Tutoriál o nástroji Bonito
Grafický nástroj Bonito
ulehčuje uživatelům práci s jazykovými korpusy, zejména
při vyhledávání a při základních statistických výpočtech
nad vyhledanými daty. Bonito je nadstavbou korpusového manažeru
Manatee, který provádí nejrůznější operace nad korpusovými daty.
Podrobná dokumentace k nástroji Bonito je součástí nástroje
samotného a vyvolá se z hlavního menu Nápověda.
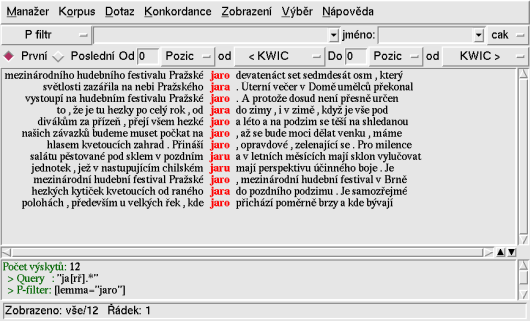
Hlavní obrazovka Bonito je uvedena na obrázku 1. Základní ovládání nástroje ukážeme na konkrétních příkladech.

Vysvětlivky k obrázku 1
1 Hlavní menu
2 Tlačítko pro výběr korpusu
3 Dotazovací řádek
4 Hlavní okno pro zobrazení výsledků dotazu
5 Sloupec s výskyty odpovídajícími dotazu
6 Konkordanční řádky
7 Vybrané konkordanční řádky
8 Vedlejší okno pro zobrazení historie dotazu a širšího kontextu
9 Stavový řádek
Uživatele
často zajímá, v jakých kontextech se slova v korpusu
vyskytují. Například ho může zajímat, v jakých kontextech
se vyskytuje slovo jaro. Zadáním tohoto slova do okénka „3“ (dotazovacího řádku) a stiskem klávesy Enter
se odešle dotaz a vzápětí se odpověď zobrazí v hlavním
okně „4“ ve formě tzv. konkordancí, tedy výskytů zadaného slova
v kontextech tak, jak se nachází v celém korpusu.
Zobrazeným řádkům říkáme konkordance nebo také konkordanční řádky („6“).
Jako dotaz může sloužit i jednoduchý regulární výraz. Například všechny tvary slova jaro lze získat zadáním regulárního výrazu ja[rř].* (viz obrázek 1).
Uvedený dotaz sice vyhledá všechny tvary, které požadujeme, ale může
se stát a v tomto případě se stane, že vyhledá i něco
nežádoucího. Třeba tvary přídavného jména jarní nebo i podstatného jména jarmark.
Není-li výsledek příliš rozsáhlý a je-li nežádoucích konkordancí málo,
můžeme je vybrat kliknutím levého tlačítka myši a poté vymazat pomocí
příkazu Smazání vybraných z menu Konkordance (Konkordance | Smazání vybraných). Také lze napřed výběr invertovat, tj. zaměnit vybrané řádky za nevybrané a naopak (Výběr | Inverze), a teprve potom invertovaný výběr smazat.
Lepší je ale buď upravit regulární výraz tak, aby výsledkem byly jenom tvary, které uživatel chce (např. ja(ro|ra|ře|ru|rem|r|rech|rům|ry)), což však může být zbytečně složité, nebo výsledek zúžit pomocí volby P filtr (pozitivní filtr) či N filtr (negativní filtr). Filtry zvolíme kliknutím na tlačítko Nový dotaz a výběrem příslušného filtru. Jestliže se např. do negativního filtru zapíše dotaz jarn.+,
odstraní se z vyhledaných konkordančních řádků všechny
výskyty odpovídající uvedenému regulárnímu výrazu, tedy v našem
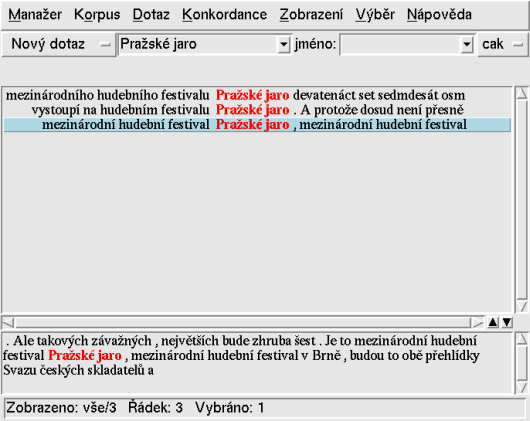
případě tvary slova jarní. Lepším řešením je P filtr, do kterého zapíšeme dotaz [lemma=”jaro”].
Tímto způsobem omezíme vyhledaný výsledek jen na ty výskyty,
u nichž se atribut lemma rovná řetězci „jaro“ – viz obrázek 2.
Na stejném obrázku si všimněte historie dotazu, která
se zapisuje do spodního okna „8“. Samozřejmě jsme mohli dotaz
[lemma=”jaro”] zadat hned
na začátku. Výsledek by se ale od právě popsaného
postupu lišil. Dosud jsme totiž vyhledávali jen tvary lemmatu jaro
začínající malým písmenem. Oproti tomu dotaz na lemma vyhledá
všechny možné zápisy tvarů lemmatu, včetně těch, které obsahují velké
písmeno, např. na začátku věty. Při vyhledávání lemmat je
potřeba si uvědomit, že některá lemmata mají k sobě přidány
některé další informace, především rozlišení významů u homonymních
lemmat (např. lemma stát-1_^(státní_útvar) a stát-2_^(něco_se_přihodilo). Při zadání dotazu [lemma=”stát”] se nenalezne nic, je třeba dotaz formulovat s pomocí regulárního výrazu [lemma=”stát.*”] – zvláště když si nejsme jisti, jak přesně lemma vypadá. Vyhledají se nám všechna lemmata, která začínají řetězcem stát, tedy obě výše uvedená, ale i např. lemma státní. Požadované konkordance potom získáme upřesněním dotazu pomocí P nebo N filtru (viz výše).
Jak
je zřejmé z dosud uvedených příkladů, je možné formulovat i
složité dotazy a kombinovat hodnoty všech atributů, které jsou
v korpusu definovány. O které atributy se jedná,
zjistíme výběrem položky Souhrnné informace v menu Korpus. Kromě operátoru = pro rovnost je možno použít i operátoru != pro nerovnost. Popis jednotlivých atributů následuje v tabulce 1.
Tabulka 1. Bonito: popis atributů ČAK 2.0
| jméno atributu | popis |
| word | slovní forma |
| lemma | základní slovní forma, lemma |
| tag | morfologická značka |
| num | pořadí slovní formy ve větě |
| afun | analytická funkce |
| tparentform | přímý rodič |
| tparentnum | pořadí přímého rodiče ve větě |
| eparentform | efektivní (lingvistický) rodič |
| eparentnum | pořadí efektivního (lingvistického) rodiče ve větě |
Implicitním atributem, který si však uživatel může změnit, je atribut word. Proto stačilo v případě dosavadních příkladů zapsat do dotazovacího řádku pouze slovo jaro, aniž by se specifikovalo, o který atribut se jedná.
K vyhledání je možné použít i kombinaci atributů. Následující dotaz [lemma=”jaro” & tag=”NNN.6.+” & word=”j.+”] najde všechny výskyty lemmatu jaro,
které se vyskytují v šestém pádě (jednotného nebo i množného
čísla, protože ve značce je na pozici čísla tečka) a začínají
malým písmenem – dotaz na lemma totiž vyhledá i výskyty daného
lemmatu začínající velkým písmenem, což se nám původním dotazem,
kdy jsme hledali slovo, nikoli lemma, nepodařilo.
Dotazy je
třeba vytvářet velmi pečlivě. Vynechání hranatých závorek, uvozovek,
přidání mezer, to vše může způsobit, že nenajdete to, co hledáte.
Pro názornější a bezchybné vytváření dotazů slouží grafický editor
dotazů, který vyvoláme pomocí Dotaz | Grafické vytváření. Zadávání dotazu přímo do dotazovacího řádku je ale rychlejší.
Vyhledávat
lze i více slov najednou. Stačí je zapsat jako nový dotaz. Jednotlivá
slova je třeba v dotazu oddělit mezerami (viz obrázek 3).
Pozor při vyhledávání nealfanumerických znaků, které mají svůj
význam v regulárních výrazech. Jedná se především
o otazník a tečku. Chcete-li nalézt skutečně znak ?, který
v korpusu ČAK 2.0 zastupuje vynechané slovo, je třeba zapsat
do dotazovacího řádku \?. Podobně pro tečku \..
Zadáním samotné tečky by se vyhledaly všechny pozice korpusu,
na nichž je jediný znak (tečky mezi nimi budou také).
Dvojitým kliknutím na konkordanční řádek se ve spodním okně zobrazí širší kontext (viz obrázek 3).
Zde je možné kontext rozšiřovat směrem vpřed či vzad pomocí šipky
nahoru nebo dolů (předtím je třeba do spodního okna kliknout levým
tlačítkem myši). Výběr atributů se provede pomocí Zobrazení | Atributy. Navíc lze u každé řádky zobrazit název zdrojového textu, ze kterého konkordance pochází (Zobrazení | Reference).
Pomocí Zobrazení | Kontext lze nastavit velikost kontextu – tzn. kolik slov, znaků či vět má být zobrazeno okolo každého nalezeného výskytu. Položka Zobrazení | Rozsah
zase umožňuje automatický výběr jen určitého počtu řádků. To je
užitečné zejména pro výsledky obsahující mnoho řádků, které je
náročné projít ručně. Nejčastěji se asi použije výběr náhodného
vzorku dat.
Konkordance je možné také třídit, a to jednak
podle samotného nalezeného slovního tvaru, jednak podle slov
vyskytujících se v levém či pravém kontextu (Konkordance | Jednoduché třídění). Třídění může být i poměrně složité podle více kritérií (Konkordance | Obecné třídění). Po zvolení uvedených funkcí se objeví okna, do nichž je třeba vyplnit příslušné parametry pro třídění.
Výsledek
jakkoli upraveného, promazaného a setříděného dotazu v hlavním
okně je možné uložit do souboru pro pozdější použití (Konkordance | Uložení).
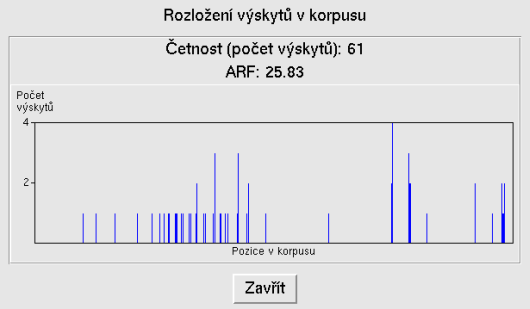
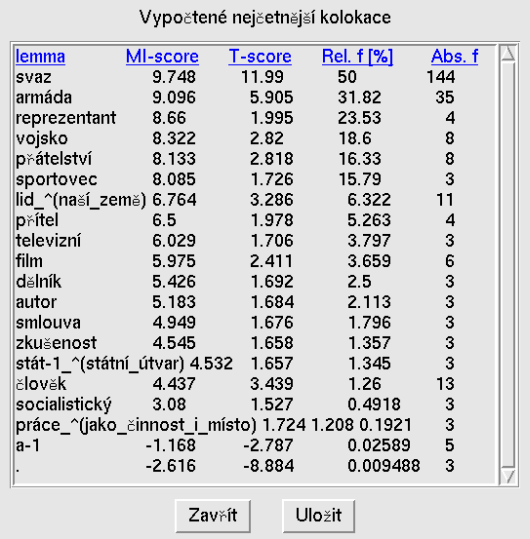
Nakonec se zmíníme o užitečných statistických funkcích, které jsou přístupné přes menu Konkordance | Statistiky. Položka Rozložení zobrazí nové okno s obrázkem znázorňujícím rozložení vyhledaných konkordancí v rámci celého korpusu (viz obrázek 4).
Z obrázku je na první pohled vidět, zda jsou výskyty
rozloženy rovnoměrně či nikoliv. V okně se zobrazí i číslo
vyjadřující průměrnou redukovanou četnost, což je objektivnější vyjádření (ne)rovnoměrnosti rozložení výskytů.
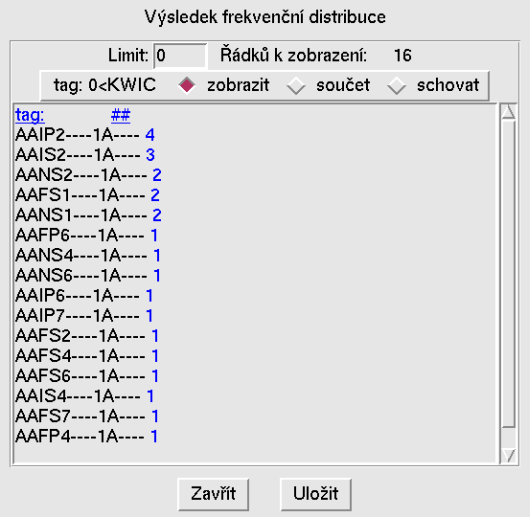
Frekvenční distribuce zobrazí vybrané atributy nalezených hodnot spolu s četnostmi. Na obrázku 5 je vidět frekvenční rozložení morfologických značek pro lemma jarní.
Poslední významnou statistickou funkcí jsou Kolokace.
Pomocí této funkce lze zobrazit slova (nebo lemmata nebo značky), která
se vyskytují v zadaném okolí nalezených výskytů (viz obrázek 6 s kolokacemi k lemmatu sovětský – [lemma=”sovětský”]).
Výsledkem je tabulka udávající pro každé slovo ze zadaného
okolí jeho frekvenci v rámci nalezených konkordancí, relativní
frekvenci, MI-score a T-score. Kliknutím na kategorii
v záhlaví tabulky se změní řazení řádků podle vybrané
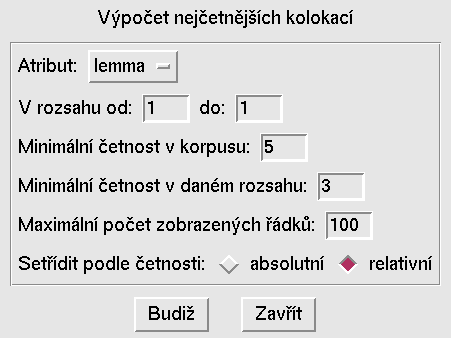
kategorie, přičemž nejvýznamnější kolokace jsou vždy nahoře. Nastavením
příslušných hodnot na obrázku 7 se vygeneruje seznam nejčetnějších
kolokací uvedených na obrázku 6.
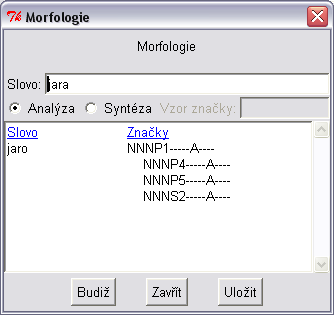
Z korpusového nástroje Bonito je možné vyvolat morfologickou analýzu, a to z menu Manažer | Morfologie.
Nové okno, které tak otevřete, si můžete nechat připravené
po celou dobu práce s korpusovým nástrojem. Můžete z něj
spouštět morfologickou analýzu nebo syntézu (generování). Morfologická
analýza zadaného slova vypíše všechna možná lemmata a příslušné značky.
Při zaškrtnutí syntézy zase dostanete všechny možné slovní tvary,
které lze ze zadaného lemmatu vytvořit, spolu s jejich
morfologickými značkami. Viz obr. 8.
Přepínání mezi anglickým a českým pracovním prostředím je možné z menu
volbou Manažer | Změna jazyka (Manager | Change language).