
Děkuji vedoucímu diplomové práce Janu Hajičovi za jeho všestrannou pomoc, cenné připomínky a rady.
Poděkování patří též Kláře Matouškové za pečlivé přečtení rukopisu a připomínky k jeho srozumitelnosti, stylu i úpravě.
Souhlasím se zapůjčováním své diplomové práce.
Prohlašuji, že jsem práci vypracoval samostatně a použil pouze uvedené literatury.
V Praze 4.4.1998 Daniel Zeman
3. PRAVDĚPODOBNOSTNÍ JAZYKOVÝ MODEL
3.3. Převod stromu na posloupnost hran
3.4. Vyloučení špatných stromů
5.3. Trénování podle hran s více variantami morfologických značek
UŽIVATELSKÁ DOKUMENTACE K PROGRAMU
Uložený jazykový model (rozdělení pravděpodobností, *.rpr)
Syntakticky rozebraný text (významové zápisy vět, *.vzv resp. *.fs)
Počítačová analýza textu v přirozeném jazyce musí zvládnout dvě základní úlohy. Jednak je potřeba zjistit, jaký význam má dané slovo ve větě, jakého je slovního druhu a jaké jsou jeho mluvnické kategorie (morfologická analýza). Druhým problémem je určení jednotlivých větných členů a stanovení závislostí mezi nimi (syntaktická analýza). Algoritmické řešení obou částí rozboru je ovšem značně obtížné, protože každý přirozený jazyk obsahuje řadu nejednoznačností. Například slovo ˙stát" může být buď podstatné jméno v 1. pádě, nebo infinitiv slovesa, a to hned se dvěma různými významy (˙stát na návsi" a ˙stát tisíc korun"). Ještě složitější je situace při syntaktické analýze, kde neexistuje žádné jednoznačné pravidlo, které by slovnímu tvaru přiřadilo jeho postavení ve větě. Určení větného členu závisí vždy i na ostatních slovech věty, případně i na kontextu dalších vět v okolí.
Provádí-li rozbor věty člověk, je vůči počítači ve výhodě: při zpracování textu je schopen vést v patrnosti obrovské množství informací o větách, které předcházely, porovnávat tyto informace s textem, který už viděl v minulosti, a nacházet analogie. Člověk tak v naprosté většině nejednoznačných případů dokáže najít správné řešení. Neuspět může pouze u krátkých a z kontextu vytržených vět. (Např. v mluveném projevu nelze rozlišit věty ˙Syn je zdravý." a ˙Syn je zdraví.".) Podotkněme však, že i v těch případech, kdy význam věty neumíme určit, existuje jediné správné řešení: je jím ten význam, který měl na mysli autor věty, když ji pronesl nebo napsal. Při počítačovém zpracování přirozeného jazyka musíme vždy počítat s určitým rizikem, že nalezený výsledek neodpovídá skutečnému významu věty.
Existují různé metody, jak provádět analýzu přirozeného jazyka; obecně můžeme rozlišit dva základní přístupy. První, klasický, se pokouší popsat jazyk co možná nejúplnější sadou pravidel a na jejich základě získávat informace o analyzované větě. Druhý, pravděpodobnostní přístup, se spoléhá na relativní četnost zkoumaného jazykového jevu v již rozebraném textu. Může-li mít nějaká věta více různých významů, vezme se v úvahu ten nejpravděpodobnější. Oba přístupy je možné i kombinovat, chceme-li pravděpodobnostní model dodatečně spoutat mluvnickými pravidly, která považujeme za neměnná.
Pravděpodobnostní metody jsou nasazovány při nejrůznějších lingvistických aplikacích zejména v poslední době, přičemž zkoumaným jazykem je nejčastěji angličtina.
Cílem této práce je aplikovat pravděpodobnostní postupy na rozbor věty v českém jazyce.
Vrchol vi stromu M (s výjimkou kořene) odpovídá právě jednomu slovu věty S. Obsahuje základní tvar slova a další informace. Přesný tvar vrcholu stanovíme později. Prozatím je podstatné pouze to, že obsahuje i původní tvar slova a jeho pořadí ve větě, takže je možné z každého syntaktického zápisu jednoznačně zrekonstruovat větu, která mu dala vzniknout.
Každý strom má v kořeni zvláštní vrchol #. Tento vrchol neodpovídá žádnému slovu ve větě a slouží pouze k označení kořene. V každém stromu je právě jeden takový vrchol. Všechny ostatní vrcholy reprezentují jednotlivá slova věty. Každý vrchol leží na i-té úrovni, kde i je jeho vzdálenost od kořene. V rámci úrovně jsou slova uspořádána podle svého pořadí ve větě. Hrany považujeme za orientované směrem od kořene k listům.
Hrana hj stromu M vyjadřuje vztah závislosti
mezi dvěma větnými členy. Je to uspořádaná dvojice významů ![]() ,
kde vř představuje řídící větný člen a vz
je závislý větný člen. Hrana ve stromu tedy odpovídá skladební dvojici
ve větě. Poznamenejme, že z definice stromu nevyplývají žádná pravidla,
která by předem říkala, jaké slovo smí na jakém záviset. Apriori tedy nevylučujeme
ani takové závislosti, které se ve skutečné větě nemohou vyskytnout, nebo
lépe řečeno, jejichž výskyt je velmi nepravděpodobný. Požadujeme však,
aby každé slovo věty bylo právě jedním větným členem, čímž se poněkud odchylujeme
od lingvistických představ o větném členu. V našem pojetí budou rovnoprávnými
vrcholy stromu např. i předložky (nikoli celé předložkové vazby), ba dokonce
i interpunkční znaménka, s nimiž musíme nakládat jako se slovy.
,
kde vř představuje řídící větný člen a vz
je závislý větný člen. Hrana ve stromu tedy odpovídá skladební dvojici
ve větě. Poznamenejme, že z definice stromu nevyplývají žádná pravidla,
která by předem říkala, jaké slovo smí na jakém záviset. Apriori tedy nevylučujeme
ani takové závislosti, které se ve skutečné větě nemohou vyskytnout, nebo
lépe řečeno, jejichž výskyt je velmi nepravděpodobný. Požadujeme však,
aby každé slovo věty bylo právě jedním větným členem, čímž se poněkud odchylujeme
od lingvistických představ o větném členu. V našem pojetí budou rovnoprávnými
vrcholy stromu např. i předložky (nikoli celé předložkové vazby), ba dokonce
i interpunkční znaménka, s nimiž musíme nakládat jako se slovy.
Příklad: Věta ˙Studenti mají zájem o jazyky, fakultě však chybí angličtináři." má následující zápis:
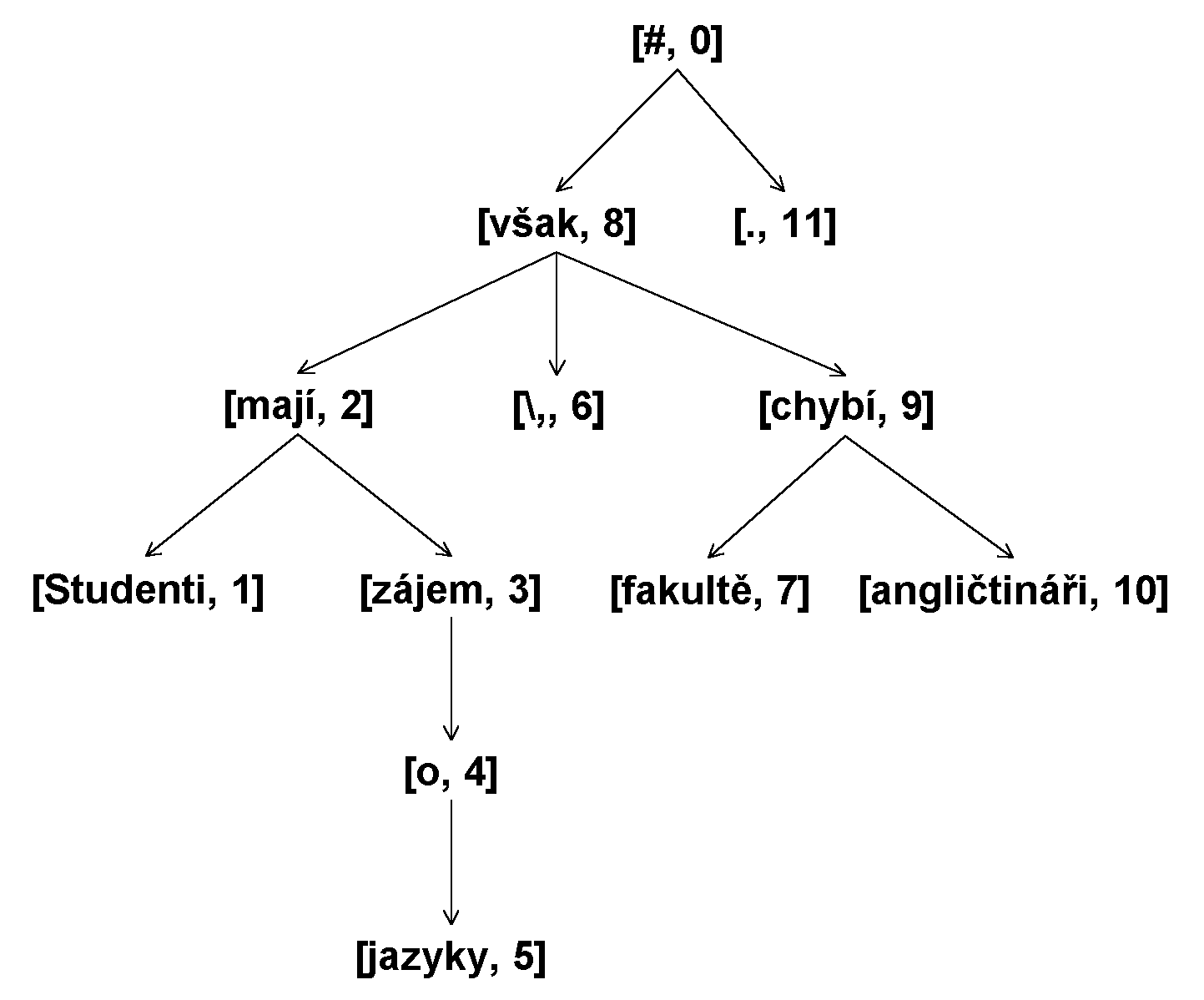
Víme již, že vždy existuje jedno správné řešení, jeden strom M, odpovídající tomu významu věty S, který měl na mysli její autor. Počítač, který je schopen sledovat jen omezené množství souvislostí, dospěje téměř vždy k celé množině stromů, které pro danou větu přicházejí v úvahu. Je jistě přirozené, jestliže si z této množiny vybereme strom, který je pro danou větu nejpravděpodobnější. Podmínkou je, že budeme umět odhadnout pravděpodobnost stromu M v závislosti na větě S, nebo alespoň o každé dvojici stromů říci, který z nich je pravděpodobnější.
Mějme množinu U, jejíž prvky nazveme elementární jevy. Vybereme-li náhodně jeden elementární jev, provádíme pokus a . Výsledkem pokusu je vybraný elementární jev; všechny výsledky považujeme za stejně pravděpodobné. Libovolná podmnožina A množiny U je potom jev, který nastane, jestliže výsledek pokusu a leží v množině A. Pravděpodobnost jevu A se definuje jako poměr počtu prvků množiny A (výsledků příznivých jevu A) k počtu prvků množiny U (všech možných výsledků):
V prvním případě vezmeme za elementární jevy syntaktické zápisy všech
českých vět délky ![]() slov,
které kdy někdo pronesl nebo napsal. Dva různé výskyty téhož stromu jsou
tedy dva různé elementární jevy. Očíslujeme-li všechny výskyty všech stromů,
potom množina U obsahuje právě všechna takto vzniklá čísla. Počet
elementárních jevů je konečný; zanedbáváme ovšem fakt, že jsme do českého
jazyka připustili jen takové věty, které se v něm už někdy v minulosti
vyskytly. Jev A, jehož pravděpodobnost sledujeme, v tomto případě
říká: výsledkem pokusu a je výskyt stromu totožného se stromem M.
slov,
které kdy někdo pronesl nebo napsal. Dva různé výskyty téhož stromu jsou
tedy dva různé elementární jevy. Očíslujeme-li všechny výskyty všech stromů,
potom množina U obsahuje právě všechna takto vzniklá čísla. Počet
elementárních jevů je konečný; zanedbáváme ovšem fakt, že jsme do českého
jazyka připustili jen takové věty, které se v něm už někdy v minulosti
vyskytly. Jev A, jehož pravděpodobnost sledujeme, v tomto případě
říká: výsledkem pokusu a je výskyt stromu totožného se stromem M.
Zcela analogicky pak definujeme jev B jako výskyt hrany h
v některé pronesené nebo napsané české větě. Do množiny ![]() patří všechna čísla, která označují výskyt hrany se stejným řídícím i závislým
vrcholem, jako má hrana h. Existuje
patří všechna čísla, která označují výskyt hrany se stejným řídícím i závislým
vrcholem, jako má hrana h. Existuje ![]() takových podmnožin množiny U, kde L je množina všech slovních
tvarů v češtině; tyto podmnožiny společně vytvářejí disjunktní pokrytí
U. V dalším textu budeme ztotožňovat hranu h s jevem B
a pravděpodobnost výskytu hrany h budeme označovat
takových podmnožin množiny U, kde L je množina všech slovních
tvarů v češtině; tyto podmnožiny společně vytvářejí disjunktní pokrytí
U. V dalším textu budeme ztotožňovat hranu h s jevem B
a pravděpodobnost výskytu hrany h budeme označovat ![]() .
Analogicky budeme postupovat i u stromů a dalších sledovaných prvků: jev,
který hovoří o výskytu jistého stromu, budeme označovat stejným písmenem
jako dotyčný strom.
.
Analogicky budeme postupovat i u stromů a dalších sledovaných prvků: jev,
který hovoří o výskytu jistého stromu, budeme označovat stejným písmenem
jako dotyčný strom.
Tam, kde budeme hovořit o podmíněné pravděpodobnosti, musíme rozšířit
definici elementárního jevu. Chceme-li znát pravděpodobnost ![]() výskytu i-té hrany v závislosti na výskytu
výskytu i-té hrany v závislosti na výskytu ![]() předcházejících hran, musíme za elementární jevy vzít všechny výskyty všech
uspořádaných i-tic hran. Ještě před provedením pokusu a víme, že
prvních
předcházejících hran, musíme za elementární jevy vzít všechny výskyty všech
uspořádaných i-tic hran. Ještě před provedením pokusu a víme, že
prvních ![]() hran v elementárním
jevu, který bude jeho výsledkem, se bude shodovat s hranami
hran v elementárním
jevu, který bude jeho výsledkem, se bude shodovat s hranami ![]() až
až ![]() . Podmiňující jev je
množina všech elementárních jevů, které splňují tuto podmínku. Podmíněný
jev je množina všech elementárních jevů, jejichž poslední hrana se shoduje
s hranou
. Podmiňující jev je
množina všech elementárních jevů, které splňují tuto podmínku. Podmíněný
jev je množina všech elementárních jevů, jejichž poslední hrana se shoduje
s hranou ![]() .
.
Podíváme se na korespondenci mezi stromem M a jeho množinou hran H podrobněji. Můžeme definovat funkci rozlozit, která převede libovolný syntaktický zápis věty na množinu hran, a funkci slozit, která naopak z množiny hran udělá strom. Přitom chceme, aby převod byl v obou směrech jednoznačný, tj. aby každému stromu funkce rozlozit přiřadila právě jednu množinu hran a funkce slozit aby každé množině hran přiřadila právě jeden strom.
Přímo se nám nabízí, abychom definovali první funkci takto: vezmeme strom M, vyjmeme z něj množinu hran, kterou je zadán, a ta bude výsledkem funkce rozlozit. Už z definice plyne, že každý strom má právě jednu takovou množinu. Navíc je uvedené zobrazení prosté, protože žádné dva různé stromy nejsou zadány stejnou množinou hran. Pokud by dva odlišné stromy měly stejnou množinu hran, musely by se lišit buď v množině vrcholů, nebo v kořeni. První případ by znamenal, že v množině V jednoho ze stromů leží vrchol, do kterého nevede žádná hrana. Pak by ale dotyčný graf nebyl strom. Zbývá tedy jediná možnost, že se stromy liší v tom, který vrchol je kořen. Jak ale vyplývá z naší definice, syntaktický zápis věty má kořen ve zvláštním vrcholu #, který je v každém stromu právě jeden. Uvedený případ proto nemůže nastat.
Protože funkce rozlozit je prostá, můžeme pro všechny množiny H z jejího oboru hodnot definovat funkci slozit jako rozlozit -1. Zbude nám však mnoho množin hran, které leží mimo obor hodnot funkce rozlozit, protože nepopisují strom: například množiny, v nichž se vyskytuje hrana se stejným řídícím i závislým vrcholem. Pro tyto množiny musíme funkci slozit dodefinovat. Jestliže H je množina hran, které nemohou náležet stromu, potom za výsledek slozit(H) označíme zvláštní strom M#, který nereprezentuje žádnou skutečnou větu. Na M# můžeme pohlížet jako na prázdný strom, obsahující pouze kořen. Právě tak ovšem můžeme definovat speciální strom s libovolným počtem vrcholů, jestliže žádný ze symbolů, kterými vrcholy označíme, nebude odpovídat žádnému slovnímu tvaru. Máme tedy zvláštní strom M#,n pro každou třídu stromů, které mají n vrcholů; bude se nám to hodit později, až zúžíme obor na stromy s pevným počtem vrcholů.
Abychom si usnadnili implementaci, budeme dále požadovat, aby hrany v množině H byly uspořádány. H tedy nebude pouhá množina, ale posloupnost hran. Uspořádání by mělo vyplývat ze struktury stromu, např. může jít o pořadí hran při prohledávání do hloubky. Volbu uspořádání provedeme později. Za nepřípustné posloupnosti, vedoucí na strom M#, budeme pak považovat i ty množiny, jejichž hrany sice dávají strom, ale nejsou správně uspořádány.
Jestliže umíme převést strom na posloupnost hran a zpátky, nahradíme
pravděpodobnost stromu M pravděpodobností jemu odpovídající posloupnosti
H. Dopouštíme se tak značného zkreslení skutečnosti, protože největší
pravděpodobnost dostane zvláštní strom M#, reprezentující
všechny špatné posloupnosti. Ale poměry pravděpodobností ostatních stromů
zůstanou zachovány, proto můžeme hledat takovou posloupnost H, že ![]() a součin
a součin ![]() je nejvyšší možný:
je nejvyšší možný:
Teď už snadno určíme pravděpodobnost ![]() .
Pomocí funkcí slozit a syntéza získáme větu SH,
ze které posloupnost H vznikla. Tu pak porovnáme s větou S
a položíme
.
Pomocí funkcí slozit a syntéza získáme větu SH,
ze které posloupnost H vznikla. Tu pak porovnáme s větou S
a položíme ![]() , jestliže
, jestliže ![]() ,
a
,
a ![]() jinak. Tím jsme zaručili,
že výsledná posloupnost hran, kterou dostaneme při větné analýze, je správně
uspořádanou posloupností, že definuje strom, že tento strom je korektním
syntaktickým zápisem věty a že tato věta je S. (Poslední podmínka
znamená, že pro každé slovo věty lze nalézt vrchol stromu, u něhož je správně
uveden tvar tohoto slova a jeho pořadí ve větě.) Při takto definované pravděpodobnosti
jinak. Tím jsme zaručili,
že výsledná posloupnost hran, kterou dostaneme při větné analýze, je správně
uspořádanou posloupností, že definuje strom, že tento strom je korektním
syntaktickým zápisem věty a že tato věta je S. (Poslední podmínka
znamená, že pro každé slovo věty lze nalézt vrchol stromu, u něhož je správně
uveden tvar tohoto slova a jeho pořadí ve větě.) Při takto definované pravděpodobnosti ![]() můžeme už bez doplňujících podmínek napsat:
můžeme už bez doplňujících podmínek napsat:
Obecně lze vytvořit nekonečně mnoho různých grafů, které odpovídají
definici stromu. Jinak je tomu, jestliže předem víme, kolik má mít strom
vrcholů. Pomocí četnosti v trénovacích datech můžeme odhadnout pravděpodobnost ![]() ,
že náhodně vybraný strom má m vrcholů. Potom budeme hledat pravděpodobnost
,
že náhodně vybraný strom má m vrcholů. Potom budeme hledat pravděpodobnost ![]() ,
přičemž možných stromů s m vrcholy je už jen konečně mnoho. Ve skutečnosti
se v následujícím textu rovnou omezíme na stromy s m vrcholy, protože
při praktickém použití budeme vždy dopředu vědět, kolik vrcholů má hledaný
strom mít. Stromům s jiným počtem vrcholů můžeme bez obav přisoudit nulovou
pravděpodobnost, protože nejsou syntaktickým zápisem věty, kterou rozebíráme
(a platí pro ně
,
přičemž možných stromů s m vrcholy je už jen konečně mnoho. Ve skutečnosti
se v následujícím textu rovnou omezíme na stromy s m vrcholy, protože
při praktickém použití budeme vždy dopředu vědět, kolik vrcholů má hledaný
strom mít. Stromům s jiným počtem vrcholů můžeme bez obav přisoudit nulovou
pravděpodobnost, protože nejsou syntaktickým zápisem věty, kterou rozebíráme
(a platí pro ně ![]() ). Rezervujme
nyní písmeno n pro počet slov ve větě, kterou rozebíráme; strom
M bude mít
). Rezervujme
nyní písmeno n pro počet slov ve větě, kterou rozebíráme; strom
M bude mít ![]() vrcholů
(pro každé slovo jeden vrchol a přídavný vrchol pro kořen).
vrcholů
(pro každé slovo jeden vrchol a přídavný vrchol pro kořen).
Vrátíme se teď k naší otázce: kolik je stromů s ![]() vrcholy? Obecně nad množinou m vrcholů existuje
vrcholy? Obecně nad množinou m vrcholů existuje ![]() různých stromů. Tento výsledek z teorie grafů ovšem předpokládá, že stromy
jsou dány pouze množinou vrcholů a množinou hran; přitom se nebere ohled
na to, který vrchol považujeme za kořen stromu. V našem případě je kořen
dán předem jako přídavný vrchol, z jehož tvaru už je patrné, že jde o kořen.
Proto můžeme u uvedeného vztahu zůstat: máme
různých stromů. Tento výsledek z teorie grafů ovšem předpokládá, že stromy
jsou dány pouze množinou vrcholů a množinou hran; přitom se nebere ohled
na to, který vrchol považujeme za kořen stromu. V našem případě je kořen
dán předem jako přídavný vrchol, z jehož tvaru už je patrné, že jde o kořen.
Proto můžeme u uvedeného vztahu zůstat: máme ![]() vrcholů a
vrcholů a ![]() stromů. Např.
pro větu o 6 slovech, kterou předem známe, je to 16 807 stromů za předpokladu,
že ke každému slovu věty bude existovat právě jeden možný vrchol; pro libovolnou
větu se stejným počtem slov bychom uvedené číslo museli navíc vynásobit
počtem různých šestic slov, které český jazyk připouští. K tomuto ilustračnímu
příkladu se ještě vrátíme; prozatím je pro nás důležité zjištění, že počet
vrcholů (a tedy i hran) stromu M je předem dán.
stromů. Např.
pro větu o 6 slovech, kterou předem známe, je to 16 807 stromů za předpokladu,
že ke každému slovu věty bude existovat právě jeden možný vrchol; pro libovolnou
větu se stejným počtem slov bychom uvedené číslo museli navíc vynásobit
počtem různých šestic slov, které český jazyk připouští. K tomuto ilustračnímu
příkladu se ještě vrátíme; prozatím je pro nás důležité zjištění, že počet
vrcholů (a tedy i hran) stromu M je předem dán.
Řekli jsme, že strom M budeme reprezentovat posloupností hran H; chceme znát pravděpodobnost této posloupnosti. Jinými slovy, chceme vědět, s jakou pravděpodobností se v H současně objeví hrany h1 až hn v daném pořadí:
Faktorem, způsobujícím nespolehlivost modelu, je počet jeho parametrů, tedy potenciální počet různých hodnot, jejichž četnost chceme evidovat. Pro ilustraci: Za předpokladu, že každému slovnímu tvaru odpovídá právě jeden možný vrchol syntaktického stromu, že čeština má 6 000 000 slovních tvarů a, podobně jako v posledním příkladu, že délka české věty nepřesahuje 6 slov, potom výše uvedený model bude mít asi 7,8.1044 parametrů!
Budeme tedy předpokládat, že výskyt hrany h není závislý na výskytu ostatních hran ve stromu:
Ověřme, zda hodnota ![]() splňuje podmínky pro pravděpodobnost, tj.:
splňuje podmínky pro pravděpodobnost, tj.:
První podmínka je zřejmě splněna, neboť součin čísel z intervalu ![]() vždy zůstane v tomto intervalu.
vždy zůstane v tomto intervalu.
Platnost druhé podmínky dokážeme níže. Zopakujme, že zde hovoříme o součtu pravděpodobností všech různých n-tic hran, nikoli všech stromů. Na součtu se mohou podílet i nenulové pravděpodobnosti takových n-tic, které strom nedávají; potom součet pravděpodobností těch n-tic, které jsou stromem, nutně bude menší než 1. Vzhledem k našemu cíli to však nevadí, jak jsme zjistili v předchozích částech této kapitoly.
Věta 1: Nechť ![]() je pravděpodobnost výskytu hrany h. Označme L2
množinu všech hran. Potom pro libovolné přirozené číslo n platí:
je pravděpodobnost výskytu hrany h. Označme L2
množinu všech hran. Potom pro libovolné přirozené číslo n platí:
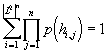
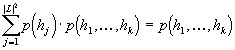 ,
,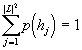 .
.K uvedenému důkazu nepotřebujeme vědět, jestli je pravděpodobnost rozšiřující
hrany ![]() závislá na předchozích
hranách. Stačí nám skutečnost, že součet pravděpodobností všech možných
rozšiřujících hran dává 1. Bude-li pravděpodobnost hrany
závislá na předchozích
hranách. Stačí nám skutečnost, že součet pravděpodobností všech možných
rozšiřujících hran dává 1. Bude-li pravděpodobnost hrany ![]() podmíněna tím, jaké hrany se v posloupnosti objevily před ní, dojde pouze
k přerozdělení pravděpodobností mezi kandidáty na
podmíněna tím, jaké hrany se v posloupnosti objevily před ní, dojde pouze
k přerozdělení pravděpodobností mezi kandidáty na ![]() -ní
pozici, ale jejich součet zůstane roven 1. Jestliže se tedy rozhodneme
pracovat s nepodmíněnou pravděpodobností, nebudou tím narušeny nutné technické
podmínky, které na pravděpodobnost klademe. I tak se ovšem námi stanovené
hodnoty mohou od skutečných pravděpodobností značně lišit, takže otázku
podmíněnosti ani nadále nepustíme ze zřetele.
-ní
pozici, ale jejich součet zůstane roven 1. Jestliže se tedy rozhodneme
pracovat s nepodmíněnou pravděpodobností, nebudou tím narušeny nutné technické
podmínky, které na pravděpodobnost klademe. I tak se ovšem námi stanovené
hodnoty mohou od skutečných pravděpodobností značně lišit, takže otázku
podmíněnosti ani nadále nepustíme ze zřetele.
Vraťme se však k naší úloze, tedy k hledání pravděpodobnosti syntaktických závislostí ve větě. Tento problém vykazuje vyšší kombinatorickou složitost než zmíněné morfologické modelování, proto se rovnou omezíme na kontext velikosti 1. Nemáme také žádné vodítko pro volbu kontextu, protože dosud získané zkušenosti se týkají modelování prostého textu, ne jeho syntaktických struktur. Můžeme ale s výhodou využít faktu, že máme hrany našeho syntaktického stromu uspořádány do posloupnosti. U každé hrany s výjimkou první můžeme uvažovat kontext té hrany, která jí v posloupnosti bezprostředně předcházela. Všimněme si, že jsme tím jeden ze stěžejních parametrů modelu ponechali na funkci rozlozit, která určuje uspořádání hran ve stromu. Konkrétní, prozatím odložená definice této funkce tak může významně ovlivnit výsledky větného rozboru.
Jestliže pravděpodobnost jedné hrany závisí na předchozí hraně, pak pravděpodobnost celé posloupnosti nově zapíšeme takto:
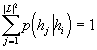 .
.
Na začátku kapitoly Kapitola 3 jsme definovali pravděpodobnost jevu A pomocí elementárních jevů a pokusu a , při kterém náhodně jeden elementární jev vybereme. Definujme relativní četnost jevu A jako poměr počtu pokusů, po nichž nastal jev A, k celkovému počtu provedených pokusů:
Analogicky odhadneme i podmíněnou pravděpodobnost ![]() jako poměr počtu pokusů, po nichž nastal současně jev A i jev B,
k počtu pokusů, po nichž nastal jev B:
jako poměr počtu pokusů, po nichž nastal současně jev A i jev B,
k počtu pokusů, po nichž nastal jev B:
V první fázi, kterou nazveme trénovací, tedy budeme číst náhodně zvolený rozebraný text, tj. posloupnost stromů. To budou naše trénovací data. Čím větší množství dat získáme, tím lépe, protože tím spolehlivější bude náš model. Každou větu projdeme podle definovaného uspořádání hran ve stromu. Přitom budeme udržovat tabulku četností dvojic po sobě jdoucích hran, tabulku četností samostatných hran a celkový počet přečtených hran. Na základě těchto údajů dokážeme odhadnout pravděpodobnost libovolné hrany h, když víme, jaká hrana jí předcházela.
Všimněme si, že stále nepotřebujeme vědět, jak vypadá vrchol stromu a podle čeho určíme, že dva vrcholy, resp. dvě hrany, jsou stejné. V tomto smyslu jsou popisované metody univerzální: můžeme trénovat model nejen podle slovních tvarů, ale také například podle slovních druhů, mluvnických kategorií apod. Jediné omezení tkví v tom, že dotyčnou informaci, kterou prohlásíme za klíčovou pro odlišení dvou vrcholů, musíme mít k dispozici nejen při trénování, ale i později při analýze. Podrobněji se touto otázkou budeme zabývat v kapitole Kapitola 5 .
Potíž je v tom, že jen některé hrany vylučujeme právem, protože jsou v daném jazyce skutečně chybné. Mnoho dalších hran dostane nulu prostě proto, že se v našich trénovacích datech v daném kontextu nevyskytly, ačkoli obecně jejich výskyt vyloučen není. Při použití jazykového modelu se může stát, že dostaneme vedlejší informaci, která bude dotyčnou hranu absolutně preferovat; s nulovou pravděpodobností se však taková informace nemůže uplatnit. Z toho důvodu se nulám v rozdělení chceme vyhnout a neviděným hranám přiřadit jistou velmi nízkou, avšak nenulovou hodnotu.
Jednou možností, jak toho dosáhnout, je přičíst ke všem absolutním četnostem
v trénovacích datech relativně nízkou konstantu, např. 1. Bude-li tréninkový
text obsahovat 10 000 hran, dostanou neznámé hrany pravděpodobnost ![]() .
Tento přístup neklade žádné další nároky na zpracování dat, ale nijak nerozlišuje
hrany, které se neobjevily, od těch, které se nikdy objevit nemohou.
.
Tento přístup neklade žádné další nároky na zpracování dat, ale nijak nerozlišuje
hrany, které se neobjevily, od těch, které se nikdy objevit nemohou.
Přesnější je jiná metoda, která kombinuje vícegramové rozdělení s méněgramovými. V našem konkrétním případě sledujeme výskyt hrany v kontextu jedné předcházející hrany. Chceme-li ve známém kontextu zjistit pravděpodobnost hrany, která se v trénovacích datech v tomto kontextu neobjevila, můžeme se pokusit zjistit její nepodmíněnou pravděpodobnost (bez ohledu na kontext). Mezery ve dvougramovém modelu tedy doplníme jednogramovým. Pokud ani to nepomůže a pravděpodobnost bude stále nulová, můžeme na zbylé hrany použít rovnoměrné rozdělení (odpovídá 0-gramovému modelu).
Protože součet takto získaných pravděpodobností přes všechny hrany není
roven 1, musíme jednotlivým i-gramovým rozdělením přiřadit váhy ![]() ,
kde
,
kde ![]() . Pravděpodobnost hrany
hi pak určíme takto:
. Pravděpodobnost hrany
hi pak určíme takto:
Tomuto způsobu odstranění nulových pravděpodobností říkáme vyhlazování jazykového modelu.
Zbývá zodpovědět otázku, kde vzít hodnoty jednotlivých vah ![]() .
Dobrých výsledků lze dosáhnout i odhadem, přičemž bývá vhodné dodržet podmínku
.
Dobrých výsledků lze dosáhnout i odhadem, přičemž bývá vhodné dodržet podmínku ![]() .
Například můžeme zvolit
.
Například můžeme zvolit ![]() ,
, ![]() a
a ![]() . Pokud máme k dispozici
dostatek vzorových dat, můžeme iteračním algoritmem tyto hodnoty ještě
více přiblížit realitě.
. Pokud máme k dispozici
dostatek vzorových dat, můžeme iteračním algoritmem tyto hodnoty ještě
více přiblížit realitě.
Popíšeme zde jeden průchod algoritmu, kterým z hodnot ![]() ,
získaných předchozím průchodem algoritmu nebo odhadem, dostaneme nové,
realističtější hodnoty
,
získaných předchozím průchodem algoritmu nebo odhadem, dostaneme nové,
realističtější hodnoty ![]() .
Iterací tohoto kroku váhy konvergují k hodnotám
.
Iterací tohoto kroku váhy konvergují k hodnotám ![]() ,
které považujeme za optimální.
,
které považujeme za optimální.
Algoritmus zjišťuje, nakolik se jednotlivá i-gramová rozdělení
uplatnila při aplikaci na skutečná data. Míra uplatnění je dána jednak
výchozími hodnotami vah, jednak dílčími pravděpodobnostmi, kterými se to
které rozdělení podílelo na celkových pravděpodobnostech hran v textu.
Pokud tedy naprostá většina dvojic hran dostává od bigramového rozdělení
nulu, takže ˙zachraňovat situaci" musí unigramové rozdělení svými četnostmi
samostatných hran, bude toto rozdělení zvýhodněno vyšší hodnotou ![]() .
.
V jednom kroku algoritmu projdeme celá data, která máme pro vyhlazování
vyčleněna, přičemž sčítáme následující veličiny (![]() je počet výskytů všech hran v datech vyčleněných pro vyhlazování):
je počet výskytů všech hran v datech vyčleněných pro vyhlazování):
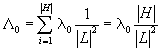 .
.Na konci kroku zjistíme pro jednotlivá rozdělení jejich ˙podíl na moci", vyjádřený novými hodnotami vah:
Intuitivně je zřejmé, že nové váhy budou dávat lepší výsledky v ˙realitě". Tu zde reprezentují použitá data H, proto je důležité, aby se stylisticky podobala textu, který jsme použili pro trénování. Samotná trénovací data ovšem použít nemůžeme, potom by poměry jednotlivých vah vyšly 1:0:0. Osvědčuje se proto rozdělit vzorový text na dvě části. První použijeme pro trénování a druhou, menší, vyčleníme na vyhlazování - odtud pojem vyčleněná data.
Pokud nemáme k dispozici dostatek trénovacích dat, zůstaneme u odhadnutých hodnot pro jednotlivé váhy.
V kapitole Kapitola 3 jsme zjistili, že hledáme výsledek výrazu
Z uvedeného vyplývá, že hledaná posloupnost hran musí mít maximální ![]() při současném zachování ˙správnosti", aby
při současném zachování ˙správnosti", aby ![]() .
.
Problém maximalizace ![]() je analogií hledání maximální kostry grafu. Máme graf
je analogií hledání maximální kostry grafu. Máme graf ![]() ,
kde V je množina vrcholů a HG je množina hran,
a máme definovánu funkci
,
kde V je množina vrcholů a HG je množina hran,
a máme definovánu funkci ![]() ,
která každé hraně přiřadí ˙ohodnocení". Chceme nalézt takový strom
,
která každé hraně přiřadí ˙ohodnocení". Chceme nalézt takový strom ![]() ,
aby
,
aby ![]() byla maximální. V
našem případě je G úplný graf, V je množina slov výchozí
věty (plus kořen #) a HG obsahuje všechny uspořádané
dvojice vrcholů z V. Hodnotící funkci představuje pravděpodobnost
byla maximální. V
našem případě je G úplný graf, V je množina slov výchozí
věty (plus kořen #) a HG obsahuje všechny uspořádané
dvojice vrcholů z V. Hodnotící funkci představuje pravděpodobnost ![]() .
Úloha o kostře požaduje maximalizaci součtu, zatímco my potřebujeme co
možná nejvyšší součin. Postup, který ukážeme, lze však použít v obou případech,
protože pravděpodobnosti jsou nezáporná čísla. (Kdyby
.
Úloha o kostře požaduje maximalizaci součtu, zatímco my potřebujeme co
možná nejvyšší součin. Postup, který ukážeme, lze však použít v obou případech,
protože pravděpodobnosti jsou nezáporná čísla. (Kdyby ![]() mohlo být záporné, závisel by výsledek součinu mj. na tom, jestli se záporných
činitelů vyskytl lichý nebo sudý počet. U součtu nic podobného nehrozí.)
mohlo být záporné, závisel by výsledek součinu mj. na tom, jestli se záporných
činitelů vyskytl lichý nebo sudý počet. U součtu nic podobného nehrozí.)
Pro hledání maximální kostry M použijeme hladový algoritmus.
Začneme se stromem, obsahujícím jeden libovolný vrchol grafu G (například
kořen #), a potom v každém kroku přidáme takovou hranu ![]() ,
že
,
že ![]() ,
, ![]() a
a ![]() je nejvyšší možná. Skončíme
v okamžiku, kdy nemůžeme přidat žádnou další hranu, protože strom M
už obsahuje všechny vrcholy grafu G.
je nejvyšší možná. Skončíme
v okamžiku, kdy nemůžeme přidat žádnou další hranu, protože strom M
už obsahuje všechny vrcholy grafu G.
Dá se ukázat, že pro neorientované grafy je výsledek hladového algoritmu
skutečně maximální; že je to kostra, plyne přímo ze způsobu konstrukce.
Potíž je v tom, že my pracujeme s orientovanými grafy, kde nemusí platit ![]() .
Následující obrázek je příkladem orientovaného grafu, na kterém námi popsaný
algoritmus selže. (Graf je úplný; hrany, které nejsou zakresleny, mají
pravděpodobnost libovolně blízkou nule.)
.
Následující obrázek je příkladem orientovaného grafu, na kterém námi popsaný
algoritmus selže. (Graf je úplný; hrany, které nejsou zakresleny, mají
pravděpodobnost libovolně blízkou nule.)
Příklad 1:
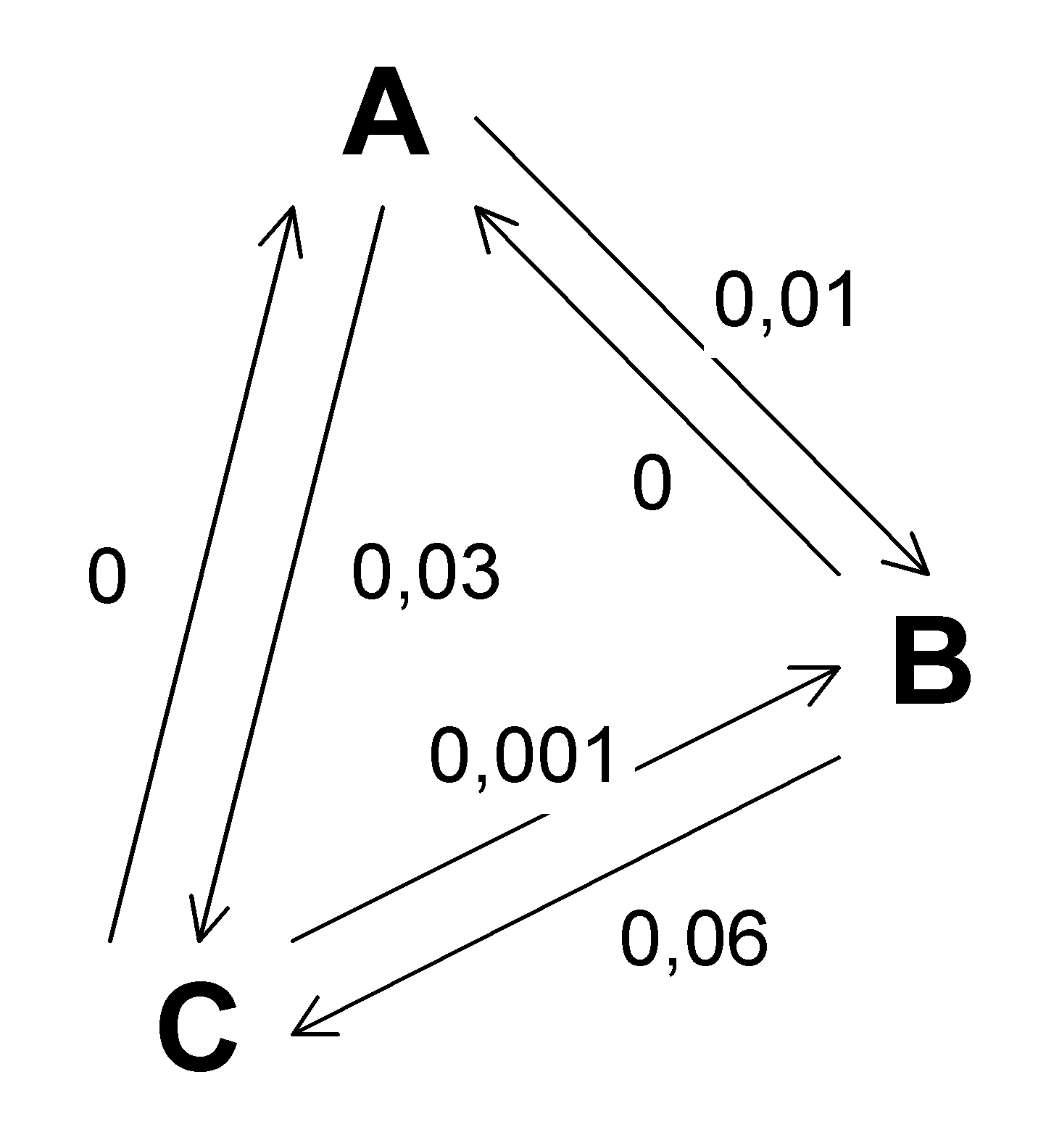
Jestliže A je kořen, potom algoritmus přidá nejdříve hranu [AC], potom hranu [AB]. Pravděpodobnost posloupnosti hran vyjde 0,0003. Vezmeme-li však hrany [AB] a [BC], dostaneme pravděpodobnost vyšší: 0,0006.
Domníváme se, že podobné případy nebudou výjimečné (jak často k nim dochází a jak moc se chyba projeví na výsledných stromech, to ukáží až praktické pokusy). Uvedeme proto ještě jednu variantu hladového algoritmu; podle zvoleného přístupu jí budeme říkat komponentová, zatímco dříve uvedenou verzi nazveme sekvenční.
Komponentový hladový algoritmus pracuje na principu slévání komponent
grafu. Na začátku máme ![]() komponent, z nichž každá obsahuje právě jeden vrchol grafu G. V
každém kroku pak přidáme hranu, která spojuje dvě existující komponenty
v jedinou. Požadujeme tedy, aby řídící vrchol ležel v jiné komponentě než
závislý a dále (pro orientované grafy) aby cílová komponenta byla napojena
ve svém kořeni, tj. v takovém vrcholu, do kterého dosud nevede žádná jiná
hrana. Ze všech hran, které splňují uvedené podmínky, vybereme nejpravděpodobnější.
Po n krocích dostaneme jedinou komponentu obsahující všechny vrcholy
grafu G, a tu prohlásíme za výslednou maximální kostru.
komponent, z nichž každá obsahuje právě jeden vrchol grafu G. V
každém kroku pak přidáme hranu, která spojuje dvě existující komponenty
v jedinou. Požadujeme tedy, aby řídící vrchol ležel v jiné komponentě než
závislý a dále (pro orientované grafy) aby cílová komponenta byla napojena
ve svém kořeni, tj. v takovém vrcholu, do kterého dosud nevede žádná jiná
hrana. Ze všech hran, které splňují uvedené podmínky, vybereme nejpravděpodobnější.
Po n krocích dostaneme jedinou komponentu obsahující všechny vrcholy
grafu G, a tu prohlásíme za výslednou maximální kostru.
Pro neorientované grafy jsou obě uvedené varianty hladového algoritmu ekvivalentní a dávají stejné výsledky. U orientovaného grafu, uvedeného v příkladu 1, komponentová varianta narozdíl od sekvenční neselže: jako první vybere hranu [BC], potom hranu [AB]. Ale obecně ani tato verze nezaručuje dosažení maxima; protipříkladem může být následující graf. (Opět předpokládáme, že nezakreslené hrany mají zanedbatelnou pravděpodobnost.)
Příklad 2:
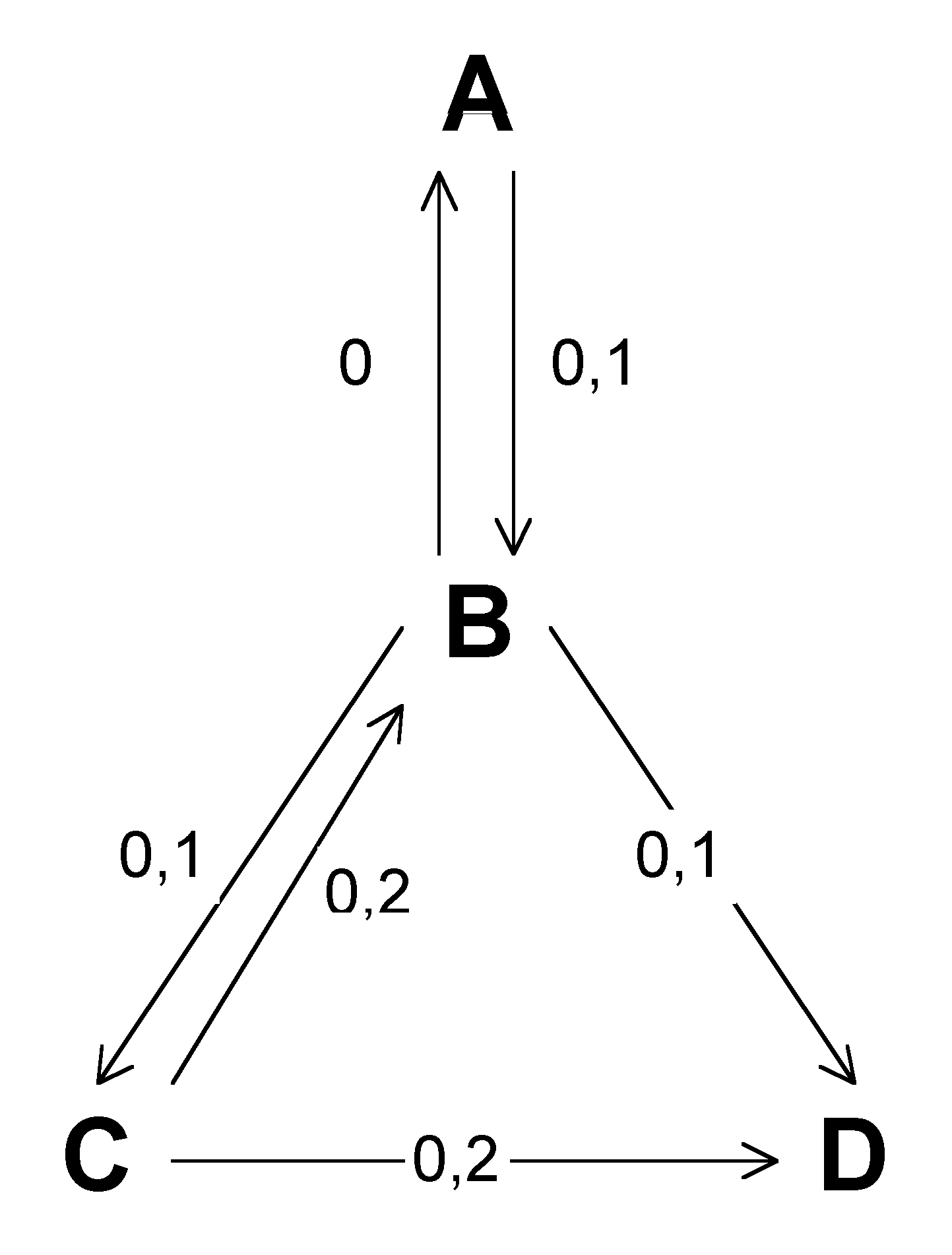
V tomto případě komponentový algoritmus použije po řadě hrany [CB], [CD] a [BA]; správné řešení je [AB], [BC] a [CD].
Ani jedna z obou verzí hladového algoritmu tedy pro orientované grafy
nezaručuje optimální výsledek. Přesto hladový algoritmus použijeme, protože
neznáme žádný lepší způsob, jak maximum nalézt. Jistotu získáme pouze v
případě, že probereme všechny stromy, které lze sestavit nad danou množinou
vrcholů; takový postup by však měl exponenciální složitost. Hladový algoritmus
naproti tomu bude mít v nejhorším případě složitost ![]() .
Nemáme dost pádný argument, abychom rozhodli mezi sekvenční nebo komponentovou
variantou, proto vyzkoušíme obě. Posledně jmenovaná má ale podstatnou nevýhodu:
v okamžiku přidávání hrany většinou neznáme hranu, která jí předchází v
uspořádání definovaném funkcí rozlozit. Neznáme tedy kontext a nemůžeme
použít podmíněné pravděpodobnosti. Proto budeme komponentovou variantu
testovat pouze s jednogramovým modelem.
.
Nemáme dost pádný argument, abychom rozhodli mezi sekvenční nebo komponentovou
variantou, proto vyzkoušíme obě. Posledně jmenovaná má ale podstatnou nevýhodu:
v okamžiku přidávání hrany většinou neznáme hranu, která jí předchází v
uspořádání definovaném funkcí rozlozit. Neznáme tedy kontext a nemůžeme
použít podmíněné pravděpodobnosti. Proto budeme komponentovou variantu
testovat pouze s jednogramovým modelem.
Nakonec musíme zaručit, aby ![]() .
Tj. že 1) H popisuje strom, 2) H je správně uspořádaná podle
uspořádání daného funkcí rozlozit a 3) H odpovídá větě S.
Poslední podmínka je triviálně splněna, protože při konstrukci používáme
pouze slova z věty S. Obě verze hladového algoritmu také garantují,
že jejich výsledek je strom. K porušení druhé podmínky může dojít ve vícegramovém
modelu, kde použité pravděpodobnosti závisí nejen na aktuální hraně, ale
i na její předchůdkyni. (V jednogramovém modelu můžeme s utříděním posloupnosti
vyčkat do okamžiku, kdy budeme znát všechny její členy.) Proto v běžném
kroku sekvenčního algoritmu omezíme výběr na hrany, které jsou ve smyslu
daného uspořádání ˙větší" než naposledy přidaná hrana.
.
Tj. že 1) H popisuje strom, 2) H je správně uspořádaná podle
uspořádání daného funkcí rozlozit a 3) H odpovídá větě S.
Poslední podmínka je triviálně splněna, protože při konstrukci používáme
pouze slova z věty S. Obě verze hladového algoritmu také garantují,
že jejich výsledek je strom. K porušení druhé podmínky může dojít ve vícegramovém
modelu, kde použité pravděpodobnosti závisí nejen na aktuální hraně, ale
i na její předchůdkyni. (V jednogramovém modelu můžeme s utříděním posloupnosti
vyčkat do okamžiku, kdy budeme znát všechny její členy.) Proto v běžném
kroku sekvenčního algoritmu omezíme výběr na hrany, které jsou ve smyslu
daného uspořádání ˙větší" než naposledy přidaná hrana.
K testování potřebujeme další text, který už obsahuje syntaktickou strukturu a který stylisticky se podobá textu použitému pro trénování. Výchozí data tedy budeme případně dělit až na tři části: trénovací (T, ta bude nejrozsáhlejší), vyhlazovací (vyčleněnou, H) a testovací (Z). Z testovacích dat odstraníme syntaktické struktury a necháme je rozebrat naším programem. Potom vezmeme dvojici stromů M1, M2, kde první byl součástí testovacích dat a druhý z něj vzniknul odstraněním a opětovným vygenerováním syntaktické struktury. Pro každou takovou dvojici spočítáme hrany, které se vyskytly v obou stromech současně. Celkový počet shodných hran ve všech dvojicích stromů ze Z vydělíme celkovým počtem všech hran v Z a získáme úspěšnost; její doplněk do jedničky pak bude chyba.
Jelikož nám pravděpodobnost dává ohodnocení každého stromu, můžeme také
definovat vzdálenost, nebo lépe rozdíl dvou stromů. Je-li ![]() ohodnocení stromu M, potom rozdíl
ohodnocení stromu M, potom rozdíl
Abychom mohli porovnávat ohodnocení různě velkých stromů, nemůžeme za ![]() dosadit přímo součin pravděpodobností hran stromu M, musíme ho normalizovat
vzhledem k počtu hran n. Získáme tak vlastně geometrický průměr
pravděpodobností hran:
dosadit přímo součin pravděpodobností hran stromu M, musíme ho normalizovat
vzhledem k počtu hran n. Získáme tak vlastně geometrický průměr
pravděpodobností hran:
Pravděpodobnostní rozdělení můžeme charakterizovat veličinou zvanou
entropie, kterou chápeme jako míru neurčitosti. Čím vyšší entropii
má jazykový model, tím obtížněji se na jeho základě předpovídá budoucí
text. Nejvyšší možná entropie má hodnotu ![]() a odpovídá rovnoměrnému rozdělení. Naopak nulovou entropii mají rozdělení,
kde jeden jev je jistý a všechny ostatní nemožné. Entropie H pokusu
a je definována následujícím vztahem:
a odpovídá rovnoměrnému rozdělení. Naopak nulovou entropii mají rozdělení,
kde jeden jev je jistý a všechny ostatní nemožné. Entropie H pokusu
a je definována následujícím vztahem:
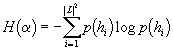
Nezáleží na tom, při jakém základu počítáme logaritmus; my budeme vždy používat logaritmus při základu 2, takže výsledek vyjde v bitech. To souvisí s jinou interpretací entropie, která říká, kolik bitů potřebujeme na zakódování libovolné hrany z T.
Jestliže pracujeme s podmíněnými pravděpodobnostmi, hodnota entropie
by se měla snížit, protože znalost kontextu zvyšuje naši rozhodovací schopnost.
Hovoříme pak o podmíněné entropii ![]() .
.
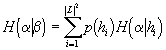 , tj.
, tj.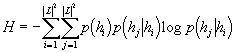
Pro porovnávání natrénovaného rozdělení s testovacími daty slouží tzv.
křížová entropie. Vztah pro ni se podobá definici entropie, ale
do prvního činitele místo pravděpodobnosti dvojice hran dosazujeme relativní
četnost této dvojice v testovacích datech - ![]() :
:
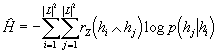
Konečně poslední veličinou, kterou budeme sledovat, je perplexita, definovaná vztahem
kde H je entropie. Perplexita nám říká, kolik různých hran bychom
potřebovali, aby při rovnoměrném rozdělení pravděpodobností vyšla stejná
entropie. To znamená, že při rovnoměrném rozdělení bychom měli jen ![]() různých hran. Perplexita nemůže vyjít větší než počet různých hran v trénovacích
datech.
různých hran. Perplexita nemůže vyjít větší než počet různých hran v trénovacích
datech.
Popsané metody nám na několika místech ponechávají volnost ve volbě konkrétních postupů či hodnot. Při výběru variant, které prezentujeme v následujících odstavcích, jsme byli od začátku vedeni a omezováni množstvím i tvarem dat, která máme k dispozici pro trénování.
Data pocházejí z Ústavu českého národního korpusu Filozofické fakulty UK. Korpus obsahuje v současné době texty nejrůznějšího původu a stylu v rozsahu 50 až 70 miliónů slov, přičemž část textů již byla syntakticky analyzována v rámci projektu Formální reprezentace jazykových struktur. Spolu s daty jsme z tohoto projektu převzali i jejich jednotný formát, mj. atributy vrcholu a stavbu morfologické značky. Část, která je v současné době rozebrána, představuje pouhý zlomek všech korpusových dat. K dispozici máme 1150 vět, přičemž v jiných aplikacích pravděpodobnostního modelování jazyka vedou k uspokojivým výsledkům řádově desetitisíce. Musíme se proto snažit volit takové metody, které jsou na množství dat méně náročné.
Na prvním místě jde o volbu velikosti kontextu, tj. gramu. Hodláme vyzkoušet
1- i 2-gramový model, budeme tedy uvažovat kontext nejvýše jedné předcházející
hrany. Nemůžeme také opomenout vyhlazování: Zkombinujeme dvougramové rozdělení
s jednogramovým a rovnoměrným, přičemž váhy jednotlivých rozdělení stanovíme
odhadem. Položíme ![]() ,
, ![]() a
a ![]() pro bigram, resp.
pro bigram, resp. ![]() a
a ![]() při testování unigramu.
při testování unigramu.
Dále musíme určit způsob, jakým budou uspořádány hrany v syntaktickém stromu, tj. definovat funkce rozlozit a slozit. Toto uspořádání významně ovlivní volbu kontextu ve dvourozměrném rozdělení, a tím i přesnost získaného modelu. Nedovedeme však předem říci, které uspořádání bude dávat lepší či horší výsledky, proto vyzkoušíme dva způsoby, které se nám jeví nejpřirozenější: hrany budou uspořádány podle svých závislých vrcholů v pořadí daném procházením stromu do hloubky, resp. do šířky. Vrcholy na téže úrovni od kořene uspořádáme podle jejich pořadí (resp. pořadí jimi reprezentovaných slov) ve větě.
Konečně nejdůležitější rozhodnutí tkví v tom, jak přesně bude vypadat vrchol stromu a podle kterých rysů budeme při trénování a při analýze určovat, že dva vrcholy, resp. dvě hrany, jsou ekvivalentní.
Vrchol lze popsat jako strukturu rysů (feature structure), která obsahuje až 12 atributů. Čtyři z nich pro nás mohou být zajímavé:
Z uvedených položek nejdříve vyloučíme pořadí, neboť intuitivně tušíme, že nemá valný vliv na skladbu věty. Spíše než absolutní umístění by nás mohla zajímat vzdálenost dvou slov od sebe, ale ve stávajícím modelu ji neumíme využít.
Zbývající atributy porovnáme podle potenciálního počtu parametrů, které přinesou. Různých tvarů je v češtině asi 6 000 000, hesel zhruba 40 000 a značek jen necelých 1800. Protože nepracujeme s vrcholy, ale s hranami, resp. s dvojicemi hran, musíme k získání počtu parametrů to které číslo ještě umocnit na druhou, resp. na čtvrtou. Odtud je zřejmé, že při našem malém množství dat musíme model trénovat podle značek.
Upozorněme zároveň, že toto rozhodnutí má i výrazné nevýhody. Kromě nižší přesnosti je to zejména fakt, že jeden vrchol může obsahovat několik variant morfologických značek. Taková nejednoznačnost není ve srovnatelných aplikacích obvyklá a v úvahách předchozích kapitol jsme s ní proto nepočítali. Jejím řešením se budeme podrobněji zabývat níže v této kapitole.
Morfologická značka je posloupnost velkých písmen a číslic (výjimečně může obsahovat i pomlčku), jejíž první písmeno udává slovní druh a na dalších místech jsou popsány mluvnické kategorie, případně poddruh slova. Jak je ovšem vidět z následujících tabulek, hodnoty značek lze pohodlně zakódovat do 4-bytových čísel, čímž se správa tabulky četností usnadní.
| Jméno kategorie | Jméno proměnné | Hodnota | Vysvětlení |
| slovní druh | k | N | podstatné jméno |
| A | přídavné jméno | ||
| P | zájmeno | ||
| C | číslovka | ||
| V | sloveso | ||
| O | příslovce | ||
| R | předložka | ||
| J | spojka | ||
| T | částice | ||
| I | citoslovce | ||
| Z | zvláštní (např. interpunkce) | ||
| X | nerozlišitelný | ||
| rod | g | M | mužský životný |
| I | mužský neživotný | ||
| F | ženský | ||
| N | střední | ||
| Y | M nebo I | ||
| T | I nebo F | ||
| W | I nebo N | ||
| H | F nebo N | ||
| Q | F nebo N ve zvláštních případech | ||
| Z | M, I nebo N | ||
| X | nerozlišitelný | ||
| číslo | n | S | jednotné |
| D | dvojné | ||
| P | množné | ||
| X | nerozlišitelné | ||
| pád | c | 1 až 7 | 1. až 7. |
| X | nerozlišitelný | ||
| stupeň | d | 1 až 3 | 1. až 3. |
| zápor | a | A | kladné |
| N | záporné | ||
| osoba | p | 1 až 3 | 1. až 3. |
| f | 1 až 2 | pouze 1. a 2. | |
| čas | t | P | přítomný |
| M | minulý | ||
| F | budoucí | ||
| slovesný rod | s | A | činný |
| P | trpný | ||
| způsob | m | N | oznamovací |
| R | rozkazovací | ||
| C | podmiňovací (jen některá slovesa) |
| Přípona | Vysvětlení |
| -1 | jiná varianta, méně častá |
| -2 | jiná varianta, velmi málo častá, archaická nebo knižní |
| -3 | velmi archaické, popř. hovorové |
| -5 | hovorové, tolerováno ve veřejném mluveném i psaném projevu |
| -6 | hovorové, většinou mluvené, nemělo by se používat ve veřejném projevu |
| -7 | hovorové, jako 6, ale méně preferováno mluvčími |
| -9 | zvláštní použití (např. po jistých předložkách) |
Některá písmena neurčují mluvnické kategorie, ale blíže specifikují
třídu slov v rámci slovního druhu.
| Značka | Vysvětlení, poznámka |
| Ngnca | podstatná jména (jen výjimečně a=N) |
| Agncda | přídavná jména |
| ACgn[c]a | jmenný tvar přídavného jména (rád, zdráv), pouze: ACYSa, ACQXa (za ACFSa, ACNPa nebo ACYS4a), ACNSa, ACMPa, ACTPa, ACFS4a |
| ASMgnc | přídavná jména přivlastňovací mužská (otcův) |
| ASFgnc | přídavná jména přivlastňovací ženská (matčin) |
| AVGgnca | přídavná jména slovesná přítomná (dělající) |
| AVVgnca | přídavná jména slovesná minulá (dodělavší) |
| A1gn | (svůj, nesvůj, tentam - jsou-li použita jako A) |
| PPfnc | zájmena osobní (já, ty) |
| PPfCnc | zájmena osobní zkrácená (mi, mě) |
| PP3gnc | zájmena osobní samostatná (on, ona, ono, jeho, jemu ) |
| PP3Cgnc | zájmena osobní zkrácená (ho, mu) |
| PP3Rgnc | zájmena osobní po předložce (něho) |
| PPD | zájmena osobní s předložkou (naň, proň) |
| PPA2S1 | zájmeno osobní se slovesem jsi (tys) |
| PRnc | zájmeno osobní zvratné samostatné (sebe, sobě) |
| PRCnc | zájmeno osobní zvratné zkrácené (se, si; n=X) |
| PRACncp | zájmeno osobní zvratné se slovesem jsi (ses, sis) |
| PSfngnc | zájmena přivlastňovací (můj, tvůj); první číslo je ˙vnitřní" (můj/náš), druhé ˙předmětné" (můj/moji) |
| PS3gngnc | zájmena přivlastňovací (jeho, její), první rod a číslo jsou vnitřní |
| PRSgnc | zájmeno přivlastňovací zvratné (svůj) |
| PDgnc | zájmena ukazovací (ten, tento, tamten) |
| PLgnc | zájmeno (sám, všechen) |
| PQFgnc | zájmena tázací nebo vztažná s rodem a číslem (jaký, který) |
| PQKgc | zájmena tázací nebo vztažná bez čísla (kdo, kdož; g=M) |
| PQCc | zájmena tázací nebo vztažná bez rodu a čísla (co) |
| PQD | zájmena tázací nebo vztažná s předložkou (nač, oč) |
| PQAcp | zájmena tázací nebo vztažná se slovesem jsi (kdos, cos) |
| PAEgnc | zájmena vztažná (jenž) |
| PAERgnc | zájmena vztažná po předložce (něhož) |
| PEc | zájmena vztažná bez rodu a čísla (což) |
| PSEgngnc | zájmena vztažná přivlastňovací (jehož) |
| PIFgnc | zájmena neurčitá (nějaký) |
| PIc | zájmena neurčitá bez rodu a čísla (něco) |
| PNFgnc | zájmena záporná (nijaký) |
| PNc | zájmena záporná bez rodu a čísla (nic) |
| CGgnc | číslovky základní (jeden, dva, tři, čtyři) |
| CBnc | číslovky základní bez rodu (pět a více) |
| CFgnc | číslovky - zlomky (g=F) |
| CRgnc | číslovky řadové (první, třetí, pátý) |
| CDgnc
CD1gnc CD2nc CDJnc |
číslovky druhové (dvojí, trojí, paterý) |
| CQFgnc | číslovky tázací nebo vztažné (kolikátý) |
| CQc | číslovky tázací bez rodu a čísla (kolik) |
| CIFgnc | číslovky neurčité (několikátý) |
| CIc | číslovky neurčité bez rodu a čísla (tolik) |
| CM | číslovky násobné (-krát) |
| CQM | číslovky násobné tázací (kolikrát) |
| CIM | číslovky násobné neurčité (několikrát) |
| CX | číslovky římské |
| VFa | slovesa, infinitiv (dělat) |
| VPnpa | slovesa, t=P (dělá) |
| VPEnpa | slovesa, t=P, s ˙neboť" (děláť) |
| VRgna | slovesa, t=M (dělal) |
| VREgna | slovesa, t=M, s ˙neboť" (dělalť) |
| VRAgnpa | slovesa, t=M, se ˙jsi" (dělals) |
| VSgn[c]a | slovesa, s=P (udělán) ), pouze: VSYSa, VSQXa (za VSFSa, VSNPa nebo VSYS4a), VSNSa, VSMPa, VSTPa, VSFS4a |
| VSAgnpa | slovesa, s=P, se ˙jsi" (uděláns) |
| VUnpa | slovesa, t=F (udělám) |
| VUEnpa | slovesa, t=F, s ˙neboť" (udělámť) |
| VMnpa | slovesa, m=R (dělej) |
| VCnp | slovesa, m=C (by) |
| VGnga | slovesa, přechodník, t=P (dělaje) |
| VVnga | slovesa, přechodník, t=M (dělav) |
| DGda | příslovce |
| DB | příslovce bez stupně a záporu |
| Rc | předložky |
| RVc | předložky s přidanou samohláskou (ke, ku) |
| RF | první část složeného předložkového výrazu (vzhledem) |
| JE | spojky souřadící, stejná úroveň koordinace |
| JC | spojky souřadící matematické (krát, děleno) |
| JS | spojky podřadící |
| JVnp | spojky podřadící slovesné (aby, kdyby) |
| T | částice (ano, ne, ať, kéž, nechť) |
| I | citoslovce |
| HYPH | první část složeného výrazu spojeného pomlčkou |
| ABBR[k] | zkratka daného slovního druhu |
| NOMORPH | neanalyzovaná slova, např. citace v cizím jazyku |
| ZNUM | číslo |
| ZIP | interpunkce |
| ZSB | identifikace věty (kořen stromu) |
Příklad: V trénovacích datech se vyskytne hrana s řídícím vrcholem
[solí, NFS7A|NFP2A|VPX3A] a závislým vrcholem [bílou, AFS41A|AFS71A]. Tato
hrana ve skutečnosti odpovídá právě jedné z kombinací NFS7A-AFS41A, NFS7A-AFS71A,
NFP2A-AFS41A, NFP2A-AFS71A, VPX3A-AFS41A a VPX3A-AFS71A. Místo abychom
zvýšili četnost některé hrany v tabulce o 1, zvýšíme četnost každé z uvedených
dvojic o ![]() .
.
Při větném rozboru pak budeme hledat pravděpodobnost, že se ve větě vyskytla některá z možných kombinací, tj. pravděpodobnost disjunkce jevů:
Poslední člen (pravděpodobnost průniku jevů) je nulový, jestliže se žádná kombinace značek nevyskytne v jedné hraně více než jednou. Ve skutečných datech sice k opakování značek dochází, avšak z důvodů, které pro naši úlohu nejsou relevantní. Proto postačí, když při čtení atributů vrcholu zaevidujeme každou značku nejvýše jednou. Potom se pravděpodobnost hrany bude rovnat součtu pravděpodobností jednotlivých kombinací.
Obdobně musíme postupovat i u hran, které tvoří kontext. Jestliže aktuální
hrana ![]() obsahuje kombinace
obsahuje kombinace ![]() až
až ![]() a kontext
a kontext ![]() obsahuje kombinace
obsahuje kombinace ![]() až
až ![]() ,
potom při trénování zaregistrujeme každou kombinaci z aktuální hrany postupně
v kontextu všech kombinací z kontextové hrany, vždy s četností
,
potom při trénování zaregistrujeme každou kombinaci z aktuální hrany postupně
v kontextu všech kombinací z kontextové hrany, vždy s četností ![]() .
.
Při analýze je situace komplikovanější. Pravděpodobnost hrany odhadujeme jako četnost dvojice ˙hrana plus kontext", dělenou četností kontextu:
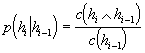
Protože dotyčné četnosti jsou součtem četností dílčích kombinací značek, dostáváme:
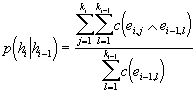
Z předchozího výkladu vysvítá, do jaké míry nejednoznačné morfologické značky komplikují algoritmus. Časová složitost se nebezpečně blíží prahu únosnosti zejména u dvougramového rozdělení, neboť pro každou hranu musíme projít všechny její kombinace spolu se všemi kombinacemi hrany z kontextu. Jelikož některá slova můžou obsahovat i 27 možných variant morfologické značky, může se nám stát, že zjištění jediné pravděpodobnosti si vyžádá přes půl miliónu přístupů do tabulky!
| Tabulka entropií | počet
hran |
počet
parametrů |
entropie | perplexita |
| unigram, T=50 |
|
|
|
|
| unigram, T=250 |
|
|
|
|
| unigram, T=1050 |
|
|
|
|
| bigram do hloubky, T=50 |
|
|
|
|
| bigram do hloubky, T=250 |
|
|
|
|
| bigram do hloubky, T=1050 |
|
|
||
| bigram do šířky, T=50 |
|
|
|
|
| bigram do šířky, T=250 |
|
|
|
|
| bigram do šířky, T=1050 |
|
|
Tabulka 2: Úspěšnost měřená podle značek. Za správnou závislostní
hranu se považuje taková, jejíž řídící i závislý vrchol mají stejnou značku
jako některá hrana původního stromu. Jestliže jeden nebo oba vrcholy připouštějí
více variant značek, započte se pouze poměrný počet správných hran, připadající
na správné kombinace značek. Takto zjištěná úspěšnost by měla být srovnatelná
s výsledky práce [[15]]. Hodnota T opět udává počet trénovacích
vět, Z je počet testovacích vět.
| Tabulka úspěšnosti měřené podle značek | T = 50
Z = 5 |
T = 250
Z = 25 |
T = 1050
Z = 100 |
| unigram, sekvenční algoritmus |
|
|
|
| unigram, komponentový algoritmus |
|
|
|
| bigram do hloubky |
|
|
|
| bigram do šířky |
|
|
|
Tabulka 3: Úspěšnost měřená podle slov. Za správnou hranu se
považuje taková, jejíž řídící i závislý vrchol reprezentují totéž slovo.
Pokud se ve větě vyskytlo stejné slovo dvakrát, musí odpovídat i pořadí
výskytu (slovosled). Takto zjištěná úspěšnost nemůže být vyšší než při
porovnávání značek. Lépe však vystihuje to, čím je naše snažení motivováno:
správnost rozboru vět.
| Tabulka úspěšnosti měřené podle slov | T = 50
Z = 5 |
T = 250
Z = 25 |
T = 1050
Z = 100 |
| unigram, sekvenční algoritmus |
|
|
|
| unigram, komponentový algoritmus |
|
|
|
| bigram do hloubky |
|
|
|
| bigram do šířky |
|
|
|
Tabulka 4: Křížová entropie. Čím vyšší hodnota byla zaznamenána,
tím větší počet prvků testovacích dat nebyl znám z dat trénovacích.
| Tabulka křížových entropií | T = 50
Z = 5 |
T = 250
Z = 25 |
T = 1050
Z = 100 |
| unigram |
|
|
|
| bigram do hloubky |
|
|
|
| bigram do šířky |
|
|
Překvapením je nižší úspěšnost bigramů ve srovnání s unigramy. Mohlo by to znamenat, že kontext hrany, tak jak jsme ho definovali, má příliš malý vliv na výskyt této hrany; do popředí pak vystupuje nevýhoda bigramu, spočívající v omezení nabídky hran v daném kroku jejich uspořádáním do posloupnosti.
Srovnáme-li úspěšnost pravděpodobnostního modelu s transformačním přístupem Kirila Ribarova [[15]], je naše metoda nejen horší než Ribarovovy konečné výsledky, ale, což je zarážející, nedosahuje ani úspěšnosti tzv. počátečního závorkování, tedy takového stromu, kde bez ohledu na obsah každé slovo závisí na svém předchůdci ve větě, pouze poslední slovo (obvykle tečka za větou) závisí opět na kořeni. Příslušný strom pak připomíná obrácenou jedničku: například věta ˙Lilo jako z konve." má zápis #(Lilo(jako(z(konve))),.).
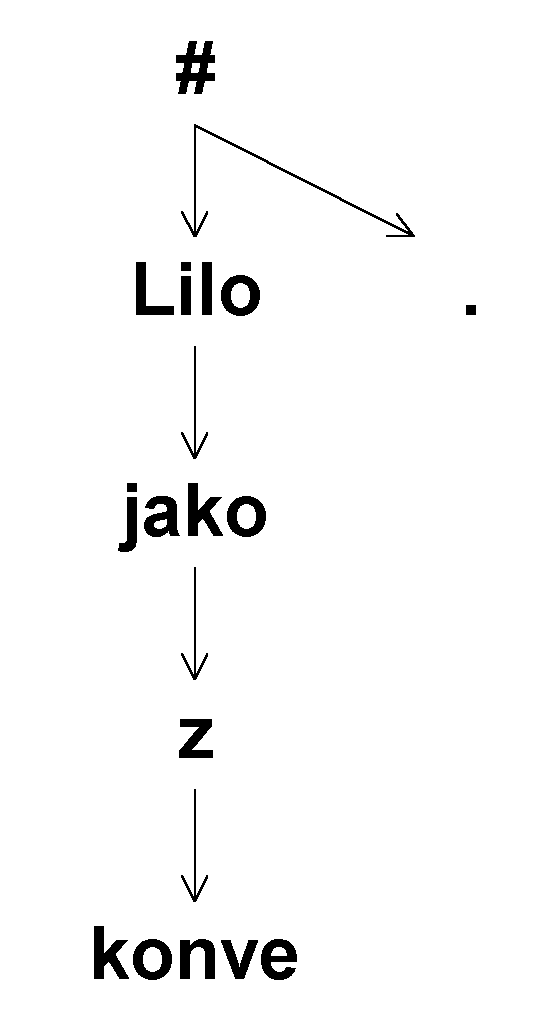
Jak ovšem vyplývá z následující tabulky, úspěšnost jedničkových stromů pro námi použitá data je výrazně nižší nejen oproti [[15]], ale nepřevyšuje ani úspěšnost pravděpodobnostního modelu.
Tabulka 5: Srovnání značkové úspěšnosti s jedničkovými stromy.
V prvním sloupci je úspěšnost počátečního závorkování podle [[15]], ve
druhém je tatáž hodnota naměřená na datech, z nichž vycházejí výsledky
předchozích tabulek. Ve třetím sloupci je nejlepší výsledek naší metody
a ve čtvrtém je nejlepší výsledek [[15]].
| Tabulka srovnání úspěšností s jedničkovými stromy | úz1R | úz1 | úz | úzR |
| Z = 5 |
|
|
||
| Z = 25 |
|
|
|
|
| Z = 100 |
|
Důležitá je otázka, zda se na chybovosti naší metody podílejí větší měrou ústupky, které jsme učinili při budování modelu, nebo nedokonalé hledání nejpravděpodobnějšího stromu (hladový algoritmus). Provedeme tedy ještě dvě další pozorování. Nejdříve zjistíme, zda ˙správné" stromy (tj. předlohy z testovacích dat) dostávají v daném modelu vyšší pravděpodobnost než námi vygenerované stromy chybné. A posléze se podíváme, zda se úspěšnost zvýší, když data pro testování přímo vybereme z trénovací množiny (nebude-li tomu tak, potom za chabé výsledky odpovídá hladový algoritmus).
Tabulka 6: Průměrný rozdíl mezi námi vygenerovaným stromem M
a předlohou z testovacích dat ![]() ,
resp. počátečním závorkováním
,
resp. počátečním závorkováním ![]() .
Rozdíl jsme definovali v kapitole Kapitola 4 : kladné číslo znamená, že
náš strom je pravděpodobnější. Čísla n a n0 resp.
n1 označují po řadě počet testovacích vět a počet případů,
kdy náš strom dostal vyšší pravděpodobnost než předloha, resp. počáteční
závorkování (jedničkový strom).
.
Rozdíl jsme definovali v kapitole Kapitola 4 : kladné číslo znamená, že
náš strom je pravděpodobnější. Čísla n a n0 resp.
n1 označují po řadě počet testovacích vět a počet případů,
kdy náš strom dostal vyšší pravděpodobnost než předloha, resp. počáteční
závorkování (jedničkový strom).
| Tabulka průměrných rozdílů stromů |
|
|
|
|
|
| unigram, T = 50 |
|
|
|
|
|
| unigram, T = 250 |
|
|
|
|
|
| unigram, T = 1050 |
|
|
|
|
|
| bigram do hloubky, T = 50 |
|
|
|
|
|
| bigram do šířky, T = 50 |
|
|
|
|
|
Tabulka 7: Výsledky testování na trénovacích datech. Za normálních
okolností nesmí testovací data být podmnožinou trénovacích, protože takový
test by nebyl objektivní. Nám jde však právě o to, srovnat výsledky trénovacích
dat s výše uvedenými testy.
| Tabulka výsledků testu na trénovacích datech |
|
|
|
| unigram, T = 50, Z = 5 |
|
|
|
| unigram, T = 250, Z = 25 |
|
|
|
| unigram, T = 1050, Z = 100 |
|
|
|
| bigram do hloubky, T = 50, Z = 5 |
|
|
|
| bigram do šířky, T = 50, Z = 5 |
|
|
|
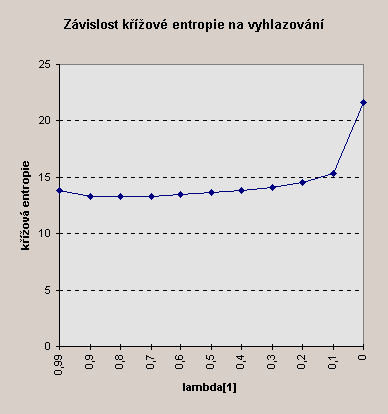
Tabulka 8: Posledním z ˙objasňovacích" experimentů jsme se pokusili
zjistit, zda problém nízké úspěšnosti netkví v tom, že vyhlazovací váhy
l jsme pouze odhadli. Pokus jsme provedli s jednogramovým modelem, natrénovaným
na 250 větách; jako obvykle jsme testovali vzorek 25 vět. Přitom jsme postupně
snižovali hodnotu ![]() a odpovídajícím
způsobem zvyšovali
a odpovídajícím
způsobem zvyšovali ![]() . Ukázalo
se, že hodnota tohoto parametru má jen minimální vliv na křížovou entropii;
na počet chyb neměla až do hodnot velmi blízkých nule vliv žádný. Z toho
vyplývá, že ani jemnější určení tohoto parametru (pomocí EM algoritmu -
viz kapitolu Kapitola 4 ) úspěšnost daného modelu nezlepší.
. Ukázalo
se, že hodnota tohoto parametru má jen minimální vliv na křížovou entropii;
na počet chyb neměla až do hodnot velmi blízkých nule vliv žádný. Z toho
vyplývá, že ani jemnější určení tohoto parametru (pomocí EM algoritmu -
viz kapitolu Kapitola 4 ) úspěšnost daného modelu nezlepší.
Toto zjištění ovšem neznamená, že musíme pravděpodobnostní přístup k syntaktické analýze zcela zavrhnout. Na naší cestě jsme provedli různá zjednodušení, dílem motivovaná snahou snížit časovou a prostorovou náročnost výpočtu, dílem vynucená právě množstvím a povahou dat. Shrňme tedy nakonec body, ve kterých vidíme možné zlepšení, a které by tudíž mohly být předmětem dalšího zkoumání. (Pořadí bodů nemusí nutně odpovídat jejich důležitosti.)
Použitý operační systém je MS-DOS verze 7.0, tj. Microsoft Windows 95 bez využití oken. Program volá pouze funkce ze standardní céčkové knihovny, dostupné i na Unixu, čímž se usnadní přenos na tento operační systém. Při přenosu na Unix je nutné zajistit (např. pomocí FTP), aby všechny soubory byly pojmenovány malými písmeny a aby dosovské konce řádků (CR LF) byly nahrazeny unixovými (LF). Soubor makefile je nutné přejmenovat na makedos a makeunix na makefile.
Zdrojový kód lze přeložit překladači Watcom C++ verze 10.5 a G++ (DJGPP) verze 2.0; použití jiných překladačů C++ nebylo vyzkoušeno. Soubor makefile s informacemi o celém projektu předpokládá použití GNU Make verze 3.73.
Přestože Unix i Windows 95 umožňují použití dlouhých jmen souboru, délka jmen v tomto projektu zůstává omezena na 8+3 znaky, protože GNU Make pro DOS ještě dlouhá jména nezvládá.
Veškeré komentáře ve zdrojovém kódu i v makefile a hlášení programu jsou v češtině a používají kódovou stránku Windows 1250 (Střední Evropa). Všechna hlášení, kterými program oblažuje uživatele (s výjimkou ladicích výpisů, které se v konečné verzi programu nepřekládají), jsou soustředěna ve dvou programových modulech, takže není problém z nich odstranit diakritiku nebo je lokalizovat do jiného jazyka. Na kódové stránce dat, se kterými program pracuje, nezáleží; je pouze třeba, aby vstup pro analýzu používal stejné kódování jako trénovací data. Texty přiložené k programu (z nich pocházejí výsledky naší práce) jsou kódovány podle unixového standardu ISO 8859-2 (Latin 2).
Zvláštní význam mají operandy začínající znakem '@'. Text, který následuje za tímto znakem, se považuje za jméno proměnné, resp. souboru s dalšími volbami a operandy. Zejména se tím zbavujeme problému s omezenou délkou příkazového řádku pod Dosem. Program se nejprve pokusí najít ve svém prostředí proměnnou daného jména, a pokud taková neexistuje, bude jméno považováno za jméno souboru. Jednotlivé volby a operandy jsou potom čteny z proměnné, resp. souboru, jako by se vyskytly přímo na příkazovém řádku. Po přečtení celého obsahu proměnné či souboru se program vrátí na příkazový řádek.
Implicitní nastavení je rozepsáno u jednotlivých voleb. Vlastní implicitní nastavení můžete určit obsahem proměnné SNTX v systémovém prostředí programu. Program naběhne se svým výchozím nastavením, potom přečte obsah proměnné SNTX a následovně čte zleva příkazový řádek. Jsou-li některá pozdější nastavení v konfliktu s předchozími, dostane přednost poslední přečtená hodnota.
-akce=akce
Základní volba, která určuje funkci programu. Výchozí nastavení této
volby je trenink.
Je-li akce=trenink, program si na základě již rozebraného textu vytvoří (˙natrénuje") jazykový model. Na vstupu se očekává soubor typu *.vzv se syntaktickými zápisy vět - viz popis formátu souborů. Na výstup pošle natrénované rozdělení pravděpodobností ve formátu *.rpr. Místo volby -akce=trenink lze použít zkratku FACE="Courier New">-al.
Je-li akce=analyza, program převádí nerozebrané věty na jejich syntaktické zápisy. Na vstupu se očekává soubor typu *.vet se syntakticky nerozebranými větami - viz popis formátu souborů. Na vstupu pro filtr (viz dále) se očekává soubor typu *.rpr, vzniklý při trénovací fázi. Na výstup se pošle soubor se syntaktickými zápisy vět ve formátu *.vzv. Místo volby -akce=analyza lze použít zkratku -aa.
Je-li akce=synteza, program převádí syntaktické zápisy vět zpět na nerozebrané věty, tj. odstraní syntaktickou strukturu. Můžeme tak získat např. testovací data: výstup syntézy předáme jako vstup do analýzy a její výstup porovnáme s původními vstupními daty. Na vstupu syntézy se očekává soubor typu *.vzv (viz popis formátu souborů), na výstup se pošle soubor ve formátu *.vet. Místo volby -akce=synteza lze použít zkratku -as.
Je-li akce=test, program otestuje natrénovaný jazykový model. Na vstupu očekává soubor typu *.vzv (viz popis formátu souborů), ze kterého odstraní syntaktickou strukturu (obdobně jako při syntéze), výsledek protáhne analýzou a její výstup porovná s původními vstupními daty. Na vstupu pro filtr přitom vyžaduje soubor typu *.rpr, vzniklý při trénovací fázi. Výsledek analýzy se uloží pouze do dočasného souboru a na výstup se místo něj pošle zpráva o výsledku srovnání (ve formátu obyčejného textového souboru - *.txt). Místo volby -akce=test lze použít zkratku -at.
-vstup=soubor
Udává jméno souboru, ze kterého se má číst vstup. Jaká data jsou očekávána
na vstupu, je popsáno výše u jednotlivých akcí. Je-li místo jména souboru
uveden znak '-', vstup programu se napojí na standardní vstup (stdin).
To je také výchozí nastavení. Místo volby -vstup lze použít zkratku -i.
-vystup=soubor
Udává jméno souboru, do kterého se má psát výstup. Jaká data se objeví
na výstupu, je popsáno výše u jednotlivých akcí. Je-li místo jména souboru
uveden znak '-', výstup programu se přesměruje na standardní výstup (stdout).
To je také výchozí nastavení. Místo volby -vystup lze použít zkratku -o.
-filtr=soubor
Udává jméno souboru, ze kterého se má číst ˙filtr", tedy soubor dat,
která blíže určují programem prováděnou akci. Jaká data jsou očekávána
ve filtru, je popsáno výše u jednotlivých akcí. Je-li místo jména souboru
uveden znak '-', filtr se přečte ze standardního vstupu (stdin). To je
také výchozí nastavení. Místo volby -filtr lze použít zkratku -f.
-hlaseni=soubor
Udává jméno souboru, do kterého se mají psát chybová hlášení a všechny
další zprávy, které nepatří do hlavního výstupu programu, jak je definován
u jednotlivých akcí. Tato volba má význam zejména pod Dosem, kde není možné
přesměrovat standardní chybový výstup. Je-li místo jména souboru uveden
znak '-', hlášení programu se přesměrují na standardní chybový výstup (stderr).
To je také výchozí nastavení. Místo volby -hlaseni lze použít zkratku -e.
-ovladani=soubor
Udává jméno souboru, ze kterého má být program ovládán. Zejména jsou
zde očekávány reakce na chybová hlášení. Je-li místo jména souboru uveden
znak '-', ovládací vstup programu se napojí na standardní vstup (stdin).
To je také výchozí nastavení. Místo volby -ovladani lze použít zkratku
-c.
-gram=n
Nastavuje velikost kontextu, na který se bere zřetel při trénování
modelu. Do kontextu právě přidávané hrany se zahrne n-1 předcházejících
hran. Při n=0 se bez ohledu na trénovací data vytvoří model s rovnoměrným
rozdělením pravděpodobností. Tato volba nemá žádný vliv při analýze a testování,
kdy se velikost kontextu zjišťuje z již natrénovaného rozdělení, předaného
jako filtr. Současná implementace některých částí programu nepočítá s gramem
vyšším než 2! Implicitní hodnota je 2 (bigram). Pro unigram a bigram lze
také použít zkratky -g1, resp. -g2.
-vahy=hodnota[:hodnota:
]
Definuje váhy pro vyhlazování. Jednotlivé hodnoty jsou odděleny dvojtečkami;
jako první se uvádí váha nejvíce-gramového rozdělení, jako poslední se
uvádí váha rovnoměrného rozdělení. Uživatel nese odpovědnost za to, že
počet vah bude odpovídat nastavení volby -gram, že jednotlivé váhy budou
ležet v intervalu ![]() a že
jejich součet bude 1. Celá a desetinná místa se oddělují tečkou, nikoli
čárkou. Výchozí nastavení vah je 0.99:0.009:0.001.
a že
jejich součet bude 1. Celá a desetinná místa se oddělují tečkou, nikoli
čárkou. Výchozí nastavení vah je 0.99:0.009:0.001.
-rozklad=metoda
Určuje, jakým způsobem se strom rozkládá na posloupnost hran, a tím
definuje uspořádání hran. Zvolená metoda ovlivňuje procházení stromu při
trénování (a tím i volbu hran, které tvoří kontext hrany právě přidávané)
a při analýze / testování (volba kontextu a vyloučení hran, které jsou
ve smyslu daného uspořádání ˙menší" než naposledy přidaná hrana). Výchozí
nastavení této volby je hloubka.
Je-li metoda=hloubka, hrany jsou uspořádány podle pořadí svého závislého vrcholu při procházení stromu do hloubky. (Procházení do hloubky: začne se v kořeni, potom se v každém kroku přednostně vezme první syn naposledy navštíveného uzlu. Nemá-li syny, vezme se bratr po jeho pravé straně. Pokud ani ten neexistuje, přejde se k otci aktuálního vrcholu, hledá se jeho pravý bratr atd.) Místo volby -rozklad=hloubka lze použít zkratku -rh.
Je-li metoda=sirka, hrany jsou uspořádány podle pořadí svého závislého vrcholu při procházení stromu do šířky. (Procházení do šířky: začne se v kořeni, potom se v každém kroku přednostně vezme pravý bratr nebo bratranec naposledy navštíveného uzlu. Pokud neexistuje, hledá se nejlevější uzel na další úrovni od kořene.) Místo volby -rozklad=sirka lze použít zkratku -rs.
Je-li metoda=libovolne, uspořádání hran není definováno a nelze říci, která hrana tvoří kontext ve vícegramovém modelu. Tato metoda má však smysl při současném nastavení -gram=1, protože pak při analýze není výběr hran omezen jejich uspořádáním. Místo volby -rozklad=libovolne lze použít zkratku -rl.
-budovani=metoda
Určuje, jakým způsobem se buduje strom při analýze. Výchozí nastavení
této volby je sekvencne.
Je-li metoda=sekvencne, použije se sekvenční hladový algoritmus (viz též kapitolu Kapitola 4 , část ˙Analýza"). Místo volby -budovani=sekvencne lze použít zkratku -bs.
Je-li metoda=komponentove, použije se komponentový hladový algoritmus (viz též kapitolu Kapitola 4 , část ˙Analýza"). Místo volby -budovani=komponentove lze použít zkratku -bk.
Je-li metoda=do_jednicky, úplně se vynechá pravděpodobnostní model a vybuduje se tzv. jedničkový strom (viz též kapitolu Kapitola 5 , část ˙Výsledky"). Místo volby -budovani=do_jednicky lze použít zkratku -bj.
-rozsah=[vynechat:]použít
Umožňuje použít pouze část dat ze vstupního souboru. Číslo vynechat
udává počet vět od začátku souboru, které se mají přeskočit bez provedení
zvolené akce. Číslo použít udává počet vět, s nimiž se má akce provést,
a jež bezprostředně následují za vynechanými.
-pouze_cist=ano|ne
Je-li nastaven tento přepínač, program pouze přečte vstupní data a
skončí. Lze tak zkontrolovat, zda vstupní soubor neobsahuje syntaktické
chyby (viz popis formátu souborů v příloze Příloha B). Implicitně je tato
volba vypnuta. Pokud je uvedena bez =ano nebo =ne, předpokládá se ˙ano".
-prepsat
-pripojit
Je-li při trénování zapnuta volba -prepsat, výstupní model se vytvoří
nově i v případě, že výstupní soubor už existuje. Dosavadní obsah výstupního
souboru se přemaže. Je-li zapnuta volba -pripojit, program nejdříve přečte
již existující rozdělení ze souboru, daného volbou -vystup, potom k němu
přidává další hrany z trénovacích dat a nakonec vše opět uloží do původního
souboru. Obě volby mají vliv pouze na trénink, ne na jiné akce. Výchozí
nastavení je -prepsat.
-pouze_tvary=ano|ne
Je-li nastaven tento přepínač, budou ve výstupním souboru typu *.vet
nebo *.vzv uvedeny pouze slovní tvary místo kompletního popisu vrcholu
v hranatých závorkách. Implicitně je tato volba vypnuta. Pokud je uvedena
bez =ano nebo =ne, předpokládá se ˙ano".
sntx -al -g1 -i=data\BL101JS.vzv -o=uni01.rpr
sntx -at -f=uni01.rpr -vahy=0.99:0.01 -rozklad=libovolne -i=data\BLD04EB.vzv -rozsah=5
sntx -aa -f=bis01.rpr -rs -i=BLD04EB.vzv -o=BLD04EB.vet
Každé přepisovací pravidlo se skládá z levé a pravé části. Levou část tvoří neterminál, který je pravidlem definován. Pravou část tvoří definice tohoto neterminálu. Může obsahovat jiné neterminály a/nebo skupiny terminálů, přičemž terminály vždy odpovídají znakům, očekávaným na vstupu. Místo neterminálů je na vstupu očekávána posloupnost terminálů, která z nich vznikne postupnou aplikací přepisovacích pravidel. Až sem je naše gramatika obyčejnou bezkontextovou gramatikou. Z praktických důvodů ovšem povolíme některá rozšíření, abychom si usnadnili zadávání gramatiky.
Především je častým jevem, že vstupní data mohou na různých místech obsahovat mezery, popřípadě též tabulátory, konce řádků apod., aniž by těmto znakům příslušel nějaký syntaktický význam. Kdybychom měli do gramatiky zahrnout mezery na všech místech, na kterých se mohou vyskytnout, gramatiku by to značně zesložitilo a znepřehlednilo. Proto definujeme dva druhy pravidel. První bude předpokládat, že mezi neterminály a skupinami terminálů na jeho pravé straně se může vyskytnout libovolný počet ˙mezer"; znaky, které se považují za mezeru, definujeme zvláštním neterminálem <mezera>. V pravidlech druhého typu mezery povoleny nebudou, pokud na jejich pravé straně nebude explicitně uveden tento zvláštní neterminál. Symboly na pravé straně pravidel typu 2 tedy musí na vstupu následovat bezprostředně za sebou. Všimněme si, že ani jeden druh pravidel neumožňuje implicitně vkládat mezery dovnitř do skupin terminálních symbolů.
Další usnadnění práce nám přinese povolení operátorů na pravé straně pravidel. Například operátor logické disjunkce nám umožní spojit dvě pravidla se stejnými levými stranami v jedno (viz níže). Operandem může být vždy buď neterminál, nebo skupina terminálů, nebo podvýraz uzavřený v závorkách. Nebude-li mezi dvěma operandy uveden žádný operátor, budeme implicitně dosazovat operátor nekomutativní logické konjunkce. To znamená, že na vstupu se očekávají oba operandy v pořadí, v jakém jsou uvedeny v pravidle. Operátory jsou uvedeny sestupně podle své priority.
::= Odděluje levou a pravou část pravidla typu 1 (s mezerami).
--> Odděluje levou a pravou část pravidla typu 2 (bez mezer).
< Ohraničuje zleva neterminální symbol.
> Ohraničuje zprava neterminální symbol.
" Ohraničuje zleva nebo zprava skupinu terminálních symbolů.
[ Ohraničuje zleva množinu znaků. Množina se může vyskytnout uvnitř skupiny terminálů a na jejím místě se na vstupu očekává právě jeden z jejích prvků. Prázdná množina označuje libovolný znak.
] Ohraničuje zprava množinu znaků.
- Uvnitř množiny nahrazuje všechny znaky, které mají kód vyšší než znak nalevo od něj a nižší než znak napravo. Není-li znak nalevo uveden, tvoří dolní hranici intervalu znak s nejnižším možným kódem. Není-li uveden znak napravo, tvoří horní hranici intervalu znak s nejvyšším možným kódem. Množina [-] je tedy rovna množině [].
! Volitelně rozděluje množinu znaků na část s povolenými znaky a část se zakázanými znaky. Místo množiny se na vstupu očekává libovolný znak, který je uveden před vykřičníkem a není uveden za ním. Vykřičník se také může vyskytnout mimo množinu znaků jako operátor (viz níže).
\ Uvozuje zápis zvláštního terminálního symbolu. Zvláštní terminální symboly jsou popsány níže. Vyskytne-li se zpětné lomítko v takové kombinaci s jiným znakem, jaká není níže popsána, považuje se tato kombinace za zápis obyčejného terminálního symbolu - znaku za lomítkem. Standardně se za terminální symbol považuje jeden znak a ten je také očekáván na vstupu.
\\ Zpětné lomítko jako terminální symbol, bez svého zvláštního významu.
\" Uvozovky jako terminální symbol, bez svého zvláštního významu.
\[ Levá hranatá závorka jako terminální symbol, bez svého zvláštního významu.
\] Pravá hranatá závorka jako prvek množiny, bez svého zvláštního významu.
\- Pomlčka jako prvek množiny, bez svého zvláštního významu.
\! Vykřičník bez svého zvláštního významu.
\t Tabulátor (TAB). Obvykle znak s kódem 9.
\r Návrat na začátek řádku (CR). Obvykle znak s kódem 13.
\n Konec řádku (LF). Obvykle znak s kódem 10.
( Ohraničuje zleva podvýraz, který má vystupovat jako samostatný operand nějakého operátoru. Závorky se používají pro změnu priority operátorů.
) Ohraničuje podvýraz zprava.
! Unární prefixový operátor. Smí se vyskytnout pouze před operandem, který reprezentuje jediný vstupní znak. Na vstupu je potom očekáván libovolný znak, na nějž se operand nemůže expandovat.
* Unární postfixový operátor. Jeho operand se na vstupu může opakovat n-krát, kde n ł 0.
+ Unární postfixový operátor. Jeho operand se na vstupu může opakovat n-krát, kde n ł 1.
? Unární postfixový operátor. Jeho operand se na vstupu může vyskytnout jednou nebo vůbec.
Mezera nebo prázdný znak mezi symboly jsou považovány za nekomutativní logickou konjunkci. Na vstupu se očekávají oba operandy v uvedeném pořadí.
& Operátor komutativní logické konjunkce. Na vstupu se očekávají oba operandy, ale v libovolném pořadí.
| Operátor logické disjunkce. Na vstupu se očekává právě jeden z jeho operandů.
<věta> ::= "(" <vrchol>+ ")"
<vrchol> ::= "\[" <heslo> "," <morfologická značka> "," <tvar> ("," <jiný atribut>)* "," <pořadí> "\]"
<heslo> ::= <varianta hesla> ("|" <varianta hesla>)*
<varianta hesla> ::= <atom>
<morfologická značka> ::= <varianta morfologické značky> ("|" <varianta morfologické značky>)* ("|" "...")?
<varianta morfologické značky> --> <znak v morfologické značce>*
<znak v morfologické značce> --> "[A-Z1-9\-]"
<tvar> ::= <atom>
<jiný atribut> --> <znak v první části jiného atributu>* <znak ve druhé části jiného atributu>* // má-li první část prefix "ord", musí se skončit, protože pak nejde o <jiný atribut>, ale o <pořadí>
<znak v první části jiného atributu> --> "[!=,\]]" | ("\\" "[=,\]]"?)
<znak ve druhé části jiného atributu> --> "[!,\]]" | ("\\" "[,\]]"?)
<pořadí> ::= "ord" "=" <číslo>
<atom> --> (<znak v atomu> | <zneškodněný oddělovač>)*
<znak v atomu> --> !("\\" | <oddělovač> | <mezera>)
<zneškodněný oddělovač> --> "\\" (<oddělovač>)?
<číslo> --> "[0123456789]"+
<oddělovač> --> "[=\|,\]]"
<zalomení řádku> --> "\\\r\n" | "\\\n"
<konec řádku> --> "\r\n" | "\n"
<mezera> --> "[ \t\r\n]" | <zalomení řádku>
<záhlaví> ::= <řádek záhlaví>*
<řádek záhlaví> ::= "@" ("[]" | <zalomení řádku>)* <konec řádku>
<strom> ::= <vrchol> "(" <seznam> ")"
<seznam> ::= <strom> ("," <strom>)*
<vrchol> ::= "\[" <heslo> "," <morfologická značka> "," <tvar> ("," <jiný atribut>)* "," <pořadí> "\]"
<heslo> ::= <varianta hesla> ("|" <varianta hesla>)*
<varianta hesla> ::= <atom>
<morfologická značka> ::= <varianta morfologické značky> ("|" <varianta morfologické značky>)* ("|" "...")?
<varianta morfologické značky> --> <znak v morfologické značce>*
<znak v morfologické značce> --> "[A-Z1-9\-]"
<tvar> ::= <atom>
<jiný atribut> --> <znak v první části jiného atributu>* <znak ve druhé části jiného atributu>* // má-li první část prefix "ord", musí se skončit, protože pak nejde o <jiný atribut>, ale o <pořadí>
<znak v první části jiného atributu> --> "[!=,\]]" | ("\\" "[=,\]]"?)
<znak ve druhé části jiného atributu> --> "[!,\]]" | ("\\" "[,\]]"?)
<pořadí> ::= "ord" "=" <číslo>
<atom> --> (<znak v atomu> | <zneškodněný oddělovač>)*
<znak v atomu> --> !("\\" | <oddělovač> | <mezera>)
<zneškodněný oddělovač> --> "\\" (<oddělovač>)?
<číslo> --> "[0123456789]"+
<oddělovač> --> "[=\|,\]]"
<zalomení řádku> --> "\\\r\n" | "\\\n"
<konec řádku> --> "\r\n" | "\n"
<mezera> --> "[ \t\r\n]" | <zalomení řádku>