Technology for NLP
NPFL092
Zdeněk Žabokrtský & Rudolf Rosa
{zabokrtsky,rosa}@ufal.mff.cuni.cz
Tuesday 9.00–11.20
SU2
Introduction to XML, Part 2
- Namespaces
- XPath
- Transformations
- API: SAX & DOM
XML Namespace
- Tags from various DTDs in one document
- fragments of a XHTML document in another XML
document
- tags for transformation instructions mixed with the
tags of the document to be transformed
- Same names for tags in different DTDs → ambiguity
- W3C 1999: Namespaces
XML Namespace (cont.)
- Identified by a URL
- uniqueness
- possible pointer to futher information (does
not have to exist, though. Access to the
internet is not required)
- Fully qualified attribute/element name
Navigation in XML
- Document addressing
- URL
- protocol://computer:port/path/resource
- Inside a document
- Identifiers: relation between ID and IDREF
- XPath
+ XLink, XPointer
XPath
- Query language
- Result: set of nodes (i.e. elements, attributes, text
nodes, etc.) matching the query
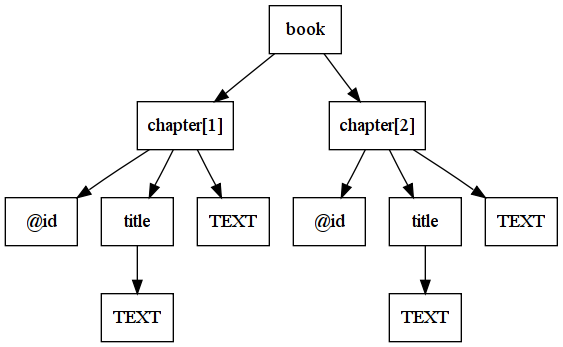
- XML document understood as a tree
- Similar to path identification on *nix file system
- Examples:
| /book
| | root element named book
|
| /book/chapter
| all elements named chapter in the root
element book
|
| /book/*
| all elements in the root element book
|
XPath (cont.)
More examples
| /*/*/*/para |
| elements para in the 4th level
|
| //chapter
| elements chapter anywhere in the document
|
| //bold | //italic
| all elements bold or italic anywehere
in the document
|
| /book/chapter[2]
| the second chapter
|
| /book/chapter[last()]
| the last chapter
|
| //chapter[@id="ch2"]
| The chapter(s) whose attribute id has the value "ch2"
|
| ../@lang
| attribute lang of the parent of the current node
|
| //*[count(para)=3]
| all elements that contain exactly three para elements
|
| //chapter/para[position()<3]
| the first two paragraphs of every chapter
|
| //song[@lang="en"]/title
| titles of all the English songs
|
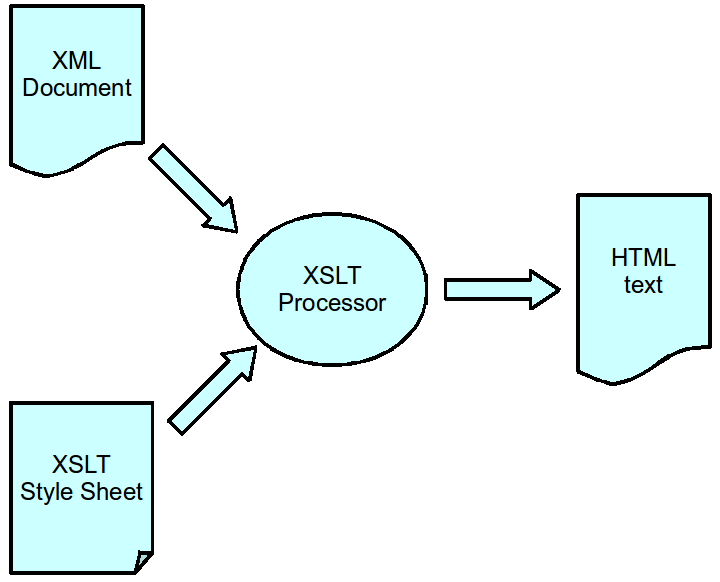
XML Transformations
- Why?
- Presenting the content of an XML document (users are not
interested in tags)
- Style (style sheet)
- Relation between logical structure of a document and its
presentation form
- XSL = eXtensible Stylesheet Language
- Description of transformations of XML documents
- XSLT = XSL Transformation
- Transforming process realized by an XSLT processor
xsltproc test.xsl test.xml > test.html
XSL
- Stylesheet declaration
- XML document in
xsl namespace
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
… declaration of templates …
</xsl:stylesheet>
- Style body
- At least one transformation rule (“template”)
- Matching expression: finds nodes to apply the
template on
- Output: found nodes substituted by the specified
output
<xsl:template match="matching_expression">
… output …
</xsl:template>
XSL Example
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<html>
<head></head>
<body>
<xsl:apply-templates/>
</body>
</html>
</xsl:template>
<xsl:template match="chapter">
<h1>
<xsl:number/>.
<xsl:value-of select="title"/>
(id = <xsl:value-of select="@id"/>)
</h1>
<p>
<xsl:apply-templates/>
</p>
</xsl:template>
<xsl:template match="title"/><!-- do not process again -->
</xsl:stylesheet>
<book>
<chapter id="k1">
<title>Intro</title>
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
</chapter>
<chapter id="k2">
<title>Conclusion</title>
Etiam euismod scelerisque dapibus.
</chapter>
</book>
API for XML
Application programming interface
- SAX—Simple API for XML
- a document is read serially
- its contents are reported as “callbacks”
- fast and efficient to implement, but user applications
have to keep track of the current position
- DOM—Document Object Model
-
- navigation of the entire document
- a document represented as a tree of objects
- language-neutral interface to an in-memory representation
SAX Event Handlers in Perl
Each type of event is processed by a subroutine with a dedicated name:
- start_document
- end_document
- start_element
- end_element
- characters
- processing_instruction
- comment
- start_cdata
- end_cdata
- entity_reference
SAX in Perl: an Example
use warnings;
use strict;
use Data::Dumper;
use XML::SAX;
use XML::SAX::Writer;
my $out;
my $writer = XML::SAX::Writer->new(Output=>\$out);
my $filter = Element_Attribute_Counter->new(Handler => $writer);
my $parser = XML::SAX::ParserFactory->parser(Handler => $filter);
$parser->parse_uri($ARGV[0]);
print "$out\n",Dumper $filter->get_count;
package Element_Attribute_Counter;
use base qw/XML::SAX::Base/;
use Scalar::Util qw/refaddr/;
my %count;
sub start_element {
my ($self,$element) = @_;
my $addr = refaddr $self;
$count{$addr}{$element->{Name}}++;
my $attributes = $element->{Attributes};
foreach my $attribute (keys %$attributes) {
$count{$addr}{"@".$attributes->{$attribute}{Name}}++;
}
$element->{Name} = uc $element->{Name};
$self->SUPER::start_element($element);
}
sub get_count {
my $self = shift;
return $count{refaddr $self};
}
XML::Twig — Using Handlers
use warnings;
use strict;
use XML::Twig;
use Data::Dumper;
my %count;
sub element_handler {
my ($self, $current) = @_;
$count{ $current->name }++;
$count{ '@' . $_ }++ for $current->att_names;
$self->purge;
}
my $twig = XML::Twig->new(
twig_handlers => {
"*" => \&element_handler,
}
);
$twig->parsefile($ARGV[0]);
print Dumper \%count;
XML Pulldown Parser — XML::LibXML::Reader
use warnings;
use strict;
use XML::LibXML::Reader;
use Data::Dumper;
my %count;
my $reader = XML::LibXML::Reader->new(location => $ARGV[0])
or die "Cannot read $ARGV[0]\n";
while ($reader->nextElement) {
$count{$reader->name}++;
if ($reader->hasAttributes) {
$reader->moveToFirstAttribute;
do {{
$count{'@' . $reader->name}++;
}} while $reader->moveToNextAttribute == 1;
}
}
print Dumper \%count;
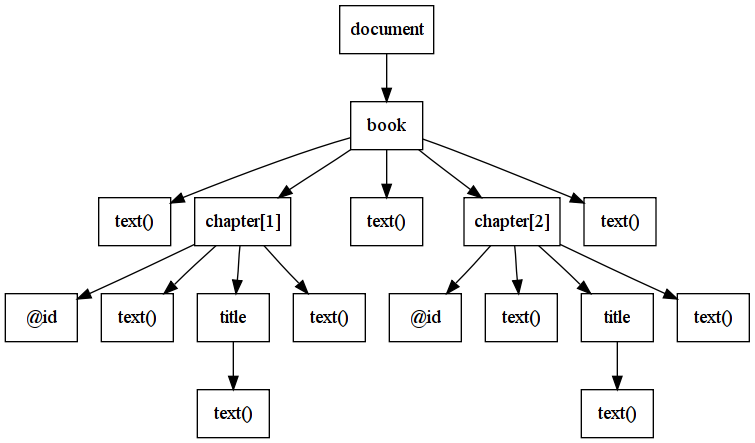
DOM
- XML document as a tree, elements, attributes and text as
nodes
- Entire document is a document node
- Every XML tag is an element node
- Text contained in an element is a text node
- Every XML attribute is an attribute node
- Comments are comment nodes, etc.
DOM in Perl
XML::DOM uses the expat library
use strict;
use warnings;
use XML::DOM;
my $parser = XML::DOM::Parser->new();
my $doc = $parser->parsefile('book.xml');
foreach my $chap ($doc->getElementsByTagName('chapter')) {
print 'Attribute id contains: ', $chap->getAttribute('id'), "\n";
foreach my $child ($chap->getChildNodes) {
my $type = $child->getNodeType;
if ($type == ELEMENT_NODE) {
print 'Element ', $child->getTagName,
' contains: ', $child->getFirstChild->getNodeValue,
"\n";
} elsif ($type == TEXT_NODE) {
print 'Text: ', $child->getNodeValue, "\n";
}
}
}
XML::LibXML
Similar to XML::DOM, but uses the libxml library
use warnings;
use strict;
use XML::LibXML;
my $doc = XML::LibXML->load_xml(location => 'book.xml');
for my $chap ($doc->getElementsByTagName('chapter')) {
print 'Attribute id contains: ', $chap->getAttribute('id'), "\n";
foreach my $child ($chap->getChildNodes) {
my $type = $child->nodeType;
if ($type == XML_ELEMENT_NODE) {
print 'Element ', $child->nodeName,
' contains: ', $child->getFirstChild->nodeValue,
"\n";
} elsif ($type == XML_TEXT_NODE) {
print 'Text: ', $child->nodeValue, "\n";
}
}
}
XSH
XML::XSH2 is built on top of XML::LibXML
open book.xml ;
my $ch := insert element chapter append book ;
insert attribute 'id="a"' into $ch ;
insert attribute 'nonumber=1' into $ch ;
insert chunk "<title>Appendix</title>" prepend $ch ;
insert text "Quamquam sunt sub aqua, sub aqua maledicere temptant." append $ch ;
insert text {"\n"} after /book/chapter[last()] ;
echo "<html><head></head><body>" ;
my $count = 0;
for my $ch in /book/chapter {
echo "<h1>" ;
if not($ch[@nonumber=1]) echo :s {++$count} "." ;
echo :s $ch/title " (id = " $ch/@id ")</h1>" ;
for $ch/text() echo "<p>" (.) "</p>" ;
}
echo "</body></html>" ;
XML in NLP
- Prague Dependency Treebank 2.0
- Tiger
- Penn Arabic Treebank
- Hyderabad Treebank
⋮
Alternatives to XML
Not a markup language, but a human readable data exchange format:
- JSON (a subset of
YAML)
- YAML:
available also for C++, Haskell, Java, JavaScript, PHP, Python,
…