





Content
Node structure
Figure 1 shows the inner structure of a t-node that is not the technical root node. In this section we will go through the different attribute values the structure consists of. Some attributes have already been mentioned. Some are not filled in in this release. These will be left unexplained. The descriptions proceeds in the order of the attributes as displayed in TrEd when you double-click on a deliberate non-root node or when you let TrEd display the Side panel (View → Side panel) and do not select "Hide empty values".
References to the a-layer: Attributes a, aux.rf and lex.rf
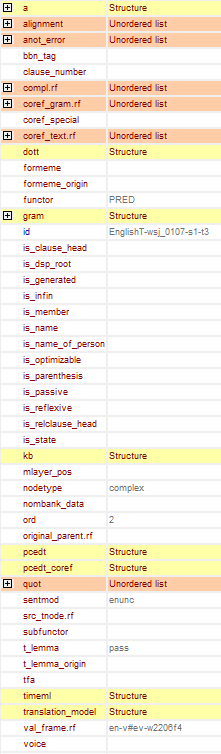
Figure 1
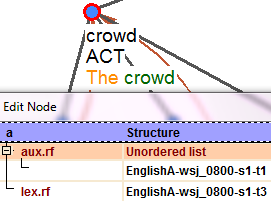
Figure 2: aux.rf refers to the and lex.rf refers to crowd
The attribute a refers to the lower (analytical) layer. Its subattributes lex.rf and aux.rf store the actual references to those a-nodes (nodes on the a-layer) that correspond to the given t-node. Content words are referred to by lex.rf, while function words by aux.rf. Note that the reference goes to the ID of the given a-node, not its lemma or form. The t-node representing the phrase the crowd in the first sentence of the file wsj_0800.treex.gz will refer to the a-nodes representing the words the and crowd as shown in Figure 2.
Reference from the free verb complement: attribute compl.rf
The aforementioned green arrow pointing from a node with the functor COMPL is the visualization of the reference, which has the form of the ID of the target node filled in the attribute compl.rf inside the COMPL node.
Attribute bbn_tag
Here are stored the entity tags from the BBN Pronoun Coreference and Entity Type Corpus.
Attribute coref_gram.rf: the grammatical coreference arrow
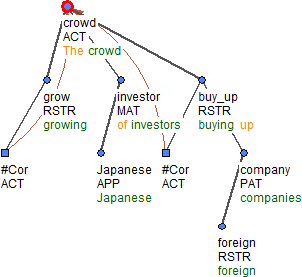
Figure 3: the growing crowd of Japanese investors is buying up foreign companies: the one who grows as well as the one who buys up something is the crowd.
The attribute coref_gram.rf and its value appear visualized as a brown arrow. This reference goes from generated nodes with the t-lemma #Cor and from relative pronouns, adjectives and adverbs (e.g. who, whose, that, which) and stands for grammatical coreference. The target of this reference is always the node that is, due to grammatical rules, unambiguously perceived as the antecedent. A typical example is the subject of a controlled verb. See Figure 3 and Figure 4 for illustration. Grammatical coreference is kept apart from the textual coreference, which, in the current PEDT 2.0 annotation largely corresponds to what is often called anaphora resolution: the relation between a referring expression and its antecedent, that is determined by the context rather than by grammatical rules.
Attribute coref_text.rf: the textual coreference arrow
The attribute coref_text.rf and its value appear visualized as a blue arrow. This reference goes from a pronoun to its antecedent (see Figure 5). The value of this attribute is the ID of the antecedent. This annotation has been taken from the BBN Pronoun Coreference and Entity Type Corpus.
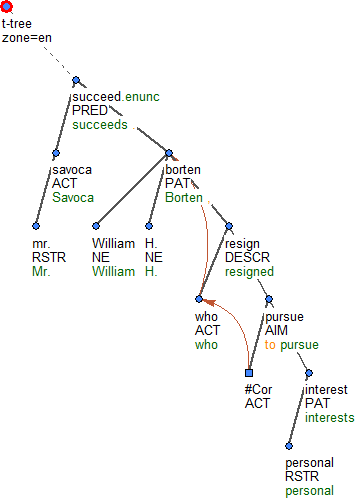
Figure 4: Mr. Savoca succeeds William H. Borten, who resigned to pursue personal interests. The word who, here used as a relative pronoun, stands for Borten. The agent of resign is also who, through which we proceed all the way to Borten again.
Attribute formeme
The attribute formeme is a user's shortcut across the layers of annotation. As mentioned before, t-nodes do not represent function words. To query the corpus for e.g. the preposition beneath on the tectogrammatical layer means to formulate the query like searching for a t-node that has an a reference of the type aux.rf to an a-node that has the attribute m/form (or m/lemma) beneath. With the attribute formeme as a shortcut, we can query the corpus directly for a t-node that has the formeme n:beneath. Strictly speaking, the attribute formeme does not comply with the Functional Generative Description, but it has proved helpful as a technical shortcut in the implementation.
Attribute functor
Functors are the semantic labels. They are listed and explained in more detail in Section Functors.
Attribute gram
Grammatemes are more fine-grained syntactic and semantic categories. They are listed and explained in more detail in Section Grammatemes.
Attribute id
Here is the ID of the given node. The usual encoding is EnglishT-wsj_file_number-ssentence_number-tnode_number. However, some node IDs have the form EnglishT-wsj_file_number-ssentence_number-anode_number. This happened when the annotator inserted a generated node (both copied and newly inserted) or chose to erase a non-generated node first but then changed his/her mind and inserted a new node representing the same token again and switched the is_generated attribute from "1" to empty.
Attribute is_dsp_root
This attribute indicates direct speech. It was not done very thoroughly in English.
Attribute is_generated
T-nodes with is_generated="1" are generated nodes. When searching the corpus exclusively for non-generated nodes, do not query the corpus for is_generated="0" but ask for nodes that do not have this attribute. The same applies to all boolean indicators (is_member, is_parenthesis).
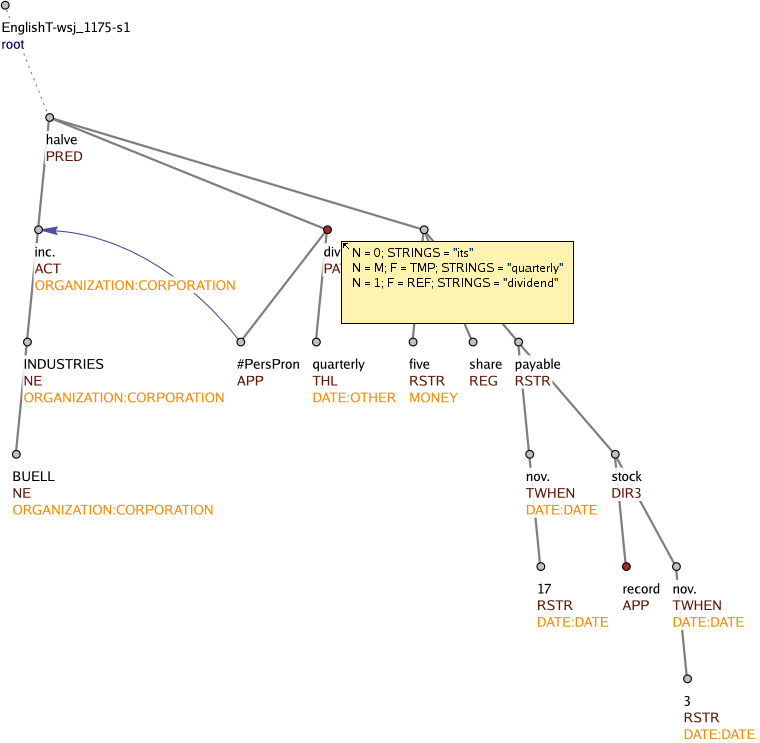
Figure 5: NomBank, coreference and entity types visualized on the tectogrammatical layer
Attribute is_member
T-nodes with is_member="1" are members of a paratactic structure, e.g. a coordination or an apposition.
Attribute is_parenthesis
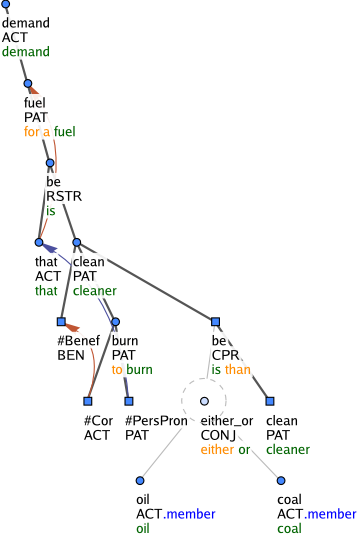
Figure 6: for a fuel that is cleaner to burn than either oil or coal
Nodes with is_parenthesis="1" are parts of a parenthetical sequence. Each node of a parenthetical subtree (including the root) has is_parenthesis="1". They can be either integrated in the syntax of the sentence (e.g. in Or did Mr. Chestman only hear a market rumor (which one may lawfully trade upon)?) or not (e.g. Such a situation can wreak havoc, as was shown by the emergency that developed in soybean futures trading this summer on the Chicago Board of Trade.). The roots of syntactically non-integrated parenthetical subtrees carry the functor PAR.
Attribute nodetype
See section Node types.
Attribute nombank_data
This attribute stores the values of the NomBank annotation.
Attribute ord
This attribute indicates the order of the node in the tree. In a full-fledged tectogrammatical annotation, the so-called deep word order indicated by this attribute would reflect the topic-focus articulation (aka information structure, TFA). In PEDT 2.0 the deep word order roughly corresponds to the surface word order (disregarding the inserted generated nodes) and carries no additional information, since the TFA annotation is not available.
Attribute sentmod
The sentmod attribute contains the information regarding the sentential modality. The sentmod attribute is relevant for the following nodes:
- root of a sentence (represented by a tectogrammatical tree)
- root of a subtree representing direct speech
- root of a subtree representing a (syntactically independent) parenthesis, the effective roots of which are assigned the functor PAR.
Attribute t_lemma
The tectogrammatical lemma of a node (further t-lemma) is one of the attributes of the node in a tectogrammatical tree (the t_lemma attribute). The value of the t_lemma attribute is either the node's lexical value (i.e. its basic form, represented as a sequence of graphemes), or an "artificial" value (the so called t-lemma substitute).
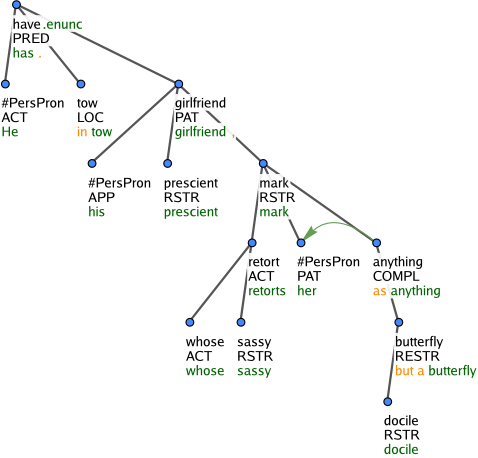
Figure 7: He has in tow his prescient girlfriend, whose sassy retorts mark her as anything but a docile butterfly.
The term t-lemma substitutes is used for artificial t-lemmas beginning with #. T-lemma substitutes are assigned in the following cases:
- Personal and possessive pronouns: Nodes representing personal and possessive pronouns have the #PersPron t-lemma.
- Syntactic negation: A node representing syntactic negation (expressed by the particle not or n't) has the #Neg t-lemma. Other expressions of negation, such as no, none, neither or even hardly, never are neglected in both languages.
- Punctuation marks and other symbols: A punctuation mark is only represented by a t-node when it has a semantic interpretation similar to a content word. A list is given below. The punctuation symbols that are not represented as t-nodes ought to be attached in the a/aux.rf references of different t-nodes. This is desirable, since one of the main rules of the annotation is that nothing present in a lower layer may get lost on the upper layer. Unfortunately, the English tectogrammatical annotation neglects almost all punctuation marks that are not represented by t-nodes (e.g. serial commas). This is to be mended in the next release.
- Ellipsis restoration: A few t-lemma substitutes are assigned to generated nodes that restore an element perceived as elided. They differ according to the type of ellipsis. The criteria for distinguishing these t-lemma substitutes are (roughly) whether or not the elided element has a coreferential antecedent in the text and which part of speech the restored node represents.
- List structures: #Forn and #Idph, which both always have is_generated="1".
- The English pro-form do: The so-called dummy-do is not regarded as ellipsis. It is represented by a t-node with is_generated="0" and the t-lemma #VerbPron. The reference to the a-node representing this token on the a-layer is a/lex.rf.
Nodes representing punctuation marks and other (non-alphanumerical) symbols have the following t-lemma substitutes:
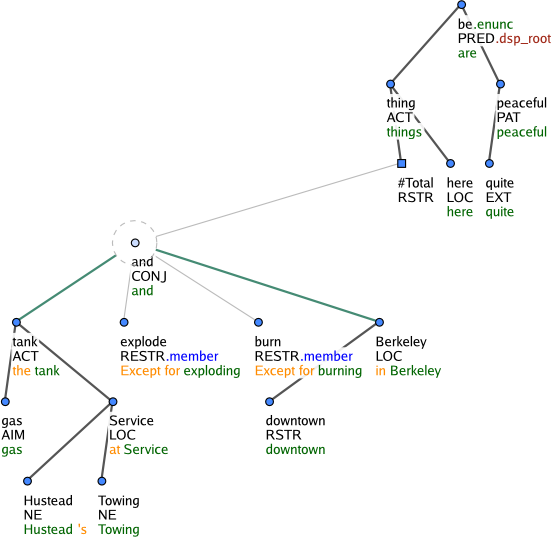
Figure 8: Except for the gas tank at Hustead's Towing Service exploding and burning in downtown Berkeley, things here are quite peaceful
- & is represented by a node with the t-lemma #Amp
- % is represented by a node with the t-lemma #Percnt
- * is represented by a node with the t-lemma #Ast
- period is represented by a node with the t-lemma #Period
- three dots is represented by a node with the t-lemma #Period3
- comma is represented by a node with the t-lemma #Comma
- colon is represented by a node with the t-lemma #Colon
- dash and hyphen are represented by a node with the t-lemma #Dash
- slash is represented by a node with the t-lemma #Slash
- semicolon is represented by a node with the t-lemma #Semicolon
- bracket is represented by a node with the t-lemma #Bracket
- missing coordinator is represented by a node with the t-lemma #Separ. Note that this node has is_generated="1", unlike the real punctuation marks!
Nodes restoring ellipsis have all is_generated="1" and the following t-lemma substitutes:
- #Gen
- #Oblfm
- #Unsp
- #Cor
- #Rcp
- #Benef
- #EmpVerb
- #EmpNoun
- #Total
- #AsMuch
- #Equal
- #Some
#PersPron, when is_generated="1", is also used to restore ellipsis, but it can also occur as is_generated="0" when representing a pronoun that is actually present on the surface.
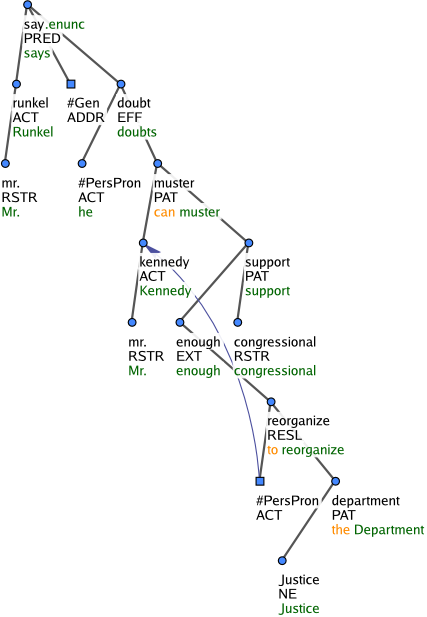
Figure 9: Mr. Runkel says he doubts Mr. Kennedy can muster enough congressional support to reorganize the Justice Department.
The t-lemma substitutes #Gen, #Oblfm, #Unsp, #Cor and #Rcp are inserted in places of missing obligatory arguments of a verb. #Gen is used for the so-called generic participant; e.g. Luis Nogales, 45 years old, has been elected to the board of this brewer. (Who elected Luis Nogales to the board?) This participant is either unknown in the text or means "anyone", "anything" or "the one normally occurring in such situations". The t-lemma #Oblfm stands for obligatory adverbials (which can be either generic or coreferential). The t-lemma #Unsp is an attempt to capture the subtle difference between purely generic arguments ("humans/things in general") and a self-understood well-defined group, e.g. of clerks at a given office: These optional 1%-a-year increases to the steel quota program are built into the Bush administration's steel-quota program to give its negotiators leverage with foreign steel suppliers to try to get them to withdraw subsidies and protectionism from their own steel industries.. (Who builds the increases into the Bush administration's steel-quota program? Most likely the Bush administration). Both #Gen and #Unsp restore an ellipsis. The t-lemma #Unsp was used only tentatively and the interannotator agreement has never been measured on this task separately. The experience tells us that the annotators have troubles drawing a line between #Gen and #Unsp. The generic/underspecifying one and they in English are captured as regular arguments (one with the t-lemma one and the personal pronouns with #PersPron, which represents they e.g. in the following sentences: Two became one flesh, as they said at the marriage ceremony, but who could say that it would be so hard. and They say the way to a man's heart is through his stomach.).
The t-lemma substitute #Cor is used e.g. for the argument of a controlled predicate that is missing due to grammatical reasons: Peter decided to leave (Peter leaves). It is generally used whenever the grammar makes the insertion of a real word impossible for the given position, but at the same time, if we were allowed to insert a word, we would be able to agree on picking just the right one from the context, since it is indicated by the grammar.
The t-lemma substitute #Rcp is used to insert a "missing" argument that is "hidden" in a reciprocal alternation. For instance, the verb kiss requires two arguments: Peter kisses Mary. This requirement is encoded in the valency lexicon. In a sentence like Peter and Mary kissed, the agent as well as the patient are in a coordination. According to the rules of the tectogrammatical representation, both (all) members must have the same label, if they are arguments (which they are here). Besides, in reciprocal constructions it is impossible to tell which argument is the agent and which is the patient. In this particular case, both Mary and Peter are marked as agents and a generated node with the t-lemma #Rcp is inserted to complete the obligatory patient slot.
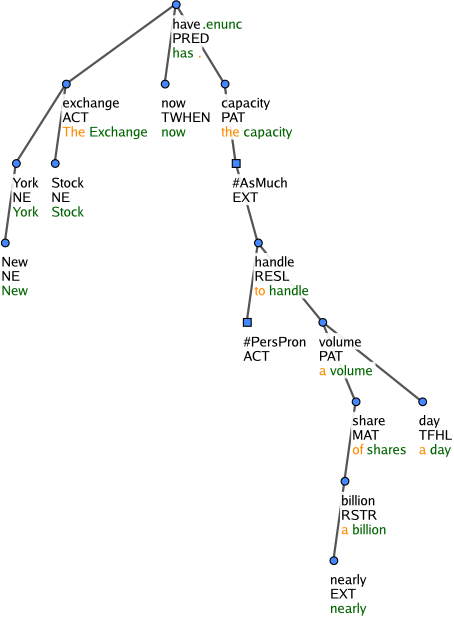
Figure 10: The New York Stock Exchange now has the capacity to handle a volume of nearly a billion shares a day.
The t-lemma substitute #Benef is mostly inserted in copular constructions with evaluative expressions, such as It is easy to forget about this case. The inserted node adds the interpretation "for somebody/humans in general" and it serves as the coreferential antecedent-beneficiary to a node with the t-lemma substitute #Cor (Figure 6).
The t-lemma substitutes #EmpVerb and #EmpNoun are inserted when a governing node to a modifier is perceived as missing. They substitute primitive concepts as have, be, go, thing, man. Both #EmpVerb and #EmpNoun have nodetype=complex.
#Total is a t-lemma substitute used to integrate a certain type of subordinate clauses that express restriction (functor RESTR). Prototypically, restrictive subordinate clauses contain a totalizer, which is a word such as all, and anything. The restriction clause depends on this totalizer. See Figure 7. There are, however, sentences where the totalizer is missing, such as Except for the gas tank at Hustead's Towing Service exploding and burning in downtown Berkeley, things here are quite peaceful (Figure 8). The naturally absent totalizer is simulated by a generated node with the t-lemma substitute #Total.
The t-lemma substitute #AsMuch is used in consecutive clauses (marked with the functor RESL) with a naturally absent quantifying expression such as enough, too (much) or (in)sufficient(ly). Compare Mr. Runkel says he doubts Mr. Kennedy can muster enough congressional support to reorganize the Justice Department. in Figure 9 vs. The New York Stock Exchange now has the capacity to handle a volume of nearly a billion shares a day. in Figure 10.
The t-lemma substitutes #Equal and #Some are used in comparative clauses that are perceived as elliptical in one way or the other (Figure 11). The annotation manuals contain a detailed explanation of ellipsis resolution in comparative clauses for further reference.
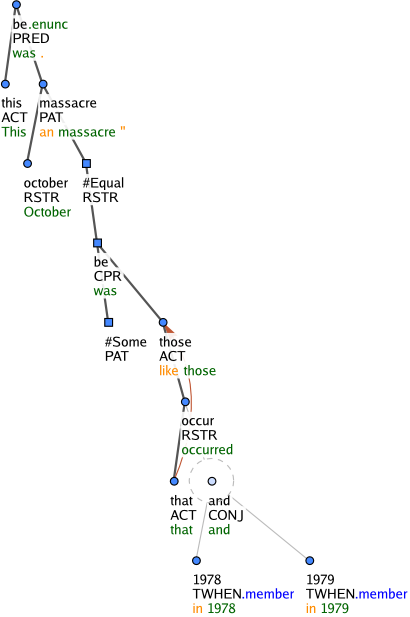
Figure 11: This was an October massacre like those that occurred in 1978 and 1979.
Lexical values in t-lemmas
The t-lemmas which are not t-lemma substitutes sometimes differ from what we normally understand under "lemma" (here "morphological lemma"). The tectogrammatical lemma is meant to present a common denominator for various syntactic and lexical derivates of words. In the English data, the t-lemmas more or less correspond to the real basic forms of words. Adjectives starting with the negation un- have t-lemmas without un-, which was done automatically. In general, the t-lemma representation is still very rudimentary in the English treebank and can be erroneous in many places.
Attribute val_frame.rf
Each occurrence of a verb is linked to a frame in the valency lexicon Engvallex, based on its syntactic behavior and semantics. The notion of valency as well as the valency lexicon are described in Section Valency.