



, konkrétně s daty pocházejícími z novin Wall Street Journal. Chtěli jsme si to udělat po svém (závislostně) a chtěli jsme to paralelně (angličtina i čeština).")


Obsah
Úvod
V následujícím textu popisujeme hlavní principy tektogramatické reprezentace platné pro angličtinu, užíváme anglické příklady. Rysy, které nejsou jazykově specifické pro angličtinu, však platí i pro českou tektogramatickou reprezentaci.
Co je tektogramatická rovina?
Tektogramatická anotace je vybudována nad analytickou rovinou. Podobně jako na analytické rovině jsou i při tektogramatické anotaci zachycovány syntaktické závislosti, tektogramatická anotace je však orientována více sémanticky a obsahuje mnohem více lingvistické informace. Základní myšlenkou tektogramatické reprezentace je zdůrazňovat podobnosti mezi jednotlivými jazyky a rozdíly mezi nimi zmírňovat. Tektogramatická reprezentace věty ve zdrojovém jazyce a její překlad do cílového jazyka se shodují mnohem více než dvě vzájemně si odpovídající analytické reprezentace, mnoho jazykově specifických rysů je totiž při tektogramatické reprezentaci přesunuto ze stromové struktury do vnitřní struktury uzlů.
Například věta 1600/32 v Penn Treebanku je velmi přesně přeložena do češtiny. Proto jde-li nám o sémantiku, měla by zdrojová i cílová věta být reprezentována podobným způsobem.
- [en] Mr. Carder also goes through periods when he buys stocks in conjunction with options to boost returns and protect against declines.
- [cs] Pan Carder má rovněž období, kdy kupuje akcie ve spojení s opcemi, aby zlepšil výnosy a zabránil poklesům.
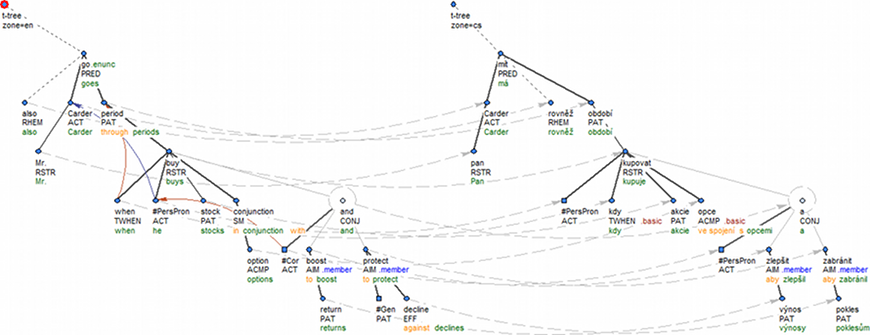
Obrázek 1
Překlad je přesný, nikoli však doslovný. V české větě není doslovně přeložen hlavní predikát (má neznamená goes through (zakoušet, prožívat), anglické klauzi to boost returns and protect against declines, která má funkci adverbiální účelové klauze, odpovídá v českém překladu závislá klauze s určitým slovesem, připojená spojkou aby. Jedná se o systematické rozdíly mezi češtinou a angličtinou. Tektogramatická reprezentace však tyto lexikální a strukturní rozdíly obsažené v původních textech smazává; srov. Obrázek 1. Na obrázku je například vidět, že aktanty a volná doplnění hlavního predikátu mají stejné sémantické značky, a to i přesto, že v jednom jazyce je přímý objekt, zatímco v druhém předložkový. Strukturní rozdíl mezi anglickou infinitivní klauzí a českou závislou klauzí s řídícím slovesem v určitém tvaru je také „skryt“, přesunul se ze stromové struktury do vnitřní struktury uzlů, je zachycen částečně rozdílnými hodnotami některých atributů a částečně jinou skladbou odkazů na nižší analytickou rovinu. Naproti tomu při analytické reprezentaci jsou všechny zmíněné rozdíly viditelné přímo ve stromových strukturách (Obrázek 2). Nejpodstatnější rozdíly mezi analytickou a tektogramatickou reprezentací jsou:
- V tektogramatickém stromě jsou uzlem reprezentována pouze plnovýznamová slova a souřadicí spojky. Lingvistická informace, kterou nesou funkční a pomocná slova, je zachycena ve vnitřní struktuře uzlů (viz sekce Struktura uzlu)
- Tektogramatická reprezentace zavádí t-lemma, které se odlišuje od morfologického lemmatu. Zejména v anglické části korpusu se však t-lemma stále ve většině případů shoduje se základní formou slova. Pro některé slovní druhy již bylo zavedeno t-lemma začínající #, a sice pro osobní a přivlastňovací zájmena a pro negační částice. Původní slovo je přítomno na nižších rovinách, na tektogramatické rovině je však zachyceno příslušným t-lemmatem a kombinací tzv. gramatémů (množina kognitivních a gramatických kategorií, více viz v sekci Gramatémy). Například zájmeno he má t-lemma #PersPron a gramatémy zachycující určitost, rod a číslo. Některá t-lemmata začínající # (nazýváme je zástupná t-lemmata) nereprezentují uzly přítomné na nižších rovinách, ale uzly přítomné pouze na tektogramatické rovině. Uzly, které neodpovídají žádným uzlům na nižších rovinách, jsou uzly přidané, doplněné. Přidané uzly mají buď zástupné t-lemma, nebo jsou kopií nějakého nepřidaného uzlu, který reprezentuje slovo obsažené v textu. Každý přidaný uzel má v atributu is_generated hodnotu "1".
- Uzly se do stromu přidávají především v případě zachycování elips a jsou buď kopií jiného uzlu reprezentující slovo obsažené v textu, nebo jde o uzly čistě umělé se zástupným t-lemmatem. To, zda přidaný uzel bude kopií jiného uzlu, nebo to bude uzel se zástupným t-lemmatem, záleží na typu elipsy a na pozici daného uzlu ve stromě. Kromě několika výjimek platí, že přidané neterminální uzly jsou kopiemi existujících uzlů s „obyčejným“ t-lemmatem a přidané terminální uzly mají zástupná t-lemmata.
- Každému výskytu slovesa je přiřazen valenční rámec z valenčního slovníku Engvallex. V případě, že v konkrétní větě nejsou vyjádřena všechna obligatorní valenční doplnění slovesa, jsou na pozice těchto doplnění do stromu přidány uzly se zástupnými t-lemmaty.
- Nejen slovesná doplnění, ale všechny tektogramatické uzly mají sémantické značky (funktory). Sémantické značky popisují syntakticko-sémantický vztah daného uzlu k jeho rodiči.
- Jsou zachyceny koreferenční vztahy, dokonce i mezi přidanými uzly.
- Úplná tektogramatická reprezentace obsahuje i anotaci aktuálního členění a hloubkového slovosledu. Pozor! V PCEDT 2.0 tato anotace obsažena není.
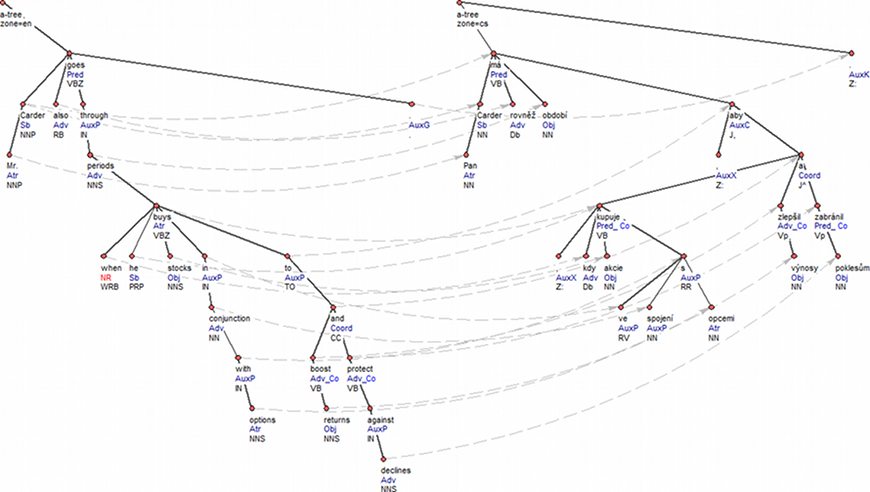
Obrázek 2