





Introduction
Texts
The Prague English Dependency Treebank 2.0 (PEDT 2.0) is a major update of the Prague English Dependency Treebank 1.0. It is a manually parsed English corpus sized over 1.2 million running words in almost 50,000 sentences.
Data
The corpus contains the entire Penn Treebank - Wall Street Journal Section (LDC99T42). The original Penn Treebank-like file structure (25 sections, each containing up to one hundred files) has been preserved.
The corpus is enhanced with a comprehensive manual linguistic annotation in the PDT 2.0 style (LDC2006T01, Prague Dependency Treebank 2.0). The main features of this annotation style are:
- dependency structure of the content words and coordinating and similar structures (function words are attached as their attribute values)
- semantic labeling of content words and types of coordinating structures
- argument structure, including an argument structure ("valency") lexicon
- ellipsis and anaphora resolution.
This annotation style is called tectogrammatical annotation and it constitutes the tectogrammatical layer in the corpus. For more details see below and documentation.
Annotation
The resulting manual tectogrammatical annotation was built above an automatic transformation of the original phrase-structure annotation of the Penn Treebank into surface dependency (analytical) representations, using the following additional linguistic information from other sources:
- PropBank (LDC2004T14)
- VerbNet
- NomBank (LDC2008T23)
- flat noun phrase structures (by courtesy of D. Vadas and J.R. Curran)
- BBN Pronoun Coreference and Entity Type Corpus
For each sentence, the original Penn Treebank phrase structure trees are preserved in this corpus together with their links to the analytical and tectogrammatical annotation.
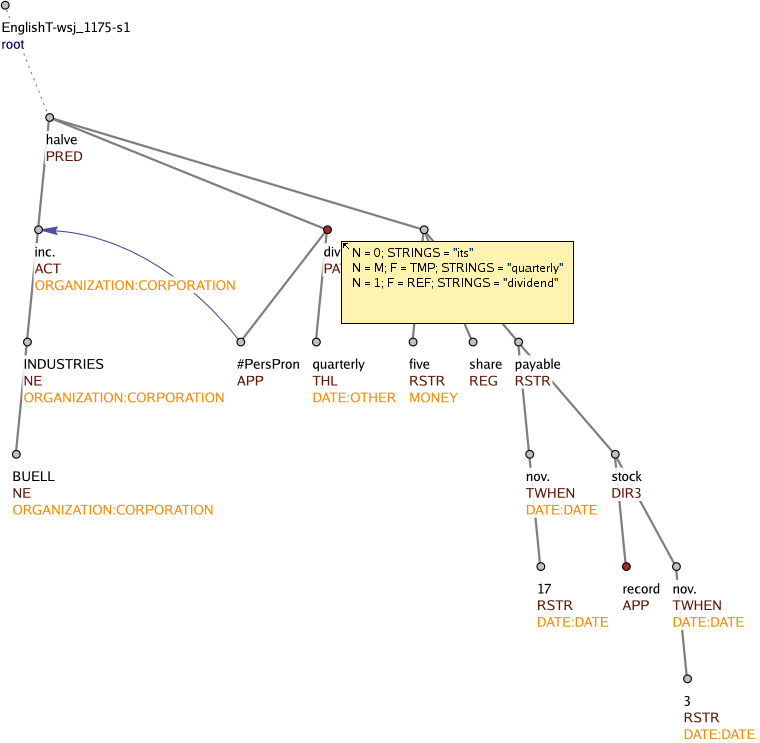
Figure 1: NomBank, coreference and entity types visualized on the tectogrammatical layer
The NomBank annotation is visualized in TrEd, the browser and editor of PEDT 2.0 on the tectogrammatical layer as pop-up windows on sienna-colored noun nodes. The BBN pronoun coreference is also visualized on the tectogrammatical layer as blue arrows. The BBN entity types are visible on all layers. On the tectogrammatical layer they can be toggled (and switched with two other types of information) with the Ctrl+a key. Figure 1 shows the NomBank pop-up window, a pronoun coreference arrow and a number of entity tags on the tectogrammatical layer of PEDT 2.0.
Layers of Annotation
The PDT 2.0-style annotation contains multiple layers:
- w-layer
- m-layer
- a-layer
- t-layer
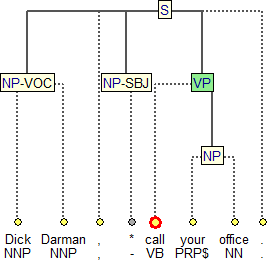
Figure 2
In addition, this corpus contains the original Penn Treebank annotation, which we call p-layer (phrase-structure layer). Figure 2 shows the visualization of a phrase-structure tree in TrEd.
w-layer
The bottom-most layer ("word" layer) is the tokenized plain text, where each token has been assigned a unique ID. This layer is fully integrated in the next upper layer, the m-layer.
m-layer
This is the morphological layer. The tokens with their IDs are automatically part-of-speech tagged and lemmatized. From this point on, we can regard the tokens as linearly ordered nodes with their respective IDs, POS-tags and lemmas. In the corpus, the m-layer is not visualized separately but rather as a part of the analytical layer (which brings the representation of syntactic dependencies along with their surface-syntactic labeling).
a-layer

Figure 3
The a-layer (analytical layer) represents the surface syntax (a parse). The syntactic dependencies are provided with labels that carry the usual syntactic information; e.g. "subject", "attribute" or "predicate complement". For more details see a brief specification of the English analytical annotation. Figure 3 presents the visualization of an analytical sentence representation in TrEd.
t-layer
The topmost - tectogrammatical - layer is a linguistic representation that combines syntax and, to a certain extent, semantics, in the form of semantic labeling, anaphora resolution and argument structure description based on a valency lexicon. This representation draws on the framework of the Functional Generative Description (Sgall, Hajičová, Panevová, 1986). The original tectogrammatical language representation in the theoretical works of the 1960s was developed mainly with rule-based text generation in mind. This annotated corpus follows the essential ideas of this formal language description, but, at the same time, it is designed to serve as training data in statistical machine learning and helps both text generation and text analysis. Compared to the complex Prague Dependency Treebank 2.0, the tectogrammatical annotation in PEDT 2.0 is slightly simplified and it, e.g., does not yet contain the topic-focus (information structure) annotation.

Figure 4
For more details see a brief specification of the English tectogrammatical annotation and a comprehensive specification of the Czech tectogrammatical annotation. Figure 4 shows a tectogrammatical sentence representation visualized in TrEd.