PCKIMMO is a very old but still usable program with which you can explore two-level morphology. The download links at sil.org are no longer maintained and may become unavailable, thus I am providing a copy for educational purposes here. Try to download the Linux binaries below. If that does not work for you, you may try to download the source code of PCPARSE (which includes PCKIMMO) and compile it.
wget http://ufal.mff.cuni.cz/~zeman/vyuka/morfosynt/lab-twolm/pckimmo2-binary-linux.zip unzip pckimmo2-binary-linux.zip chmod 755 bin/*
PCKIMMO comes with a decent English morphological lexicon (and rules), called Englex. Download it separately and unzip the package:
wget http://ufal.mff.cuni.cz/~zeman/vyuka/morfosynt/lab-twolm/englex.zip unzip englex.zip
If you go to the englex folder before invoking PCKIMMO, it will be easier to load lexicon and other files without specifying the full path. The englex.tak file is a start-up script for PCKIMMO that loads the necessary files. One of them is a “word grammar”, something that goes beyond two-level morphology and that we will ignore at the moment. That's why we ask PCKIMMO to “set grammar off”.
cd englex ../bin/pckimmo -t englex.tak set grammar off
Let's now test whether PCKIMMO can recognize English words. The command for recognition (analysis) is recognize and it can be abbreviated to r:
r dog `dog `dog r dogs `dog+s `dog+PL `dog+s `dog+3SG r bflmpsvz *** NONE ***
Inspect the file english.lex (especially the sections ALTERNATION and INCLUDE) and the other .lex files that are included from it. Note that names of sublexicons or continuation classes do not necessarily match names of files that contain sublexicon entries. See how different types of words are composed of morphemes from different sublexicons. All lexical paths start in the sublexicon called INITIAL, which has just two entries corresponding to empty lexical strings. Their only purpose is to provide two initial branches, one for open-class words that allow prefixes, and the other for “particles”, i.e., various types of short closed-class words that don't inflect and don't take affixes. See that the lexicon allows an unlimited number of derivational prefixes with an open-class word:
r hypermaximultiultraminidogs
hyper+maxi+multi+ultra+mini+`dog+s DEG3+DEG5+NUM4+DEG11+DEG4+`dog+PL
hyper+maxi+multi+ultra+mini+`dog+s DEG3+DEG5+NUM4+DEG11+DEG4+`dog+3SG
Now check the file english.rul, which defines the alphabet and the finite-state transducers. Identify the two transducers that are waken up when we analyze/generate plural of words such as city, baby. Check that it works as expected:
r babies `baby+s `baby+PL `baby+s `baby+3SG r babys *** NONE *** r babyes *** NONE *** exit cd ..
There is also a set of files with Czech morphology. In this case it is not a full MA, only a few toy examples. Expand it yourself!
wget http://ufal.mff.cuni.cz/~zeman/vyuka/morfosynt/lab-twolm/pckimmo-cs.zip unzip pckimmo-cs.zip cd cs ../bin/pckimmo -t cs.tak set grammar off r žena žen+a N(žena)+SG+NOM r ženy žen+y N(žena)+SG+GEN žen+y N(žena)+PL+NOM žen+y N(žena)+PL+ACC žen+y N(žena)+PL+VOC r ženě žen+e N(žena)+SG+DAT žen+e N(žena)+SG+LOC
The package covers a few feminine nouns and a few adjectives. Note how difficult it is to maintain the long-distance dependency between the superlative prefix nej- and the comparative suffix (regular or irregular)! With the tools we have so far, the only thing we can do is to partially duplicate lexicon entries and provide separate paths for comparatives. Trace them in the source files! Then check in PCKIMMO that a correct superlative (e.g., nejmladší “youngest”) is recognized, while an incorrect combination of the prefix with a base positive form (e.g., nejmladý) is rejected.
Foma is a better and more useful toolkit for morphological analysis. See a separate page with instructions how to obtain it.
See the presentation slides for more tips on using Foma. See here for a tutorial on Foma. If you run Foma in a graphical session in Linux, you can visualize the finite-state machines corresponding to your regular expressions:
foma[0]: regex ?* a ?*; 269 bytes. 2 states, 4 arcs, Cyclic. foma[1]: view net
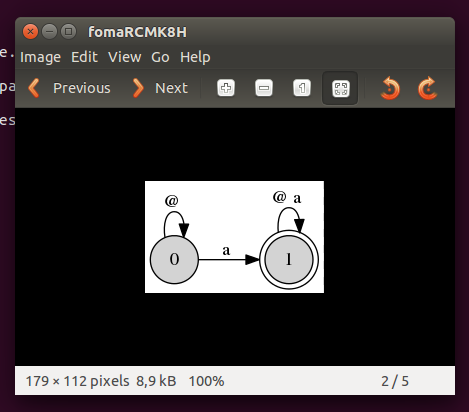
You cannot run the view net command in Windows. However, you can save the net in
a format called dot, then open that file in a third-party software and visualize your net there.
foma[1]: print dot > fst.dot
The software that can open and show the .dot file is GVEdit. It used to be part of the
Graphviz for Windows package but it is no longer part of their releases. Fortunately, you can still download
and install version 2.38
of Graphviz, which includes GVEdit.
Alternatively, use the current version of Graphviz (file "windows_10_msbuild_Release_graphviz-9.0.0-win32.zip" from here) without GVEdit, use the dot command (which is still included there) to create a PNG file with the network, then view the PNG file using your system's default image viewer. Make sure the Graphviz folder is in your PATH, otherwise your command line will not find dot.
foma[1]: print dot > fst.dot
In another command line window, go to folder where your project is (and where the fst.dot file was just generated) and run
on Windows:
dot fst.dot -Tpng -o fst.png & start fst.png
on Mac:
dot fst.dot -Tpng -o fst.png ; open fst.png
If your PNG image is too small, try adding the -Gdpi=192 option in your dot command, which doubles up the image dimensions by changing the dpi value (default is 96).
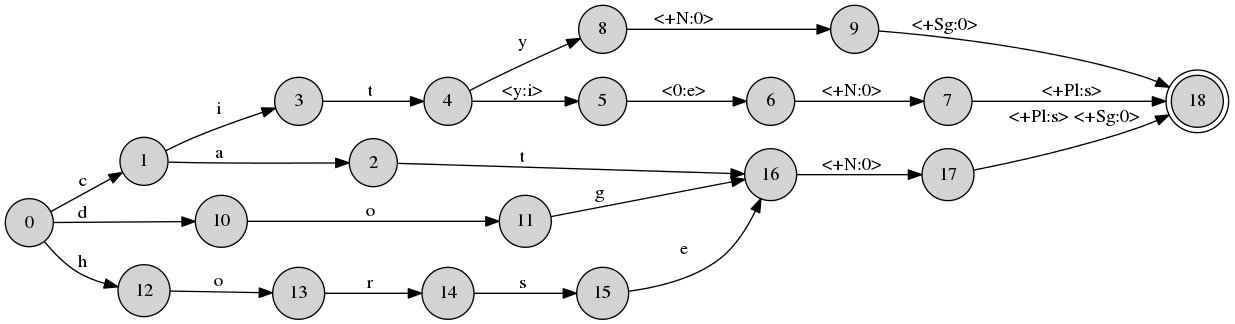
You can download a zip file that contains some of the toy examples I show in the class. Try en2.lexc with the additional rule for the plural type city-cities:
wget http://ufal.mff.cuni.cz/~zeman/vyuka/morfosynt/lab-twolm/foma-data.zip unzip foma-data.zip cd foma-data foma foma[0]: read lexc en2.lexc Root...1, Noun...4, Ninf...2 Building lexicon... Determinizing... Minimizing... Done! 896 bytes. 14 states, 17 arcs, 8 paths. foma[1]: define Lexicon; defined Lexicon: 896 bytes. 14 states, 17 arcs, 8 paths. foma[0]: define YRepl y -> i e || _ "^" s; defined YRepl: 772 bytes. 6 states, 23 arcs, Cyclic. foma[0]: define Cleanup "^" -> 0; defined Cleanup: 332 bytes. 1 state, 2 arcs, Cyclic. foma[0]: regex Lexicon .o. YRepl .o. Cleanup; 1.1 kB. 19 states, 23 arcs, 8 paths. foma[1]: view net
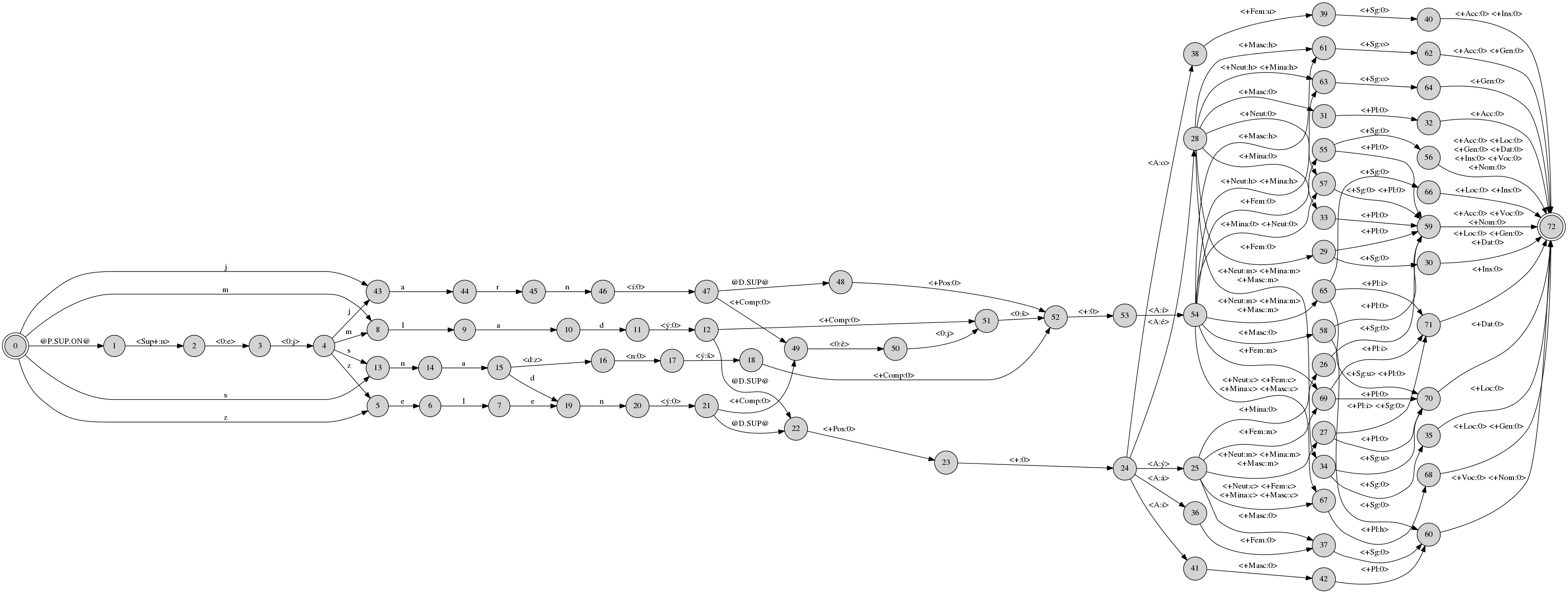
Here is a net that solves the long-distance dependency between Czech superlative prefix and comparative suffix using flag diacritics @P.SUP.ON@ and @D.SUP@:
Foma can be run in batch mode and process a list of words from a corpus.
foma[1]: save stack en.bin Writing to file en.bin. foma[1]: exit echo begging | flookup en.bin begging beg+V+PresPart echo beg+V+PresPart | flookup -i en.bin beg+V+PresPart begging
Model case-number inflection of the Czech feminine noun koza “goat”. Use one sublexicon for the stem koz and another sublexicon for the suffixes a, y, e, u, o, ou, ám, ách, ami. Add a special lexical symbol ^ to represent the morpheme boundary at the beginning of each suffix. Add another special lexical symbol λ to represent the empty suffix for genitive plural. Use simple rewrite rules to get rid of the lexical-only symbols on the surface.
Enhance your lexicon by adding multicharacter lexical symbols that represent the grammatical meaning of suffixes: +Sg for singular, +Pl for plural, +Nom, +Gen, +Dat, +Acc, +Voc, +Loc, +Ins for the cases. Also, make the stem sublexicon two-level, with full lemma and part-of-speech in the upper level (e.g., koza+NF) and the actual stem in the lower level (e.g., koz). Thus when analyzing the word kozou, you will get koza+NF+Sg+Ins on output.
Add another feminine noun, straka “magpie”, using the same set of suffixes as for koza. Use a rewrite rule to handle the k:c change before the ^e suffix.
Add another feminine noun, matka “mother”. Same set of suffixes, the k:c rule applies, too. In addition, you need a rule that will insert a surface -e- in genitive plural: matek. Note that it is not completely predictable when the vowel should be inserted and when not, so it has to be noted in the stem. For example, for srnka “doe” we have srnek, but for banka “bank”, the genitive plural form is bank.
Try two different ways of solving the -e- insertion in genitive plural:
Here is Fran Tyers' tutorial on HFST, the Helsinki Finite-State Toolkit. We do not cover it in our class and it is not used in our homework but you may find it useful if you come across an existing description of a language that is compatible with HFST but not with Foma.
Build a partial morphological analyzer for a language of your choice (this is probably the language from your first homework because you need a lexicon and you built a lexicon there). Use either Foma or PCKIMMO, convert your lexicon to the form required by the host program and supply the necessary phonological rules. The resulting MA system will expect/generate word forms on the lower side (e.g. Czech ženě) and output/expect lexical strings on the upper side, which contain information about the lemma, part of speech, morphological features (e.g. N(žena)+SG+DAT; the documentation to your solution should describe how your lexical strings are composed and what are the meanings of their parts). Note: It is actually expected that you use Foma, which is much more comfortable to work with. However, using PCKIMMO is allowed too.
Your analyzer should know at least two morphologically interesting parts of speech (nouns, adjectives, verbs). If you select a Slavic language, cover at least two of the following subsets:
If you select a non-Slavic language, do something comparably difficult. Obviously, covering suffixes of nouns in English is not as exhausting as in Czech, so you would have to extend your solution in another way in order to get the same score as for Czech. The extent sketched above corresponds to a 14-point task; if you do less or more, I will try to adjust your points accordingly.
Expanding the lexicon is not the main focus of this task (because it was the topic of another task, and you already received points for it). You are now supposed to invest more effort into covering as many inflection patterns as possible. If your lexicon lacks words in a particular inflection class you need to cover, just add a few model examples.
Send me the files with your lexicon and phonological rules. Add a shell script that will invoke Foma (PCKIMMO) with these files and analyze all words in an input file; add a sample input file for the script. Documentation: Add a few paragraphs where you describe your decisions and point out the most interesting or difficult phenomena. Do not forget to describe the format of your lexical string (see above). For each inflection class list example words that your analyzer knows and that can be used for testing. Pack it all using zip and send it to zeman@ufal.mff.cuni.cz.
Deadline: see the main page of the course.