Tutorial on Bonito
The graphic tool Bonito simplifies tasks commonly associated with language corpora, especially searching within them
and calculating basic statistics on the search results. Bonito is a system upgrade of the corpus manager Manatee, which conducts various
operations on corpus data. A detailed documentation for the Bonito tool is included in the application itself and can be launched from the main
Help menu.
Figure 1 illustrates the Bonito main screen. The command of the tool is demonstrated in the following examples.
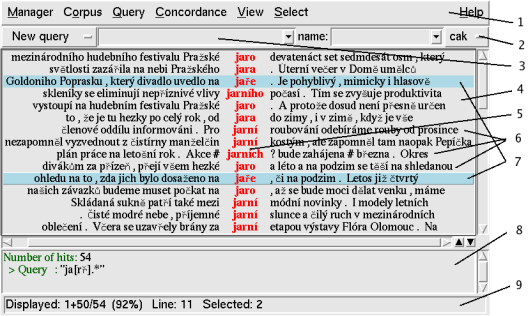
Figure 1 description
1 Main menu
2 Corpus selection button
3 Query line
4 Main window displaying query results
5 Column of the appropriate query results
6 Concordance lines
7 Selected concordance lines
8 Window displaying query history and broader context
9 Status line
Users are often interested in what context the chosen words are in that occur in the corpus. For example, a user may want
to investigate the different contexts of the occurrence of the word
jaro (spring). The user can enter this word into window “3” (query box/new query) and press
Enter. After submitting the query, the answer is displayed in the main window “4” in the form of the concordances. All occurrences of the chosen word will be displayed in the contexts found in the corpus. The displayed rows are referred to as concordances or concordance rows (“6”).
To generate more targeted concordances, the query can also be in the form of a simple regular expression. For example, all forms of the word
jaro (spring) can be attained by entering the regular expression ja[rř].* (See Figure
1). All desired forms of the word will be found by this query, but also unwanted results can be (and will be in this case) found as well. For example forms of the adjective
jarní (spring) or noun jarmark (fair, market). In case the result set is not exceedingly large and contains just a few undesirable concordances, one can manually delete these concordances by selecting the rows with a left click of the mouse followed by the menu command
Concordance|Delete selected. One can also invert the selection of the rows and
change emphasised and un-emphasised (command Select|Invert) words.
We would recommend changing the regular expression so that the results exactly match the desired set of word forms (e.g.
ja(ro|ra|ře|ru|rem|r|rech|rům|ry)), but this option might be too complex. The options
P filter (positive filter) or
N filter (negative filter) bring about another possibility of narrowing the set of results. Filters can be selected by clicking the
New query button and selecting the desired filter. Example: all occurrences of the word forms of the adjective
jarní represent the results of the query
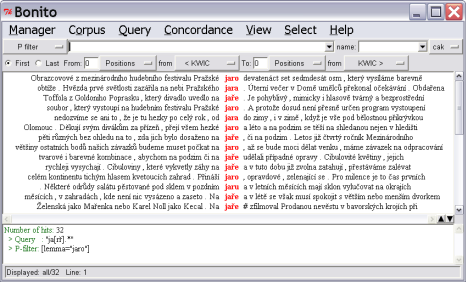
jarn.+, and therefore can be omitted by entering this query into the negative filter. The best solution would be entering the query
[lemma="jaro"]into the
P filter. In this way we reduce the set of results only to the occurrences with the value “jaro (spring)” in the attribute lemma – see Figure
2. Notice the history of the query in the lower window “8” in the same figure. Of course, the user could have entered the query
[lemma="jaro"] at the very beginning. But the result would differ from the results of the procedure described above.
We have only been searching for the forms of the lemma
jaro beginning with the lower case letter. The query of the lemma will result in
all occurrences of the form of that lemma, including those beginning with the upper case letter, e.g. at the beginning of a sentence.
Please note when using a lemma for searching that some lemmas are enhanced with additional information, especially sense differentiation is specified for homonymous lemmas (e.g. lemma
stát-1_^(státní_útvar) (state) and stát-2_^(něco_se_přihodilo)
(to happen). Therefore a query
[lemma="stát"] would generate zero results. It will be necessary to formulate the query using the regular expression
[lemma="stát.*"]– especially in case we are not sure about the form of the lemma. All lemmas beginning with the string
stát will be found: including the two lemmas specified above and also other lemmas, for example
státní. The desired concordances can be then selected using the P or N filter (see above).
As is evident from the previous examples, it is possible to formulate increasingly complex queries and combine these values with all attributes that the corpus has defined. The user can display all the attributes by selecting the command
Information summary from the
Corpus menu. Besides the operator
= for equality, also the operator
!= for non-equality can be used. Table
1 below describes the attributes.
Table 1 Bonito: CAC 2.0 attributes
| Attribute name | Description |
word |
Word form |
lemma |
Basic word form, lemma |
tag |
Morphological tag |
num |
Word form order in the sentence |
afun |
Analytical function |
tparentform |
Direct parent |
tparentnum |
Order of the direct parent in the sentence |
eparentform |
Effective (linguistic) parent |
eparentnum |
Order of the effective (linguistic) parent in the sentence |
The only implicit attribute that can be modified by the user is the attribute
word. For this reason, it was sufficient in the examples above to submit only the word
jaro into the query box without any specification of the attribute.
The user can also employ a combination of attributes in the search. The following query
[lemma="jaro" & tag="NNN.6.+" & word="j.+"] will return all occurrences for the lemma
jaro that occur in locative (plural and singular since the position of the number in the character is filled with full stop) and begin with a lowercase letter. The query for the lemma will also search for occurrences of the lemma at the beginning of a sentence, something we could not do with the previous query.
The formation of optimal queries is paramount to generating the most relevant results in the Bonito tool. Minor oversights or omissions of square brackets, quotation marks, or whitespaces can lead to an empty or unanticipated search result. To reduce the occurrence of such errors, a graphic editor is provided to generate more illuminating and error free formation of queries and can be launched through the menu
Query | Graphical Construction. However, more experienced users may find it more efficient to manually enter queries directly into the query box rather than using the graphic editor.
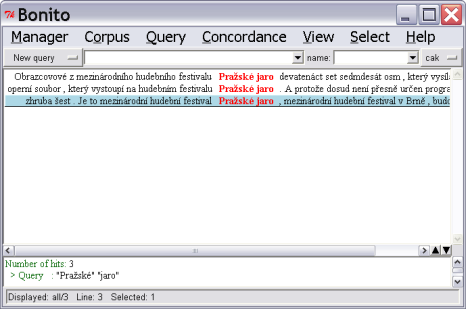
It is also possible to search for more than one word at the same time. You can enter them simply as a new query.
The words of the query need to be separated by white spaces (see Figure 3).
Pay special attention when
searching for non-alphanumeric characters, as they can have special roles in regular expressions. Question marks and full stops can especially
cause different query behaviour. In order to search for these characters in a query expression they must be set apart with a slash “\” symbol such
as \? to search for a question mark. Similarly enter
\.for a full stop. By putting down just a full stop, the result will search for all positions of
the corpus with just one character (and full stops will be one of them).
If you double click on the concordance row, a broader context will be displayed in the lower window (see Figure 3). In the main window not only concordances are displayed – also attributes for individual words that are defined for the corpus (left-click into the bottom window first). The selection of attributes can be made via
the View | Attributes command. Additionally, a name of the source document from which the concordance comes can be displayed for each row (
View | References).
Using the
View | Context command it is possible to change the size of the context, i.e. number of words, characters or sentences displayed. The item
View | Range enables the automatic selection of the given number of rows. This is extremely useful
for searches that have numerous results with many rows that would be difficult to inspect manually. The selection of a random sample
of data is possibly used most frequently.
You can classify concordances according to the returned word form or even according to words found in both the left and right context (Concordance | Simple Sort). Classifying can also be quite complex when done according to additional criteria (
Concordance | Generic Sort). After selecting the functions mentioned above, the windows with selection of the appropriate parameters are displayed.
The result of any modified, partially deleted, or classified query in the main window can be exported into the file (
Concordance | Save to File) for further usage.
Finally, it is worth noting that there are many useful statistics functions accessible through the menu
Concordance | Statistics. The item
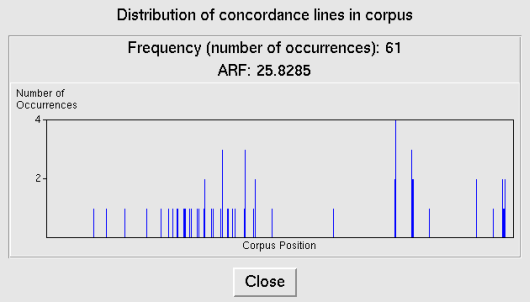
Distribution Overview will display a new window with a graph depicting the distribution of the searched concordances within the frame of the entire corpus
(see Figure 4). It is immediately evident from the diagram whether the occurrences are distributed evenly or not. The window will also contain a numerical value expressing the average reduced frequency
which is a more objective expression of inequality of the distribution of occurrences.
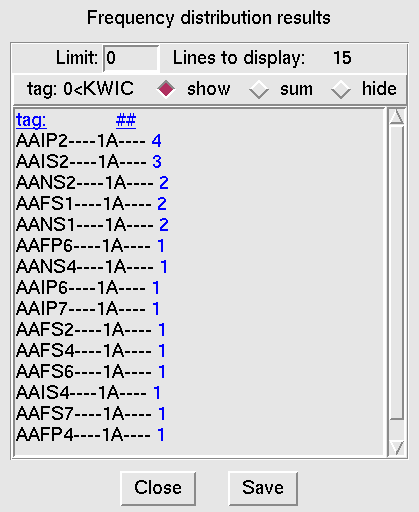
The menu Frequency distribution will display the chosen attributes of the found values together with their corresponding frequencies.
Figure 5 demonstrates the frequency distribution of morphological tags from the previous example for the lemma
jarní (spring.ADJ).
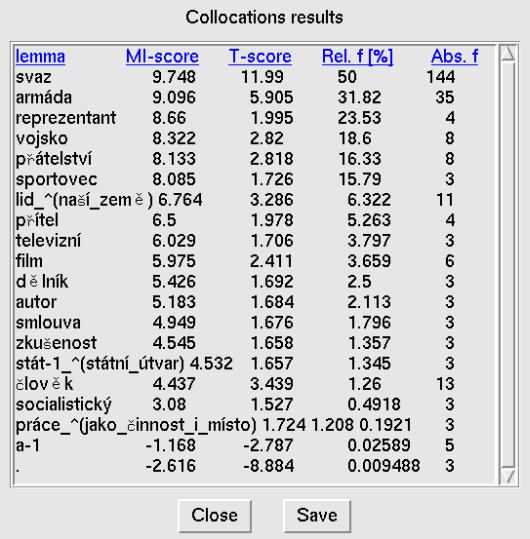
The last important statistical function we will mention here is collocation (
Concordance | Collocations). This function enables a user to view words (or lemmas or tags) occurring in the given neighbourhood of the search results
(see Figure 6 showing collocations for the lemma
sovětský (soviet) – [lemma="sovětský"]). The result is a chart
that states every word from the assigned surroundings along with its relative frequency within the frame of the found concordances by means of an MI-score and
T-score. The sequence of rows can be arranged according to categories simply by clicking on the category heading on the chart. The most important
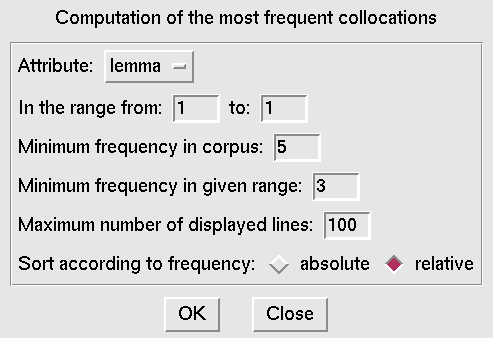
collocations are always listed towards the top. By selecting the proper values in
Figure 7
a list of the most frequent collocations is generated, as in Figure
6.
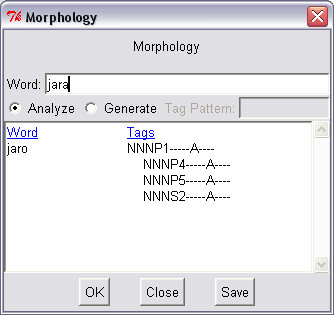
Bonito makes it possible to run the Czech morphological analyser directly through the menu
Manager | Morphology. This command opens a new window; the user can keep this window open while working
with the corpus tool. It can be used to run morphological analysis or synthesis (generating). The morphological analysis of a given word lists
all possible lemmas and tags corresponding to the entered word form. In case a synthesis is selected, the tool generates all
possible word forms that can be generated from the given lemma and the corresponding tags. See Figure
8.
Switching the interface language to English (Czech) is possible through the menu
Manager | Change language (Manažer – Změna jazyka).