Straková Jana, Hajič Jan: Czech Text Processing with Contextual Embeddings: POS Tagging, Lemmatization, Parsing and NER. In: Lecture Notes in Computer Science, Vol. 11697: Proceedings of the 22nd International Conference on Text, Speech and Dialogue - TSD 2019 Springer International Publishing, Cham / Heidelberg / New York / Dordrecht / London, ISBN 978-3-030-27946-2, ISSN 0302-9743, pp. 137-150, 2019, conference paper in PDF (scan, SpringerLink: behind a paywall)
Hlaváček Jiří (ÚSD AV ČR): Metodické postupy archivace orálně-historických pramenů v digitálním věku; Archivní časopis, ISSN: 0004-0398, roč. 69, č. 4 Archivni_casopis_Hlavacek.pdf
Hlaváček Jiří: (ÚSD AV ČR): Etické aspekty zpřístupňování orálně-historických pramenů (nejen) ve virtuálním prostoru; Memo - časopis pro orální historii, roč. 9, č. 2 Memo_2019_2_net.pdf